
在实时互动无处不在的今天,视频质量是反映终端用户体验的重要指标。单纯依赖人工实施大规模的实时评估是不现实的,因此视频质量自动化评估体系的搭建与推广是大势所趋。
然而如何评价视频质量?不同的关注点可能会带来不同的答案。对于各类直播的终端用户来说,关注的侧重点是实时的质量监控;对于提供视频技术服务的从业人员来说,关注的则是视频算法版本之间细粒度的提升或回退。因此,我们需要一套 “评价主观视频质量体验” 的客观指标,一方面作为客户端的体验评价或故障检测,另一方面作为从业人员的算法优化性能参考。我们把这一评价体系叫做 VQA(Video Quality Assessment)。
这个问题的难点,一是如何收集数据,即如何量化人对视频质量的主观评价,二是如何建立模型,使该模型能够取代人工评分。
在接下来的内容中,会先梳理业界一般的评估方法,再介绍声网的 Agora-VQA 模型建立过程,最后总结未来的改进方向。
业界如何实现视频质量评估?
与深度学习领域其他算法一样,建立视频质量评估模型也可以分为两步:收集 VQA 数据、训练 VQA 模型。整个 VQA 训练的过程通过客观模型对主观标注的模拟来实现,拟合效果的好坏由一致性评价指标来定义。主观的 VQA 标注以分级评分的方式收集终端用户反馈,旨在量化真实用户的视频体验;客观 VQA 则提供了模仿主观质量分级的数学模型。
主观:VQA 数据收集
主观评价由观察者对视频质量进行主观评分, 可以分为 MOS(Mean Opinion Score) 和 DMOS(Differential Mean Opinion Score) 两种。MOS 描述的是视频的绝对评价,属于无参考场景,直接量化海量 UGC 视频的质量。DMOS 则表示视频的相对评价,属于有参考场景,一般是在相同内容下比较视频之间的差异。
本文我们主要介绍 MOS,ITU-T Rec BT.500 给出的操作范例保证了主观实验的信度和效度。将主观的视频感受投射到 [1,5] 的区间内,描述如下:
分数 体验 描述
5 Excellent 体验很好
4 Good 可感知,但不影响(体验)
3 Fair 轻微的影响
2 Poor 有影响
1 Bad 非常影响
这里需要详细解释两个问题:
1、如何形成 MOS?
ITU-T Rec BT.500 给出的建议是 “成立≥15 人的非专家组”,得到评分员对视频的标注后,先计算每个人和总体均值的相关性,剔除相关性较低的评分员后,再对剩余评分员的评价求均值。当参与评分的人数大于 15 时,足以将实验随机误差控制在可接受范围内。
2、如何解读 MOS?MOS 能在多大程度上代表 “我” 的意见?
虽然不同的评分员对于 “好” 和 “坏” 的绝对区间定义,或者是对画质损伤的敏感程度都不尽相同。但是对 “较好” 和 “较差” 的判断还是趋同的。事实上,在例如 Waterloo QoE Database 等公开数据库中,std 均值可达到 0.7,说明不同的评分员的主观感受可以相差近 1 个档位。
客观:VQA 模型建立
VQA 工具的分类方法有非常多,按照原始参考视频提供信息的多少,可以将 VQA 工具分为三大类:
Full Reference 全参考
依赖于完整的原始视频序列作为参考标准,基于逐像素的 PSNR 和 SSIM 就是最原始的比较方法,缺点是和主观的拟合程度有限,Netflix 推出的 VMAF 指标也在此列。
Reduced Reference 半参考
比较的对象是(原始视频序列和接收端视频序列的)某些对应特征,适用于完整的原始视频序列不可得的情况,这类方法介于 Full Reference 和 No Reference 之间。
No Reference 无参考
No Reference(以下简称 “NR”)的方法进一步解除了对附加信息的依赖,更加 “就事论事” 地评价当前视频。受到线上数据监控方式的限制,实际场景下参考视频通常是无法获取的。常见的 NR 指标有 DIIVINE、BRISQUE、BLIINDS 和 NIQE 等,由于参考视频的缺失,这些方法的精度与全参考、半参考相比往往略逊一筹。
主客观一致性评价指标
前文说到,基于像素的 PSNR 和 SSIM 方法和主观的拟合程度有限,那么我们是如何判定各类 VQA 工具好坏的呢?
业内通常从客观模型的预测精度和预测单调性给出定义。预测精度描述了客观模型对主观评价的线性预测能力,相关的指标是 PLCC(Pearson Linear Correlation Coefficient) 和 RMSE(Root Mean Square Error)。预测单调性描述了评分相对等级的一致性,衡量的指标是 SROCC(Spearman Rank Correlation Coefficient)。
Agora-VQA 如何实现视频质量评估?
