背景
在春节假期追了一个电视剧"完美伴侣",女神"高圆圆"领衔主演,大概有 45 集,给我的感觉整体剧情还行,女神演技和颜值依然在线.
大概的剧情介绍:
陈珊是一家著名律所证券部的女律师,近40岁的她遭遇上升瓶颈。因此她全身心投入工作,根本无暇顾及丈夫和女儿的情感需求。
丈夫孙磊在一家国企工作,为了支持老婆的事业,承担了照顾家庭的重任,几乎放弃了自己的事业追求。这女强男弱的婚姻模式近十年来从运转良好,到渐渐失去平衡,不知不觉中已不堪重负。此时投行精英林庆昆出现,他手中的大单,成为陈珊和竞争对手们争夺的目标。
面对婚姻和职场双重危机,陈珊拼命努力试图同时处理好两者,却越来越适得其反。孙磊和陈珊经历了重重考验后,
最终发现他们对彼此的初心还在,不完美的他们,只要好好珍惜,共同扶持,就是彼此最完美的伴侣。
当时这部剧有的地方也很狗血,有赞的、也有骂的.想通过网友的评论分析一波.
数据来源
在豆瓣上能找到几千条评论,应该爬下来够用了.
豆瓣地址
https://movie.douban.com/subject/35196566/
查看请求
抓看看看数据接口和数据格式

数据格式
在 h5 页面上,一条评论由头像、评分、评语组成.
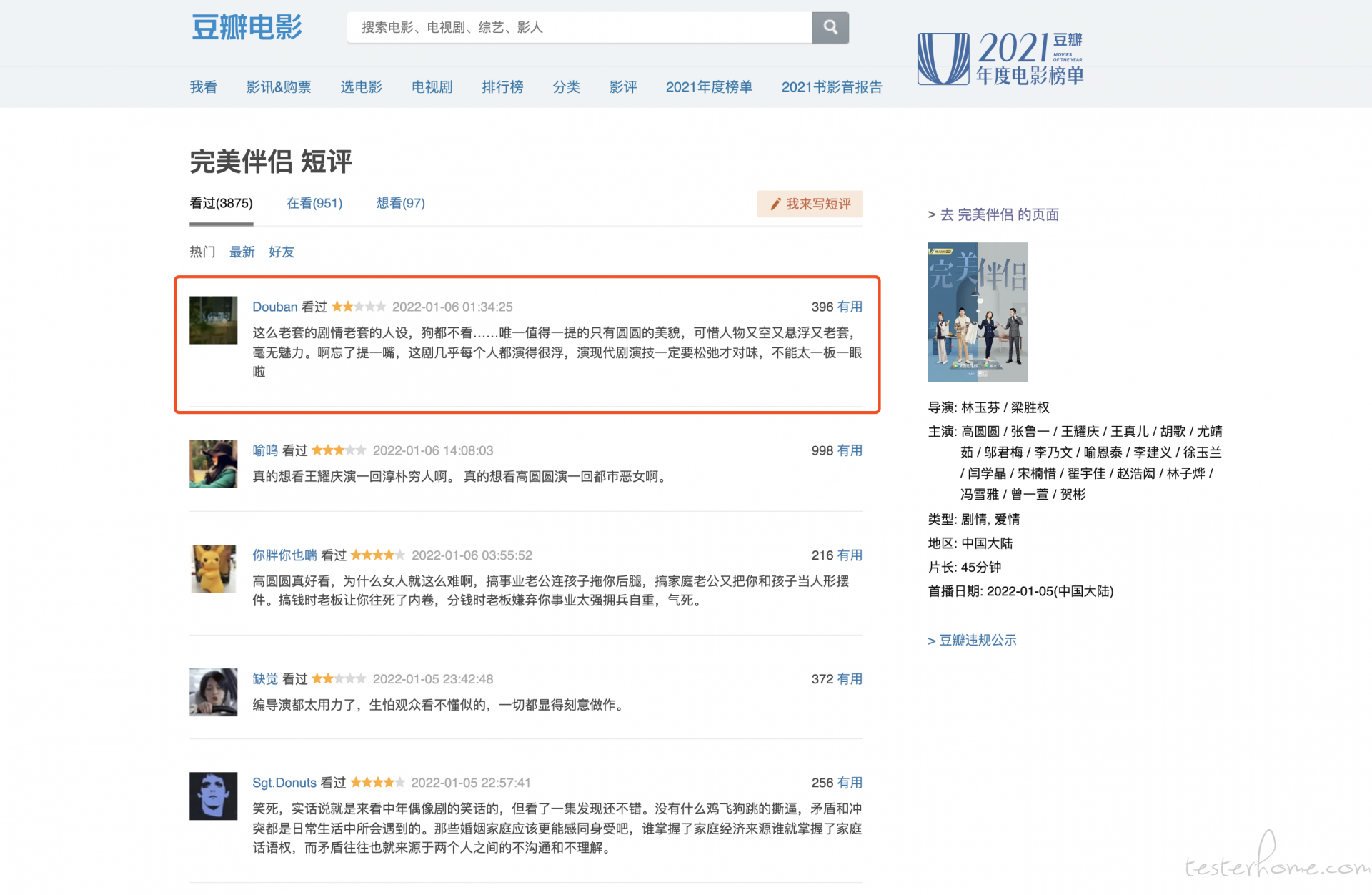
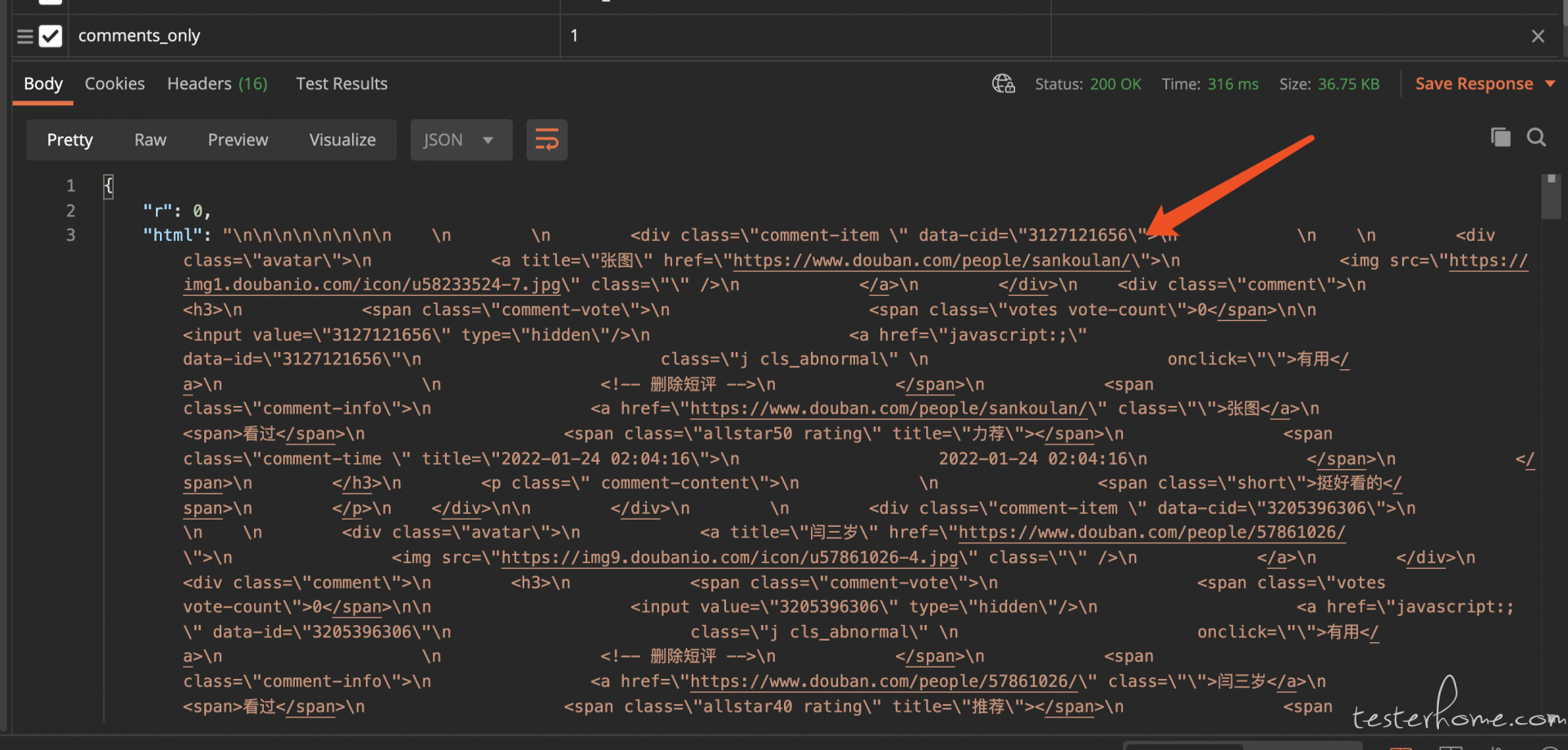
在查看返回数据并不是返回一个标准的 kv 结构数据,而是一坨 html 结构,然后前端再去渲染.
