度量的最终结果不是一个可视化的图表,而是一个问题改进的清单及改进方案,关注这些度量数据给我们带来的信息,获取当前团队的改进重点,持续优化,才是重中之重。同时,度量是动态变化的,在持持续改进的进程中,我们需要逐步提高标准。
最近,研发效能平台在业内被不断的提起,总结。张乐大神还出来长篇连载,从不同的角度来解读研发效能,笔者也在持续的关注大佬的文章。恰巧笔者在去年也负责了公司度量平台的研发,有一些收获,通过本文分享给大家,也算是自己对这个平台总结。为后续在新团队开展度量活动理清思路。本文将从以下几个方面来做开展:
NO.1 为什么要引入度量活动
管理大师德鲁克说:“你如果无法度量它,就无法管理它”(“It you can’t measure it, you can’t manage it”)”,这句话的大背景是处在工业发展时间,企业创造活动更趋向于劳力活动,所以很多东西都比较好度量。如果以计件的方式来管理软件研发过程,是否合适?这个每个人都有自己的体会。笔者从自己团队的现状出发,给出了自己的看法:

NO.2 度量活动的目标是什么
笔者认为,主要是为了解决痛点 4 失中的 2 失:目标导向缺失及持续优化迷失。
解决标导向缺失:没有明确的、直观的、可量化的数据,我们就无法知道我们努力的目标在哪,在制定 OKR 的时候,我们经常说目标要数据化,是因为具体的数据才能引导我们往这个目标去努力。通过度量活动,建立团队的研发基线,有助于我们明确目标(例如阿里的 “211” 交付愿景)
解决持续优化迷失:我们在为什么做优化?当下技术能力的提升是否能解决团队最紧急的痛点?技术团队比较容易陷入自嗨的情绪中,业务最终的目标是交付价值,不是技术 SHOW。技术难点是团队的瓶颈点,还是测试活动是团队的瓶颈点?又或许是需求拆分?更有可能的是各种环境的准备搞的你焦头烂额?没有可靠的度量数据,只能凭借自己的感觉或者经验,无法弄成统一的大局观,看似解决了某一个痛点,但并未对团队的整体交付带来更高的价值
NO.3 度量指标的选择
明确了目标后,我们就可以有选择性的选择度量指标,经过团队的充分讨论后(而不是拍脑袋或者依据所谓的成熟度指标),我们定义了以下几个维度的度量指标:
需求交付维度,目标:拆分合理,快速交付

研发交付,目标:持续集成,持续验证

测试交付,目标:更早介入,更快回归

在度量前期,我们以这些指标作为指导,观察我们整体的研发活动,看看哪个节点上花费的时间最多,然后就想办法针对性的解决,然后再观察整体,发现节点瓶颈,以此往复,慢慢缩短整体的交付周期。在多轮迭和更新后,形成的最终度量体系如下:

NO.4 技术落地过程
度量平台经过几轮的技术重构和定义,最终的业务架构如下:
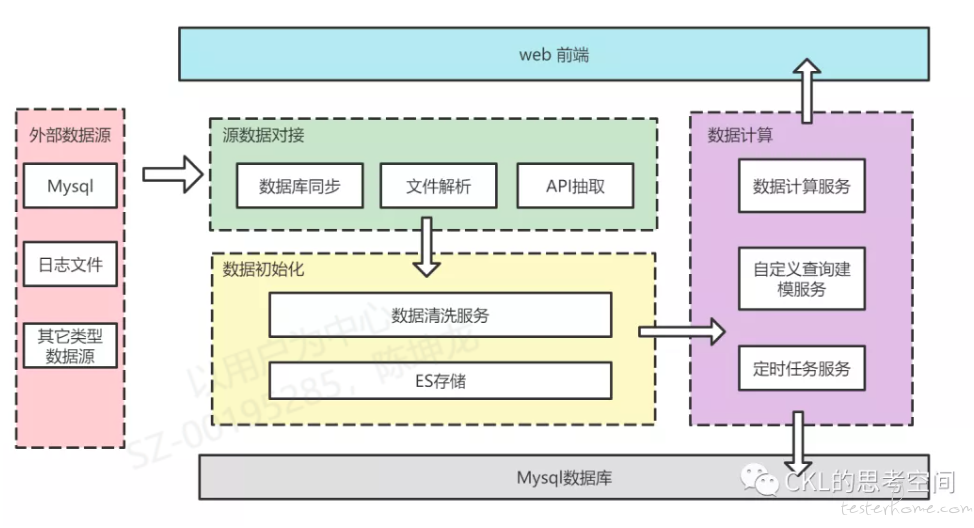
上面的业务架构图应该比较清晰了,就不过多的说明,使用的技术栈也相对简单,核心是 Django+Pandas+Mysql+es+vue。当然还有一些其它的技术组件,就不一一说明了,都相对比较常见。在整个平台的研发过程中,也踩过很多坑,这里提两点比较重要的来说明下,希望大家可以少走点弯路。
-
不同的业务数据库间的数据如何同步到度量平台
虽然公司通过统一的 DevOps 平台管理研发过程,但是每个服务都有自己的数据库,度量平台如何从不同的业务库中收集数据,是第一个难点,经过调研,业内主要有两种方案:
方案一:同步双写:最为简单的方式,业务在将数据写到 mysql 时,同时将数据写到 ES,实现数据的双写。
优点:业务逻辑简单。
缺点:硬编码;业务强耦合;存在双写失败丢数据风险;性能较差方案二:利用 Mysql 的 Binlog 来进行同步,具体步骤如下:读取 Mysql 的 Binlog 日志,获取指定表的日志信息;将读取的信息转为 MQ;编写一个 MQ 消费程序;不断消费 MQ,每消费完一条消息,将消息写入到 ES 中。
优点:自主可控,性能也较好。
缺点:需要 binlog 权限,需要额外的研发工作量
我们采用的是第三种取巧的方案:因为业务的数据库采用了主从结构,所以我们直接从业务的从库中拿一台出来,给度量平台用,直接从业务数据库里读数据,虽然方法土了些,但省时省力,后续数据量上来了,再考虑其它的方案。 ES 从入门到放弃
当度量平台把业务数据从业务数据库抽取出来,经过清洗后,要放在哪里进行聚合计算,成为了第二个难点。当时团队有两种思路:用行业比较流行的 ES 来处理,或者用 Pandas 来处理。由于两种方式团队内成员都没有明显的实战经验,于是就两种方法都采用,需求和测试的报表用 ES,研发类报表用 Pandas。
经过几轮的迭代后,Pandas 的优势明显。ES 的缺陷有两个:
第一个问题,Mysql 的数据同步到 ES 需要用到 logstat 组件来处理,这需要我们单独部署一个服务来处理,由于经验不足,logstat 的 output 配置写的很糟糕,用表结构直接映射。
这就带来了第二个问题,由于 output 是根据表来做的,所以 ES 生成的 Index 和表是一一对应的,对于 Mysql 来说,多表关联查询是再正常不过了,但是对于 ES 来说,跨 Index 查询是非常糟糕的,官方的用法也不推荐(虽然用宽表模式可以解决,但会冗余很多数据,并不友好。有这方面经验的大神可以指教下)。
最终,我们还是逐渐放弃使用 ES,Pandas 还是很香的,不是么。放一些效果图给大家参考下:
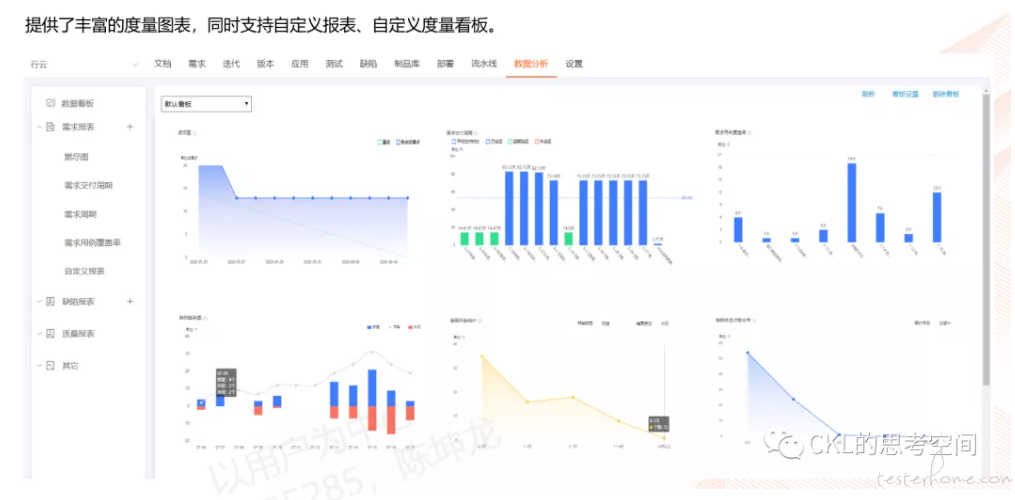

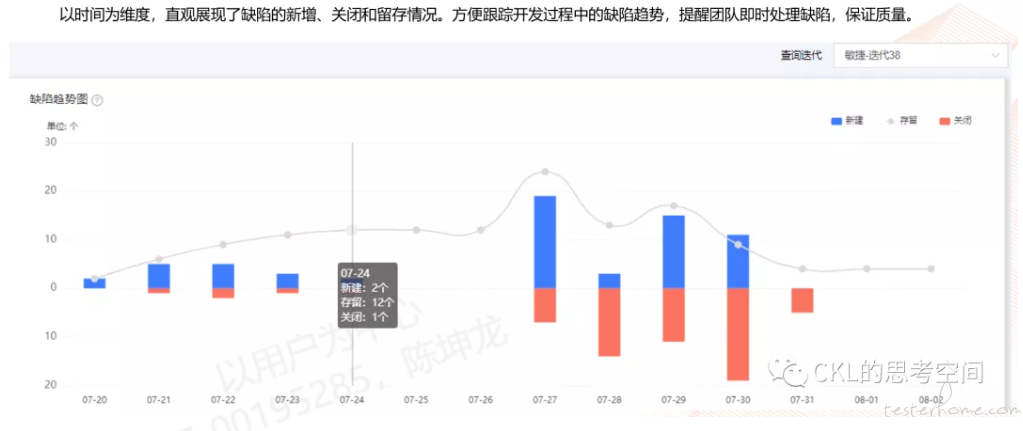
NO.5 测试活动只是开始,不是结束
度量平台搭建完成后,并不意味着度量活动的终结,恰恰相反,有了度量平台,反而是我们做持续改进的开始,度量的最终结果不是一个可视化的图表,而是一个问题改进的清单及改进方案,关注这些度量数据给我们带来的信息,获取当前团队的改进重点,持续优化,才是重中之重。同时,度量是动态变化的,在持持续改进的进程中,我们需要逐步提高标准。
同时,不要把度量反馈的数值直接和个人的 KPI 关联,这样会很容易把度量引导到不正确的方向。细心的读者可能会发现,在第 3 小节中,我们选取的指标基本上都是基于团队导向的,很少会有个人的数据度量(业内常见的代码行数、个人缺陷数、千行 BUG 率之类),因为这类数据虽然很好统计,但缺乏指导性,团队成员容易提交大量重复、冗余的代码来 “凑指标”,让数据变得很好看,但这对团队没有任何价值。