不过,多数公开数据集从数据量大小、视频内容丰富度来看都还不足以反映真实线上情况。所以为了更贴近真实的数据特征,覆盖不同 RTE(实时互动)场景,我们建立了 Agora-VQA Dataset,并在此基础上训练了 Agora-VQA Model。这是业内首个可运行于移动设备端的基于深度学习的视频主观体验 MOS 评估模型。它利用深度学习算法实现对 RTE(实时互动)场景接收端视频画质主观体验 MOS 分的估计,解除了传统主观画质评估对人力的高度依赖,从而极大提高视频画质评估的效率,使线上视频质量的实时评估成为可能。
主观:Agora-VQA Dataset
我们建立了一个画质主观评估数据库,并参照 ITU 标准搭建了一套打分系统收集主观打分,然后进行数据清洗,最后得到视频的主观体验得分 MOS,总体流程如下图所示:

在视频整理阶段,首先我们考虑在同一批的打分素材中做到视频内容本身的来源丰富,避免评分员的视觉疲劳;其次,在画质区间上尽量分布均衡,下图为某一期视频收集到的打分分布:
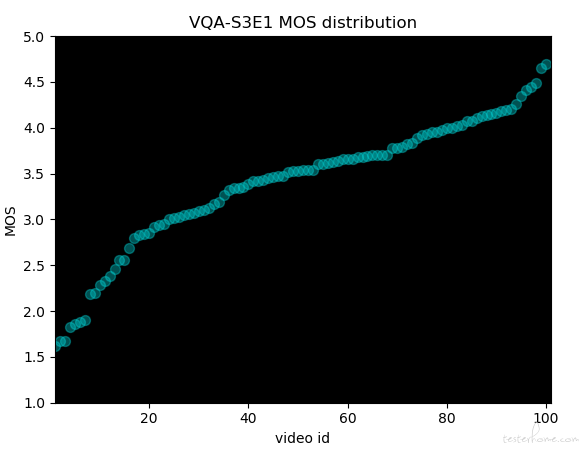
在主观打分阶段,我们搭建了一个打分 app,每条视频长度在 4-8s,每批次收集 100 条视频打分,对于每一个评分员来说,观看总时长控制在 30min 以内,避免疲劳。
最后,在数据清洗阶段,有两种可选方案。其一依照 ITU 标准:先计算每个人和总体均值的相关性,剔除相关性较低的评分员后,再对剩余评分员的评价求均值。其二是通过计算每个样本的 95% 置信区间,选择打分一致性最高的视频作为金标准,筛选掉在这些样本上打分偏差较大的参与者。
客观:Agora-VQA Model
一方面为了更贴近用户的实际主观感受,另一方面是由于在视频直播及其类似场景中参考视频是无法获取的,因此我们的方案是将客观 VQA 定义为接收端的解码分辨率上的无参考评价工具,用深度学习的方法监控解码端视频质量。
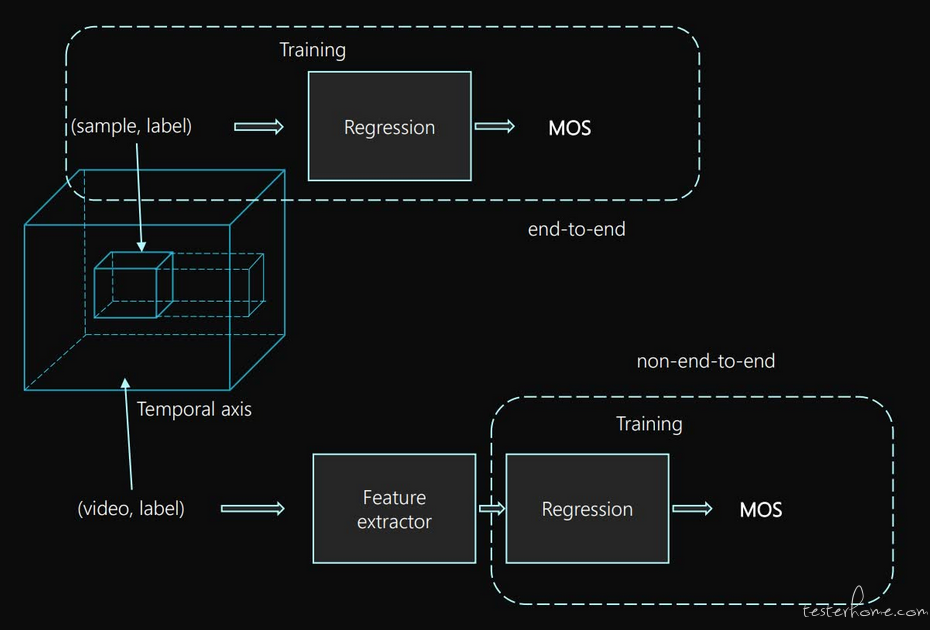