复制 curl
复制 curl 的目的是,方便通过 postman 调试脚本
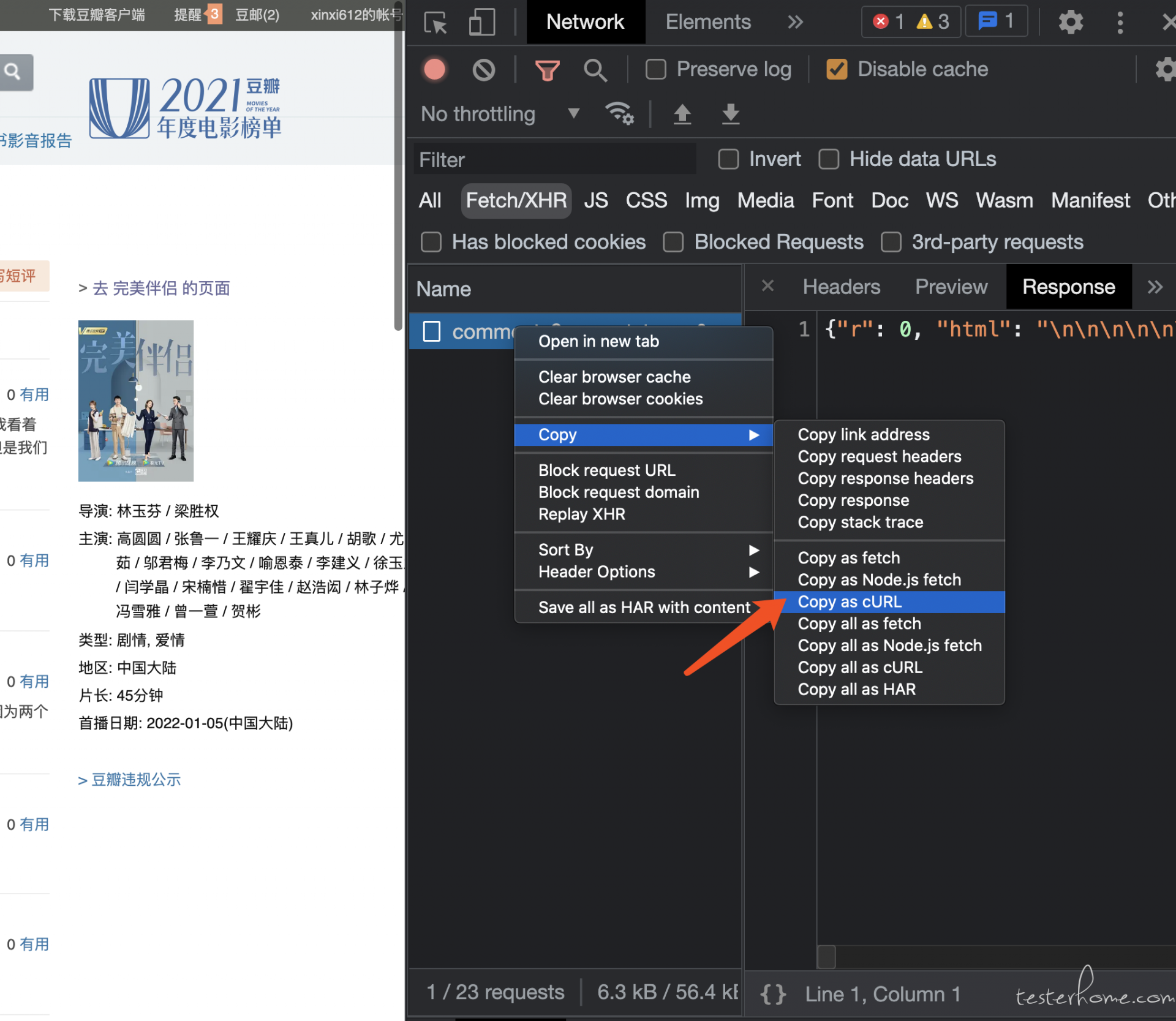
使用 header
复用 header 头在脚本获取数据
脚本编写
依赖库
源: https://pypi.doubanio.com/simple
pip3 install jieba (分词)
pip3 install httpx (发送网络请求)
pip3 install logzero (日志)
pip3 install beautifulsoup4 (解析html)
pip3 install wordcloud (生成词云)
pip3 install pyecharts (生成图表)
循环获取评论,通过 start 的数量来查询数据,通过 BeautifulSoup 获取对应的 span 标签数据,最终获取 class="short"就是评语
@staticmethod
def get_info_by_comments():
"""
获取评论
:return:
"""
Page_INDEX = 0
START_INDEX = 0
IS_RUNNING = True
while IS_RUNNING:
url = HOST + "/subject/35196566/comments?percent_type=&start={}&limit=20&status=P&sort=new_score&comments_only=1".format(
START_INDEX)
START_INDEX = START_INDEX + 20
Page_INDEX = Page_INDEX + 1
logger.info(url)
r = httpx.get(url, headers=headers, timeout=10)
if 'html' in r.text:
html = r.json()['html']
soup = BeautifulSoup(html, 'html.parser')
for k in soup.find_all('span'):
if 'class="short"' in str(k):
comment = str(k.string).encode()
CommentsList.append(comment)
write_content_to_file(FilePath, comment, is_cover=False)
write_content_to_file(FilePath, "\n".encode(), is_cover=False)
time.sleep(1)
else:
IS_RUNNING = False
获取评论
使用脚本把评论离线存在本地的文件中,方便后续分析.
