AI测试 智能测试实践之路-UI 缺陷检测
作者 | 邹军、袁肇飞、唐文博
背景
随着业务与技术的发展,软件架构从最初单体结构逐步演变成 AI 赋能的分布式体系,基础框架技术能力不断成熟,数据、控制、服务等能力的深化为业务的快速建立与扩展提供了强大的支撑能力。与此同时,测试技术由被测体的业务与技术变革所牵引,从瀑布式跟进服务端单体的纵向测试能力建设发展到敏捷化的端到端全链路测试,尤其强化了精析测试能力的作用。质量保障过程从点面支撑进化到立体保障,复杂度从服务端向移动端迁移。
移动端的测试模式可大体分为代码侵入方式与非代码侵入方式。代码侵入方式,以集成 SDK 或系统底层 Hook 方式为主,通过采集系统基础资源指标、收集日志信息、触发或反馈执行动作、调用或收集接口调用信息等方式,支持测试路径与结果验证。作为各大厂商的测试技术落地的主要方式,通过后向监控与单点查询等方式对业务测试起了很重要的作用。非代码侵入模式,以用户视角来探索测试边界,强调产品功能与体验,界面信息即是输入也是输出。由于缺少代码和日志信息的辅助,相对弱化测试路径的设计与目的性,强化用户交互逻辑。技术上或通过 UIAutomator/WDA 与 GUITree 控件树来实现定位与判决,或通过图像智能识别来实现分类、遍历与异常检测。
Test By AI 作为测试技术的新方向,已经逐步成为国内外大型互联网公司和测试服务提供商的研究方向。通过智能化手段增强测试路径生产能力、测试数据特征诊断能力,以及测试断言的准确性,是共同探索与实践的方向。其中,在图形化界面上,基于计算机视觉识别能力构建 UI 的功能录制回放、设计还原、性能诊断与线上巡检已慢慢有所沉淀,有代表性的平台包括 Test.AI、Applitool、Mabl 、AirTest、AppiumPro、Fastbot、SmartX、RXT、DevEco Studio、PerfDog、GameAISDK 等。
痛点
对于大型的 APP 而言,往往承载了公司触达用户的大量业务类型,通过前中后台数以万计的服务链条支撑,而高 DAU 多类型设备覆盖的用户场景成为产研测质量控制的挑战。代码后向兼容、模块依赖、数据一致性、业务策略重叠等,都可能引起功用户侧的系统问题,比如空白屏、空白块、文字重叠截断、图文遮挡、字符乱码、货币符号错误、兜底图文缺失等。问题列表:
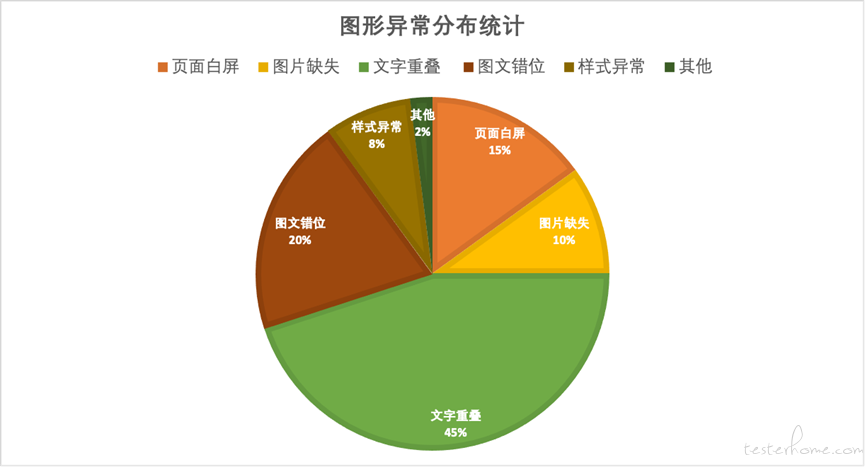
图一:典型问题分布图
实践之可行性调研
研测阶段关注点在业务功能实现层面,人工甄别上述问题的成本非常高且容易形成疲劳遗漏,智能化在研测阶段和线上监控上识别此类问题正是 Test By AI 的切入点。在智能化切入目的性测试领域前,从结果诊断逻辑上探索异常巡检的落地技术实践是一种有效方式。
从实现方案上,有多种可能:
一、基于 GUITree 控件的节点信息,来判断节点是否存在,节点属性是否正确,以此来匹配到功能或者业务逻辑上,比如出现图片加载失败,网络加载超时,价格缺失,商品描述缺失等。但是,无法判断纯图形类型的问题,比如文字重叠、图文错位等。
二、基于图形的特征比对,判断两张图片的相似度。CV 现有成熟的算法有 SIFT、SURF、ORB 等,但特征比对的逻辑是预判,事前知道错误图形的类型,且要与错误图形库逐一比对判断,计算资源与耗时随着问题类型的增加线性增长。
三、基于模型训练,通过深度学习对训练集中的大量数据进行特征提取,达到一次性的类别与阈值判决,以此作为测试结果判定的主要手段。同时,辅助二次检验的手段来提高判决的准确率。
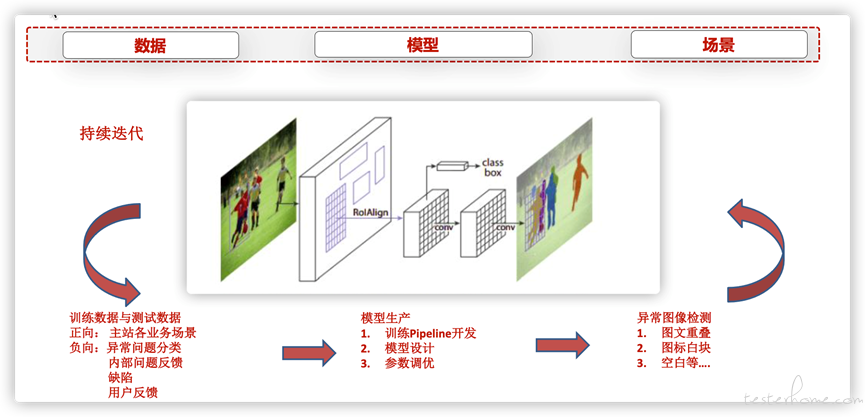
图二:图像训练与检测逻辑图
通过 AI 建设智能测试基础能力,核心在于数据与模型,再者是在业务域的工程落地实践。从数据上来看,我们需要建立主站 app 各类页面的遍历能力,以便实现业务域场景的覆盖。依托现有测试遍历技术和自动化测试能力,可以实现周期性遍历页面,跟进业务迭代引入的主站 app 端变化。同时,将探索式遍历、脚本业务域遍历与赛博云真机平台融合,可以保障兼容性覆盖与效率提升。这样,我们可以实现正向样本数据的收集。
另外,负向图像样本的收集也极为重要。由于缺陷、异常问题反馈的图像数据相对较少,难以覆盖所有的异常场景,所以需要按照发现问题的图像特点,以正向训练集来批量地构建各种错误类型的负向样本,作为负向训练集和测试集,以提供给模型训练与效果验证。
异常构建能力建设
为了提供负向样本,我们必须建立异常图像特征的构建能力。这里,将以图片缺失、文字重叠等场景来举例说明异常构建的技术方案。
图片缺失
