HttpRunner 【性能监控】HttpRunner 如何基于 Prometheus + Grafana 实现性能监控
前言
在 如何使用 HttpRunner v4.0 开展性能测试 中已经介绍过,HttpRunner v4.0 集成了 Prometheus 性能采集能力。也就是说,HttpRunner 可以充分将性能测试数据扩展到 Prometheus 生态,实现更丰富的数据应用场景,开展性能监控。
本文将会从 Prometheus 监控系统作为切入点,帮助大家快速理解 HttpRunner 性能监控链路,并提供快速上手帮助大家快速实现性能监控。
原理介绍
本节介绍 Prometheus 监控系统,帮助大家快速理解使用 HttpRunner v4.0 开展性能监控原理。
Prometheus 的系统架构图如下:
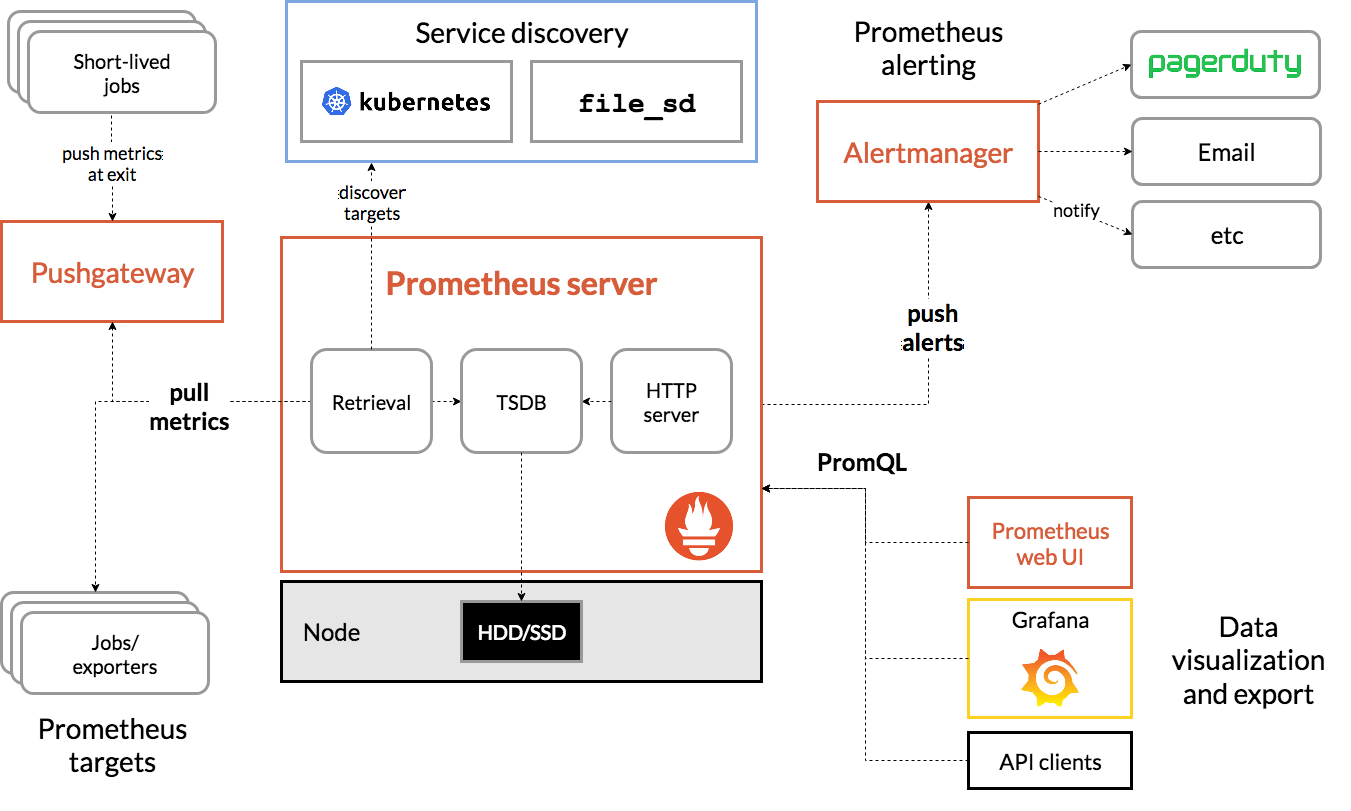
整个 Prometheus 系统框架主要包含四个部分:
- Server:提供指标汇总、存储、查询能力
- Exporter:提供指标采集能力
- Data Visualization:提供指标数据可视化能力
- Alerting:提供告警能力
如上可知,Prometheus 打通了从指标采集、汇总、存储、查询、可视化、告警链路,实现了完备的监控告警系统。针对 HttpRunner 性能监控场景,本文仅提供最小链路 Server、Exporter、Data Visualization 部分能力的快速上手,Alerting 等功能大家可以根据实际需求进行配置。
在 Prometheus 系统框架中,HttpRunner 实现了指标采集的能力,其本身就是一个 Exporter。因此,我们仅需要将指标上报至 Prometheus Server 链路打通即可实现性能监控。Prometheus 提供的两种指标收集方式:
- Exporter 会启动一个 http server,将采集的指标以固定的文本格式返回给请求方,Prometheus Server 直接拉取;
- 将指标直接 push 到 Prometheus 提供的数据网关 pushgateway 中,Prometheus Server 再从 pushgateway 中拉取指标数据。
两种方式中,HttpRunner 仅提供第二种方式的支持,即在使用 hrp boom 运行性能测试过程中主动 push 性能测试数据到 Pushgateway 的方式。这样做的原因有如下几点:
- 减少 Prometheus 侧的配置压力,避免 Exporter 的 IP 变化或在分布式压测场景下新增 Worker 后需要再次修改 Prometheus 的配置文件才能拉取到 Worker 数据的问题,理想情况是 Prometheus 侧对 Worker 数量是无感知的
- 更通用的应用场景,比如当 Server 部署在公网,而 Exporter 部署在内网等场景下,可避免公网环境不能访问到内网的情况
- 避免每个 Worker 启动一个 Http Server 带来端口占用问题以及暴露网络端口的安全风险