训练深度学习模型可以分为端到端与非端到端。在端到端的训练方式中,由于视频的时空分辨率不同,要采样到统一大小进行端到端的训练;对于非端到端,首先通过一个预训练的网络提取特征,然后对视频特征进行回归训练拟合 MOS。
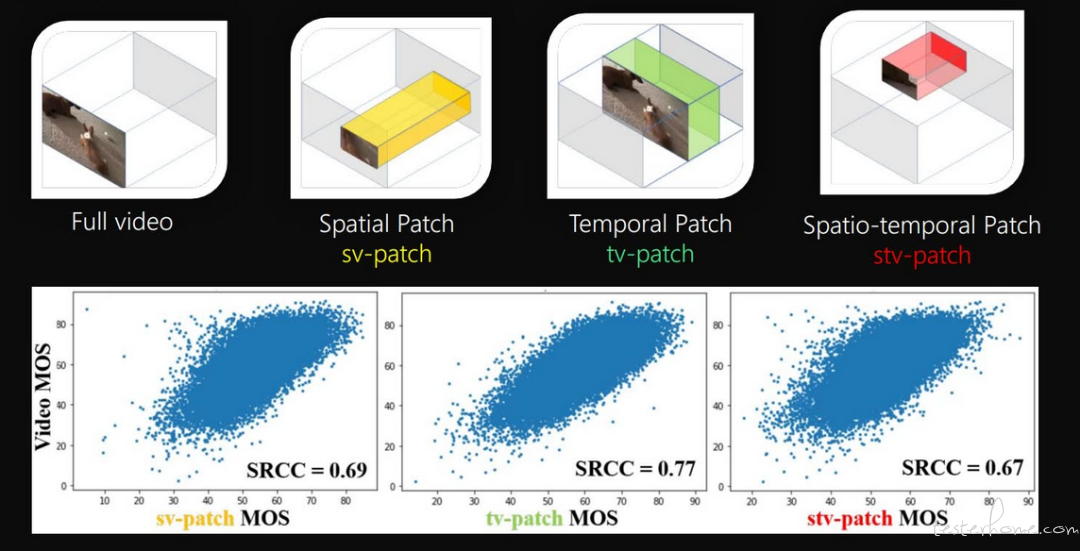
在特征提取部分,对原始视频有不同的采样方式,下图(引用论文 [1] 中插图)显示的是不同的采样方式与主观的相关性,可以看出视频空间上的采样对性能的影响最大,而进行时域上的采样与原视频的 MOS 相关性最高。
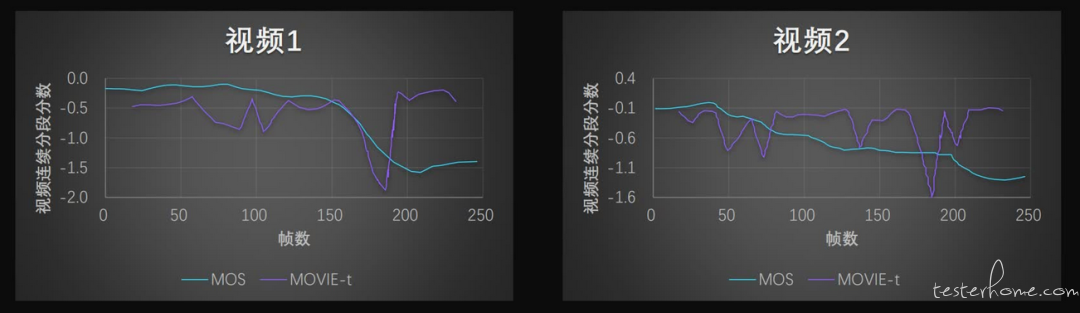
影响画质体验的不光是空域的特征,时域上的失真也会有影响,其中有一个时域滞后效应(参考论文 [2])。该效应对应着两个行为:一是视频画质下降时主观体验立即降低,二是视频画质提升时观看者体验的缓慢提升。我们在建模时也考虑了这种现象。
与其它 VQA 工具的性能比较
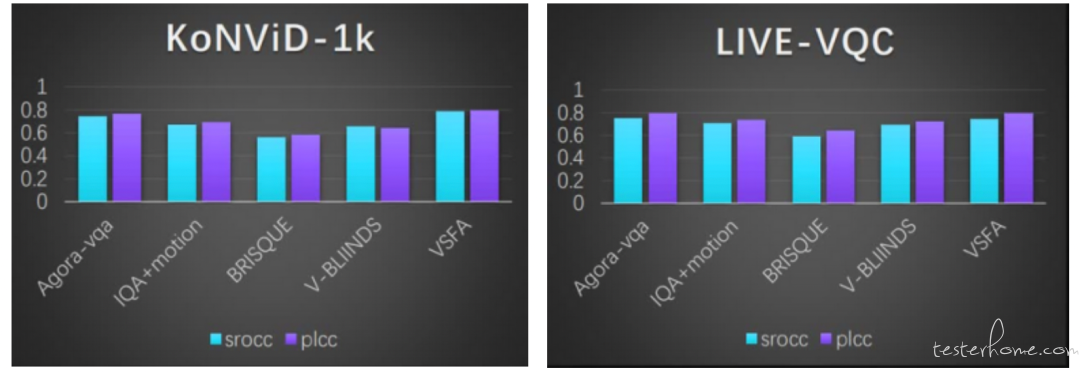
最后来看不同画质评估算法在 KonViD-1k 和 LIVE-VQC 上的相关性表现:
模型的参数量和运算量对比:
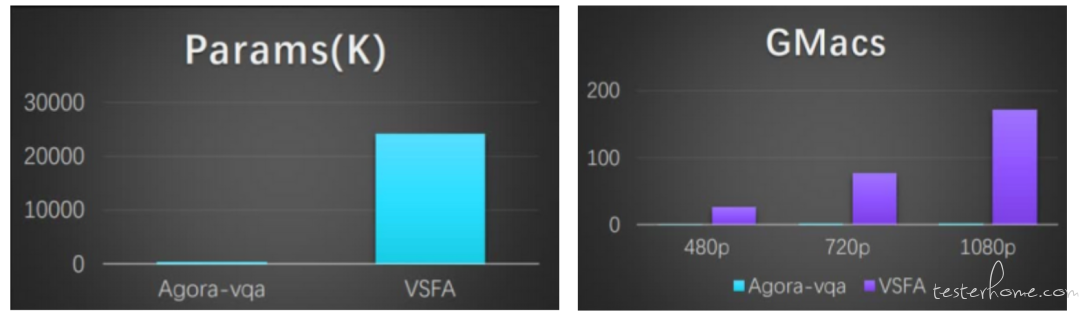
可以看出 Agora-VQA 相对于学术界基于深度学习的大模型有着很大的运算优势,而这种优势赋予了我们在端上直接评估视频通讯服务体验的可能性,在提供一定准确率保障情况下,大大提升了运算资源的节省。
展望
最后,距离达到最终的 QoE(Quality of Experience),即刻画用户主观体验的目标,Agora-VQA 还有很长的路要走:
1)从解码分辨率到渲染分辨率
解码分辨率的概念是相对于渲染分辨率的,已知视频在不同的设备播放,或者在同一设备上、以不同的窗口尺寸拉伸都会造成主观体验的差异。当前 Agora-VQA 评估的是解码端视频流的质量,在下一阶段我们计划支持不同的设备和不同的拉伸尺寸,更加贴近终端用户感知质量,实现 “所看即所得”。
2)从视频片段到整段通话