图片缺失会出现在多种场景中,比如,首页商品图片加载整体失败、活动页/搜索结果页/购物车/结算页图片缺失、带顶栏空白页、广告位动图缺失等。这些场景从技术维度都可以归结为异常白块。从 CV 的角度构建,可先找出页面中的图片元素。对图片进行二值化处理,然后根据确认元素轮廓,在原有的图片像素点上定位,用白色填充矩形区域。对于边界区分度不高的图片,可加入膨胀、或腐蚀的图形化处理。
图示中蓝色框中图片会被白块所依次取代:
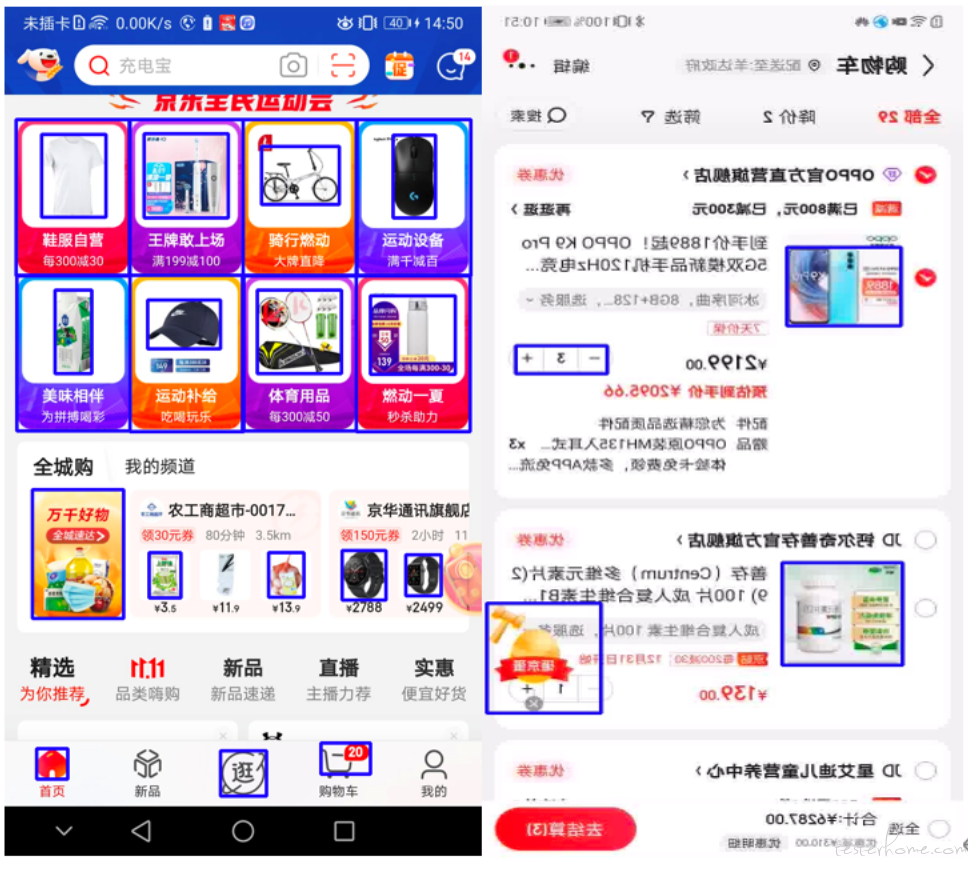
文字重叠
文字重叠异常在整体异常占比是最高的,发生的场景存在于 APP 的各个角落,这一块我们力求把异常样本构造的更贴近真实样本,保证最终训练模型识别的准确度。
我们在一个正常的截图上说明构建的方法:

挑选一个文字区域,通过 ocr 结合 CV 的方法确认文字区域,获取 “京东会员” 文字区域坐标集合,利用该集合在原图上获取文字的背景和颜色,计算字号,再通过图形处理能力构造相关文字的重叠,最终效果如下图

通过如上方法,我们构建了文字重叠异常的数据集,异常图片量级达到万级以上,并且基本不用投入人力。
算法开发实践
在 UI 测试过程,异常图片种类繁多、不同缺陷的表现形式多样,且不同页面的样式、排版经常发生变化,传统的 CV 算法(如模版匹配、滤波等)难以实现逐个缺陷判定。因此,采用深度学习(DeepLearning)的方法成为优选方案。
深度学习算法开发一般分为以下步骤:
开发环境搭建
样本数据准备
网络结构设计
模型训练与测试
算法迭代优化
开发环境搭建
首先,确认采用 Local 方式,还是 Online 的方式。Local 的方式,需要准备带有 GPU 的机器、安装显卡驱动及深度学习框架相关软件包;Online 模式,一般适用于大厂,如 AWS、JD Cloud 都提供相关的租赁服务。大家可以根据自身情况选择,根据实时性、灵活性的要求,选择开发语言,目前主流的开发语言为 Python、C++ 等。
样本数据准备
样本数据是整个工作最基础、最重要的一环。数据质量的好坏决定算法模型性能的优劣。根据经验判断,构建优质的样本数据集,包括数据搜集、数据整理、数据去噪声、数据构造、数据增强、数据迭代等步骤,大致需要花费整个实践工程 70% 甚至 80% 的时间。本项目实践的任务属于有监督训练学习,搜集的样本数据集包括图片和其对应的 label。智能测试过程最常见的两类异常缺陷为空白块异常和文字重叠异常;我们设定没有异常缺陷的样本为正常样本(标记为-1),每类异常情况标注不同的 label(空白块异常标记 0,文字重叠异常标记为 1)。