根据评论生成的词云
生成词云脚本
with open(CommentsFilePath, 'r') as f:
r_info = f.readlines()
sentence = ''.join(r_info)
# 用jieba将句子分词
font_path = "/System/Library/fonts/PingFang.ttc"
word = jieba.cut(sentence)
words = " ".join(word)
# 生成图片的nd-array,传入图片路径
im = imageio.imread('test.jpeg')
wc = wordcloud.WordCloud(width=600, height=800, background_color='white', font_path=font_path, mask=im,
contour_width=1, contour_color='black')
wc.generate(words)
wc.to_file('wc.png')
这里会用到 jieba 进行分词,wordcloud 通过分词后的数量生成词云.

获取评分
还想看看评分的分布是怎么样的
获取评分的脚本如下:
if 'html' in r.text:
html = r.json()['html']
soup = BeautifulSoup(html, 'html.parser')
for k in soup.find_all('span'):
if k.get('class') != None:
# 查找评分
if 'allstar' in str(k.get('class')):
title = str(k.get('title')).encode()
通过 pyecharts 生成评分饼图
with open(STARFilePath, 'r') as f:
r_info = f.readlines()
JIAOCHA = 0
HAIXING = 0
TUIJIAN = 0
HENCHA = 0
LIJIAN = 0
QITA = 0
for i in r_info:
STAR = i.replace("\n", "")
if STAR == "较差":
JIAOCHA = JIAOCHA + 1
elif STAR == "还行":
HAIXING = HAIXING + 1
elif STAR == "推荐":
TUIJIAN = TUIJIAN + 1
elif STAR == "很差":
HENCHA = HENCHA + 1
elif STAR == "力荐":
LIJIAN = LIJIAN + 1
else:
QITA = QITA + 1
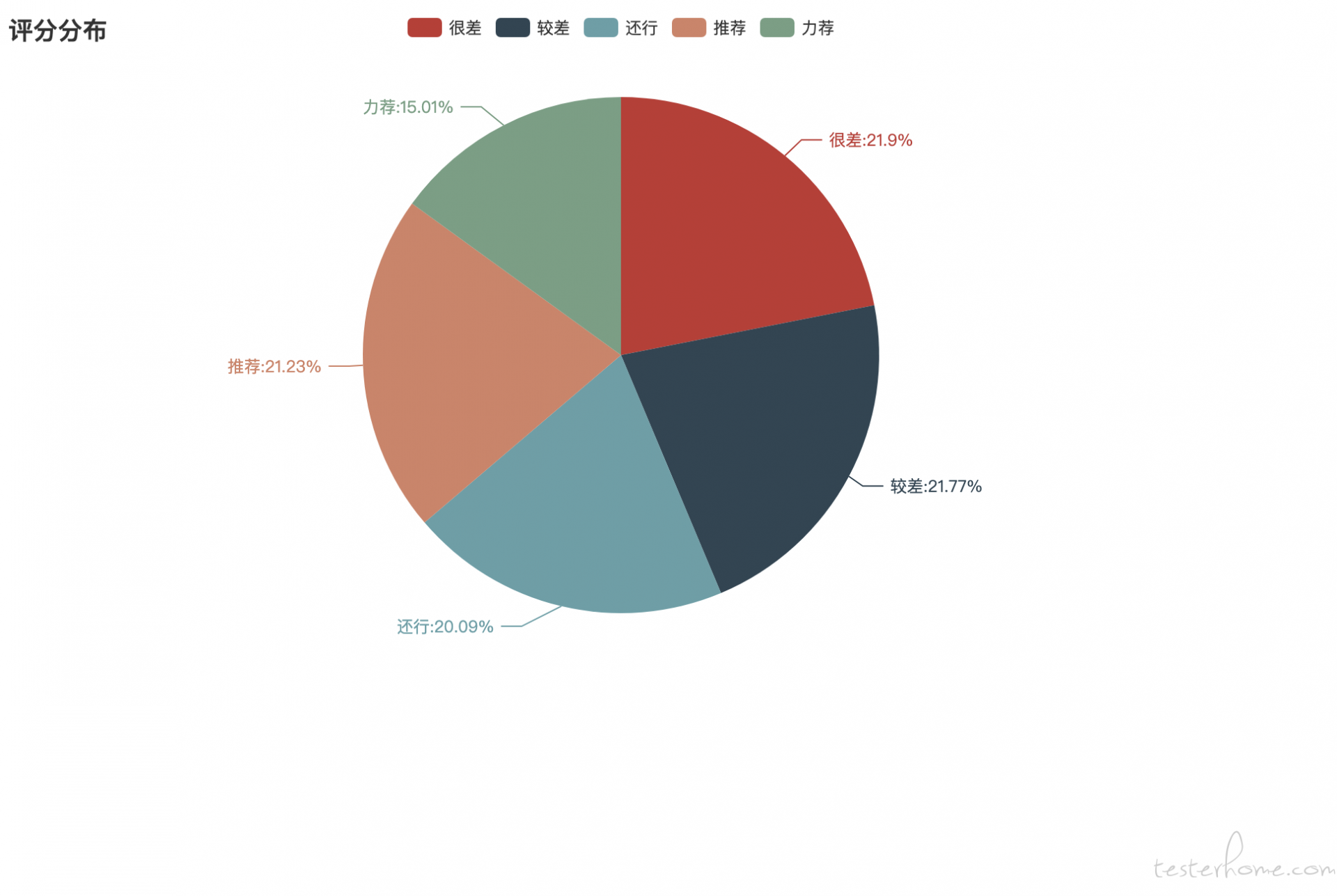
pie = (
Pie()
.add("", [('很差', HENCHA), ('较差', JIAOCHA), ('还行', HAIXING), ('推荐', TUIJIAN), ('力荐', LIJIAN)])
.set_global_opts(title_opts=opts.TitleOpts(title="评分分布"))
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{d}%'))
)
pie.render(path=RootPath + "/star_pie.html")
pie.render()
获取评论时间生成图表
还想看看网友评论的时间段,按照小时维度.