用于模型训练的 VQA 数据集,多由时长为 4~10s 不等的视频片段组成,而实际通话中需考虑近因效应,仅通过对视频片段线性追踪、打点上报的方式,或许无法准确拟合用户的主观感受,下一步我们计划综合考虑清晰度、流畅度、互动延时、音画同步等,形成时变的体验评价方法。
3)从体验得分到故障分类
当前 Agora-VQA 能够实现在区间 [1,5] 内,精确到 0.1 的视频质量预测,而当视频质量较差时,自动定位故障原因也是实现线上质量普查的重要环节,因此我们计划在现有模型基础上支持故障检测功能。
4)从实时评估到行业标准化
目前 Agora-VQA 已在内部系统迭代打磨中,后续将逐渐开放,未来计划同步在 SDK 集成在线评估功能,并发布离线测评工具。
以上是我们在 VQA 方面的研究与实践,欢迎大家点击「阅读原文」在开发者社区发帖与我们交流。
参考文献
[1] Z. Ying, M. Mandal, D. Ghadiyaram and A. Bovik, "Patch-VQ: ‘Patching Up’ the Video Quality Problem," 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 14014-14024.
[2] K. Seshadrinathan and A. C. Bovik, "Temporal hysteresis model of time varying subjective video quality," 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 2011, pp. 1153-1156.
Dev for Dev 专栏介绍
Dev for Dev(Developer for Developer)是声网 Agora 与 RTC 开发者社区共同发起的开发者互动创新实践活动。透过工程师视角的技术分享、交流碰撞、项目共建等多种形式,汇聚开发者的力量,挖掘和传递最具价值的技术内容和项目,全面释放技术的创造力。