对于图像分类任务,每张图片对应于某个类别(正常、空白块、文字重叠);对于目标检测任务,每张图片对应于多个目标的检测框,每个检测框同时包含类别信息和位置信息。我们将本实践中的异常检测问题定义为目标检测问题,不仅标注出缺陷的类别信息,同时标注出缺陷的具体位置。我们从已标注的样本集中随机抽取 10 条目的展示结果,如下图所示:
最左边一列代表随机抽取样本的 index,后面依次是 image_path,class_label,defect_pos, xyhw。
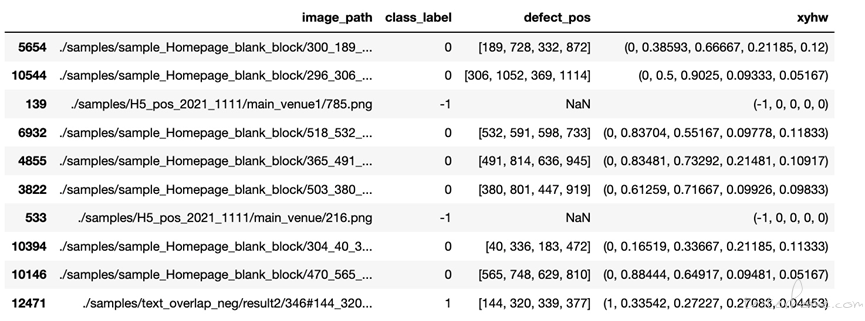
图:随机抽取的 10 条标注样本示例图
其中,image_path 为图片的存储路径,class_label 为异常缺陷的类型,defect_pos 为异常缺陷在图像中的坐标位置(x1,y1,x2,y2),xyhw 为缺陷位置的相对坐标(这样即使图片发生了 resize,缺陷坐标保持不变)和缺陷的类型。正常样本在 class_label 中记为 NaN,在目标检测标注中记为(-1,0,0,0,0)。
网络结构设计
在图像领域,目前深度学习网络结构主要有两大主流框架,即 CNN 和 Transformer。在此,我们仅介绍基于 CNN 的网络结构模型的相关探索实践。Transformer 目前在学术领域属于热议阶段,但其对数据量级、硬件资源等要求都非常高,其落地实践情况仍在持续探索中。
从 ImageNet 1000 类图像分类 Top5 错误率的历年趋势图可以看出,Top5 的错误率逐年明显下降,其后甚至低于人类自身错误率 5.1%。
自 2012 年起,网络结构从最初的 AlexNet,逐渐演变到 VGG,GoogleNet,Resnet 等。在本项目实践中,我们采用带有 SELayer 的 Resnet18 结构,整体结构如下图所示:
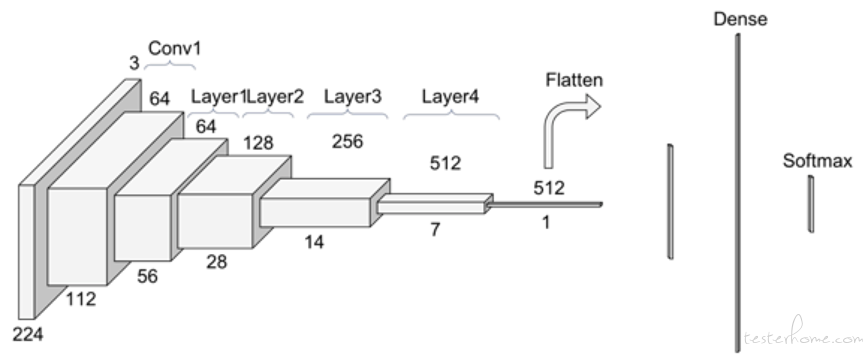
图:带有 SELayer 的 Restnet18 网络结构图
模型训练与测试