基于第二种方式,Prometheus Server 端仅需从 Pushgateway 上实时拉取到最新的性能测试数据,并将数据汇总存储在本地的时序数据库中即可。到此,我们可以通过 PromQL 语句在 Prometheus Web UI 上对指标进行聚合查询了,也可以在 Grafana 中使用更丰富生动的面板进行数据可视化(推荐)。
整个监控链路可简化为:

快速上手
本节将介绍如何从零搭建 Prometheus 服务,打通性能监控链路,帮助大家能快速上手。
配置 Prometheus
在官网 Download | Prometheus 下载 prometheus 与 pushgateway,并进行如下配置。
Pushgateway
Pushgateway 不需要修改任何配置文件,直接运行可执行文件即可启动,默认端口号为 9091,如需更改端口号,需启动时指定。启动 Pushgateway:
./pushgateway --web.listen-address=":9091"
Prometheus Server
启动 Server 前需要手动更改 prometheus.yml 配置文件,明确拉取指标的实例地址(本案例中的 Pushgateway 地址)与 Server 拉取 Pushgateway 实例的时间间隔( scrape_interval ),具体更改如下:
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # Evaluate rules every 15 seconds.
# Attach these extra labels to all timeseries collected by this Prometheus instance.
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules.yml'
scrape_configs:
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'pushgateway' # metrics_path defaults to '/metrics' # scheme defaults to 'http'.
scrape_interval: 3s
static_configs:
- targets: ['localhost:9091']
labels:
instance: httprunner
注意:Pushgateway 的 scrape_interval 需要与 HttpRunner 上报指数据频率保持一致,即设置为 3s。
启动 Prometheus Server:
./prometheus --config.file=prometheus.yml
配置 HttpRunner
配置 HttpRunner 就比较简单了,在使用 hrp boom 启动性能测试时通过 prometheus-gateway 参数设置 Pushgateway 地址即可,如 --prometheus-gateway=":9091"。在性能过程中,HttpRunner 会以 3s 的数据上报间隔将性能测试指标上报到 Pushgateway。
配置 Grafana
Grafana 的快速上手可以参考:Grafana | Prometheus ,不再赘述。