拿到的数据是到秒,做时间处理如下:
1、按照小时过滤
2、按照时间排序后的
comment_time_list = []
with open(TIMEFilePath, 'r') as f:
r_info = f.readlines()
for i in r_info:
comment_time = i.replace("\n", "").split(":")[0] + ":00:00" # 按照小时过滤
comment_time_list.append(comment_time)
comment_dict = {}
comment_dict_list = []
for i in comment_time_list:
if i not in comment_dict.keys():
comment_dict[i] = comment_time_list.count(i)
for k in comment_dict:
comment_dict_list.append({"time": k, "value": comment_dict[k]})
comment_dict_list.sort(key=lambda k: (k.get('time', 0)))
# print(comment_dict_list) # 按照时间排序后的
time_list = []
value_list = []
for c in comment_dict_list:
time_list.append(c['time'])
value_list.append(c['value'])
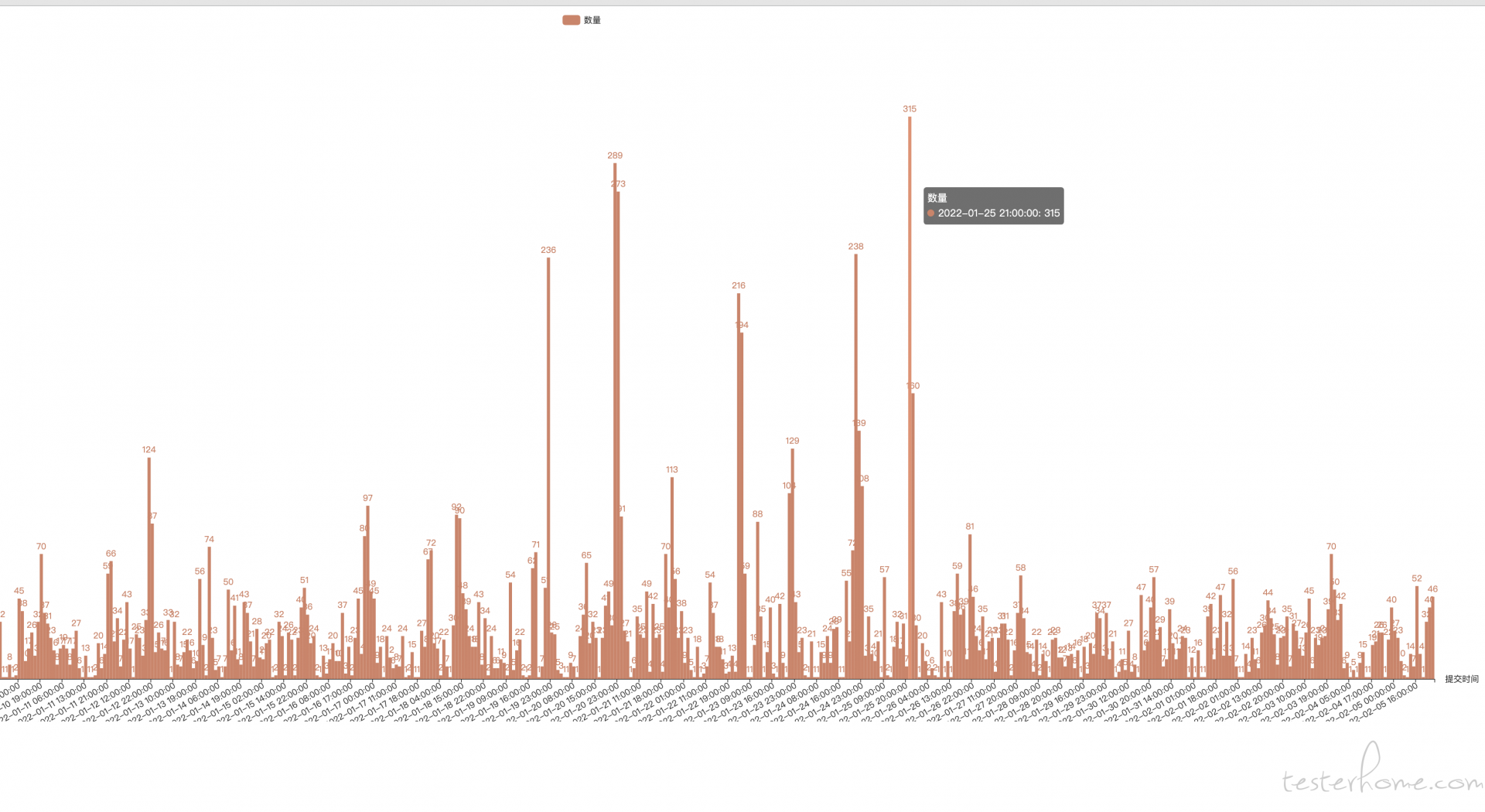
c = (
Bar(init_opts=opts.InitOpts(width="1600px", height="800px"))
.add_xaxis(time_list)
.add_yaxis("数量", value_list, category_gap=0, color=Faker.rand_color())
.set_global_opts(title_opts=opts.TitleOpts(title="评论时间-直方图"),