在完成样本整理和网络结构设计后,接下来进入模型训练的阶段。首先,将样本集划分为训练集和测试集,并设置必要的超参数(如训练轮次 epoch、学习率 learning_rate、批次样本数目 batch_size 等);然后,定义损失函数 Loss,在实践的初期阶段,我们将异常检测视为分类问题,所以完成 softmax 层计算后,采用 CrossEntropy 来进行梯度反传。
测试样本和真实样本的 ROC 曲线图如下所示:

图:测试样本和真实样本的 ROC 曲线图
算法迭代优化
我们提取 Restnet18 的 Layer4,构建了特征热力图,如下图所示。分析热力图发现,缺陷在空白块处响应最大,说明缺陷的特征已被分类器准确学习到。
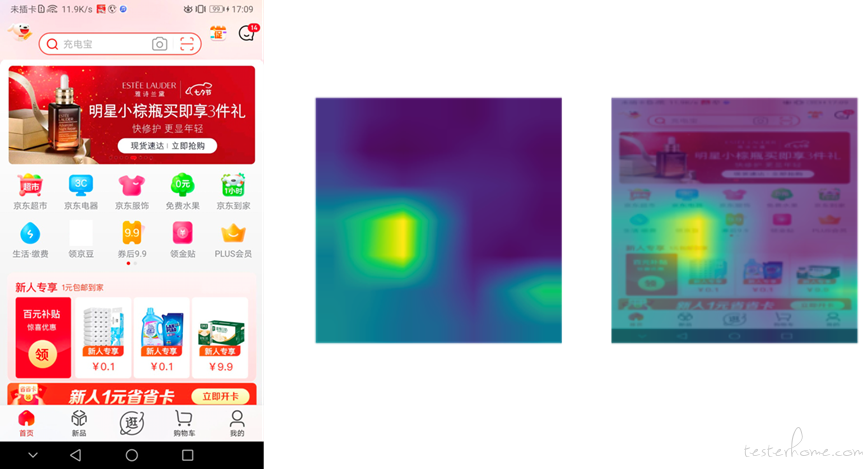
图:模型检测结果的热力图
● Bad Case 分析:
Case 1: 算法模型判定为正常,标注为异常的样本,如图(a)所示。经过二次 check 后,确认为标注错误。因此,识别 “算法模型得分较高而与真实标注信息不一致” 的样本,可作为快速去噪的有效方法。
Case 2:模型未识别出来的异常空白块,分析原因发现目前的训练样本集中没有 “粉色底” 的空白块。在后续样本采集的过程中,可持续增强此类样本的搜集。
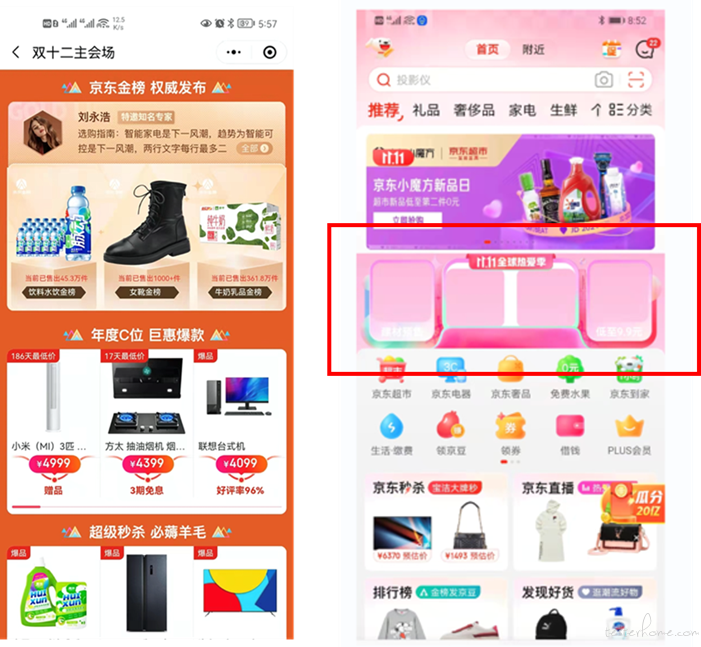
(a)模型发现的标注错误 (b)样本集缺失的 “粉色底” 空白块
图:Bad Case 分析样例图
真实样本的匮乏构成算法实践探索的最大壁垒。我们尝试了多种方式去尽可能搜集完备的样本集:其一,人工构建异常样本,此类方式的构建步骤繁琐,人力成本耗费较大且某些异常情况无法人工构造;其二,采用无监督学习的方式构建样本,该方式通过大量正样本的学习来识别异常样本,此类方式能节约大量的人工标注时间和成本,非常值得进一步探究,也将成为后续我们重要的研究方向。
未来规划
从现有的客户反馈问题和研测问题为切入点,我们在算法效果上取得一个不错的结果,以此作为开端,继续深化 Test By AI 的智能化之路。在算法上,从数据清洗、模型设计等维度继续优化模型效果,同时开始无监督学习算法能力的尝试。在工程上,以现有能力为基础,加强二重检测能力的建设,保障业务测试实践的效果。在实践上,总结 badcase、提炼针对性的算法和工程技术点,增强 AI 判决的效果。结合 AI,提升测试路径生产能力、测试数据特征诊断能力,以及测试断言的准确性,同样会变成智能化探索的重要一环。