本文提供 hrp boom 单机模式的 Dashboard 模板,大家在 HttpRunner 公众号回复「Grafana」获取模板下载地址,然后导入 Grafana 中即可使用。
注:分布式场景的 Grafana Dashboard 模板,待 HttpRunner 上线分布式性能测试能力后再提供。

模板最终效果如下:
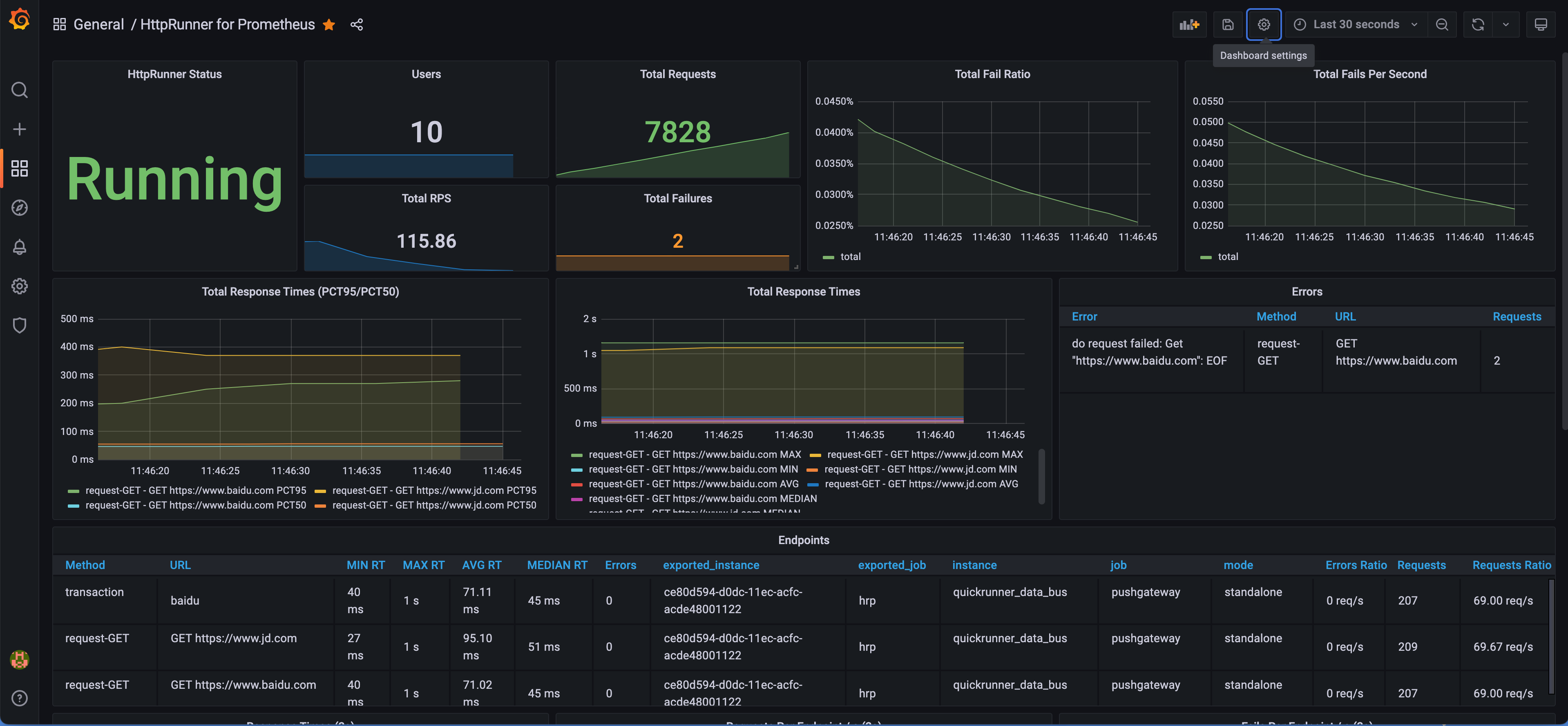
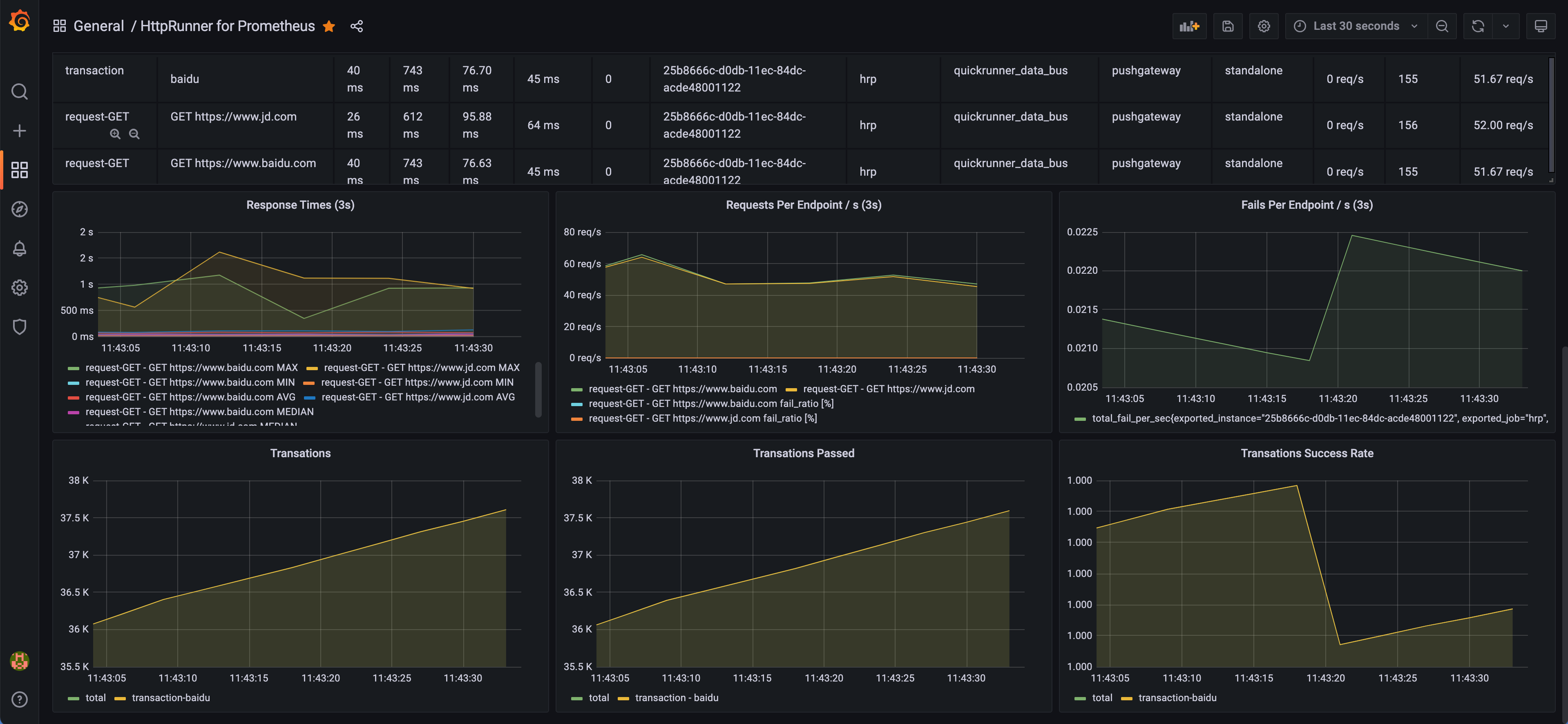
指标说明
本节将介绍 HttpRunner 上报的指标说明,大家可以根据需要再丰富本文提供的 Grafana Dashboard 模板。
HttpRunner 上报至 Prometheus 指标具体可分为两大类:
- 3s 统计间隔内的性能测试指标,可实时监控最新性能数据详情
- 整体性能测试指标,可实时监控测试过程的整体性能指标
指标名称与具体说明如下:
| 指标名称 | 指标说明 | 指标类型 | 标签 | 统计间隔 |
|---|---|---|---|---|
| num_requests | The number of requests | GaugeVec | name、method | 3s |
| num_failures | The number of failures | GaugeVec | name、method | 3s |
| median_response_time | The median response time | GaugeVec | name、method | 3s |
| average_response_time | The average response time | GaugeVec | name、method | 3s |
| min_response_time | The min response time | GaugeVec | name、method | 3s |
| max_response_time | The max response time | GaugeVec | name、method | 3s |
| average_content_length | The average content length | GaugeVec | name、method | 3s |
| current_rps | The current requests per second | GaugeVec | name、method | 3s |
| current_fail_per_sec | The current failure number per second | GaugeVec | name、method | 3s |
| total_num_requests | The number of requests in total | CounterVec | method、name | total |
| total_num_failures | The number of failures in total | CounterVec | method、name | total |
| errors | The errors of load testing | CounterVec | method、name、error | total |