xaxis_opts=opts.AxisOpts(name="提交时间", axislabel_opts={"rotate": 45}))
.render("comment_time_bar_histogram.html")
)
折线图未设置平滑曲线
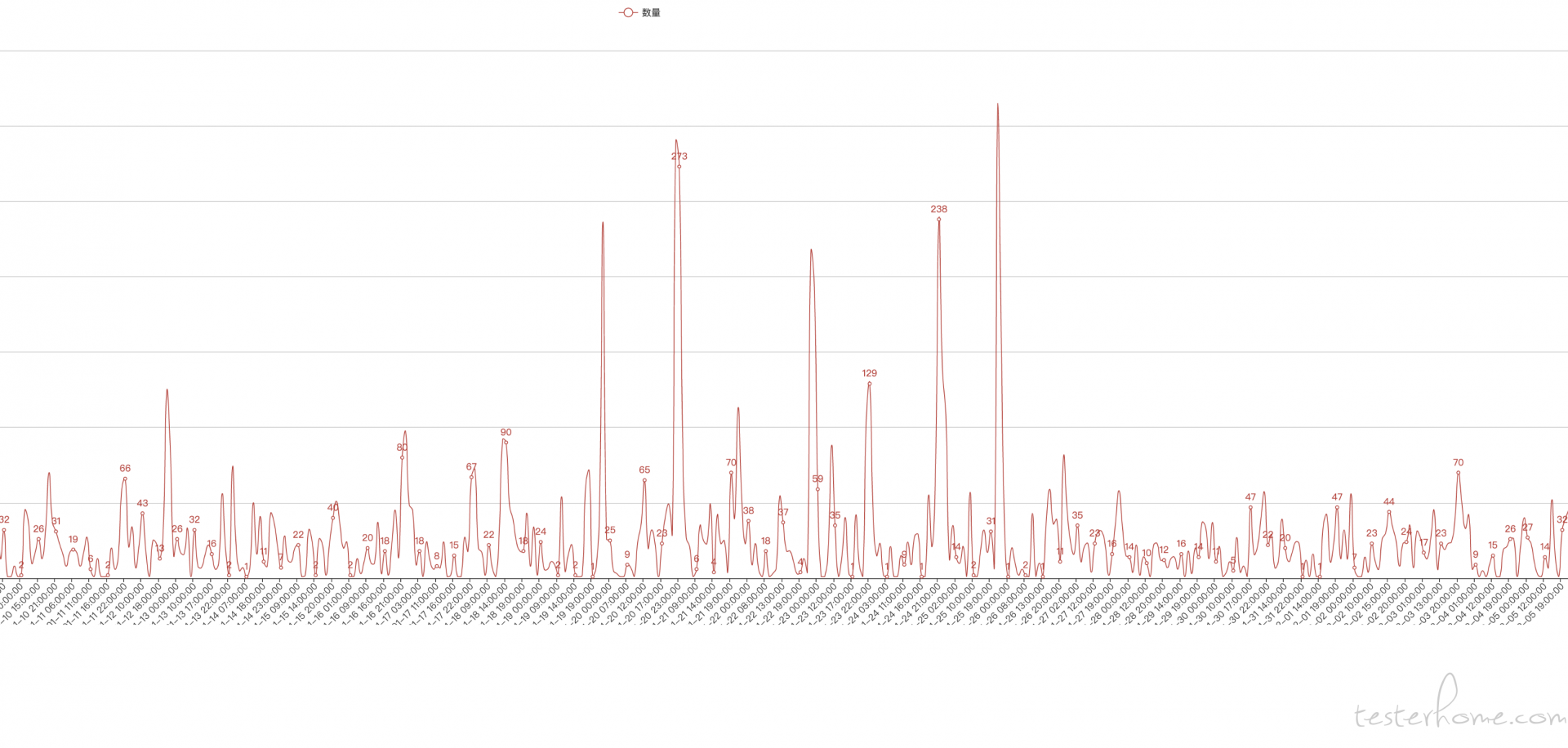
折线图并且设置平滑曲线
获取最多的词
还想看看哪些是"最多的词"
1、使用 jieba 进行分词
2、过滤语气词
包含语气词,这样比较不准,有些词没有什么意义
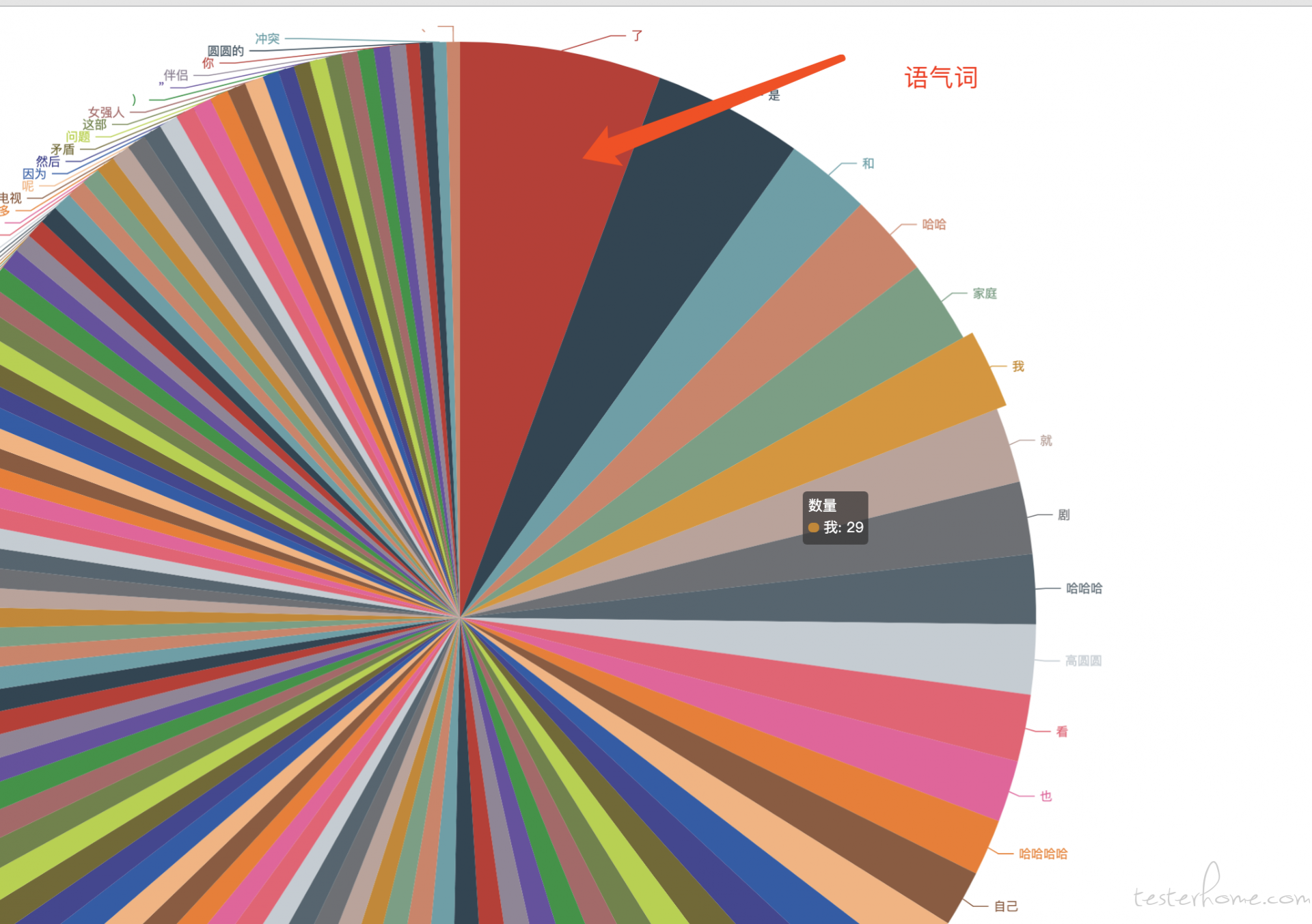
去掉语气词,过滤一些常用的语气词
import jieba
def stopwordslist():
"""
创建停用词列表
:return:
"""
stopwords = [line.strip() for line in open('chinese_stopword.txt', encoding='UTF-8').readlines()]
return stopwords
def seg_depart(sentence):
"""
对句子进行中文分词
:param sentence:
:return:
"""
print("正在分词")
out_str_list = []
sentence_depart = jieba.cut(sentence.strip())
stopwords = stopwordslist()
outstr = ''
# 去停用词
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
out_str_list.append(word)
return out_str_list
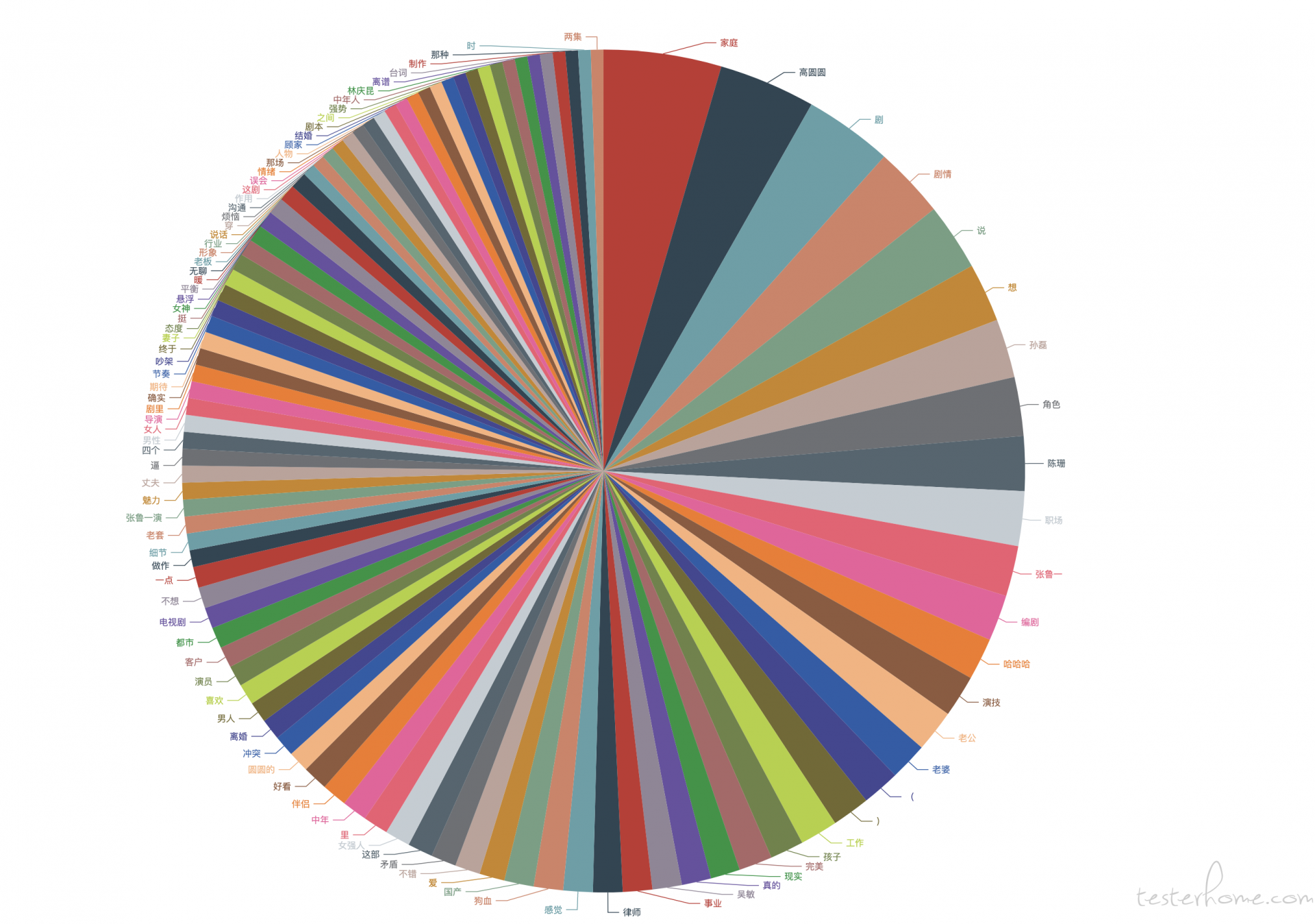
最后
通过一个电视剧评论分析,能得到:
1、python 网络请求练习
2、python 常用数据结构练习
3、python 的图表库使用
4、常用算法练习
最后的最后,在推荐一下这个剧,男主 35+ 为了妻子的事业放弃自己的事业照顾孩子,平衡家庭和事业.
最后一张饼图出现最多的词就是"家庭",联想到我们做互联网的工作压力大并且经常加班忽略家人的陪伴.
新年祝大家工作不加班、多时间陪陪家人~