| response_time | The summary of response time(PCT50/PCT90/PCT95) | SummaryVec | name、method | total |
| users | The current number of users | Gauge | N/A | total |
| state | The current runner state, 1=initializing, 2=spawning, 3=running, 4=quitting, 5=stopped | Gauge | N/A | total |
| duration | The duration of load testing | Gauge | N/A | total |
| total_average_response_time | The average response time in total milliseconds | Gauge | N/A | total |
| total_min_response_time | The min response time in total milliseconds | GaugeVec | name、method | total |
| total_max_response_time | The max response time in total milliseconds | GaugeVec | name、method | total |
| total_rps | The requests per second in total | Gauge | N/A | total |
| fail_ratio | The ratio of request failures in total | Gauge | N/A | total |
| total_fail_per_sec | The failure number per second in total | Gauge | N/A | total |
| transactions_passed | The accumulated number of passed transactions | Gauge | N/A | total |
| transactions_failed | The accumulated number of failed transactions | Gauge | N/A | total |
结语
通过以上内容,相信大家对 HttpRunner v4.0 的性能监控链路有了一个整体认识,我们可以使用 HttpRunner v4.0 在开展性能测试的同时进行性能监控,欢迎大家多多实践。
接下来,我们将连载介绍 HttpRunner v4.0 的更多性能测试功能特性,敬请期待。
本文作者:xucong053,HttpRunner 核心开发者,重点建设了性能测试相关能力
HttpRunner 项目官网: https://httprunner.com/
如果 HttpRunner 对你有过帮助,麻烦帮忙给个 ⭐️star⭐️ 鼓励下吧
https://github.com/httprunner/httprunner
