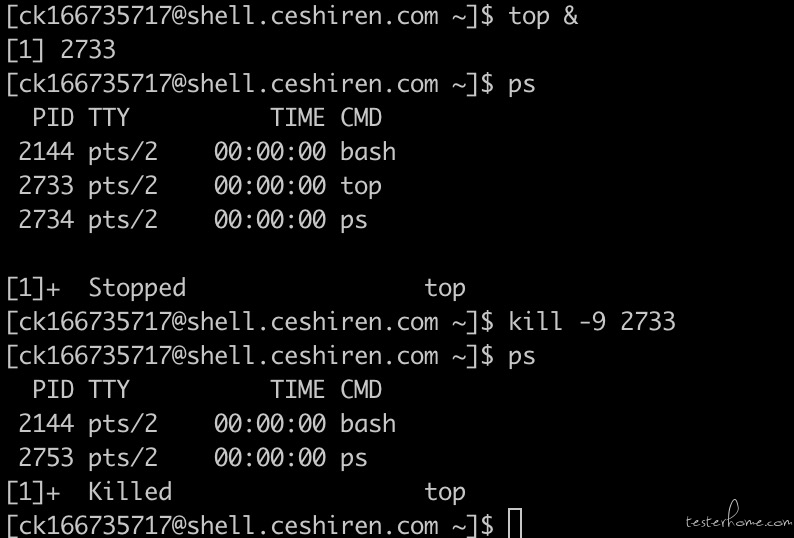
查看系统信息常用命令
file /bin/ls:查看系统的操作位数(64/32)

uname -a -r -s :查看系统内核
-a:查看系统所有相关的信息
-r:查看内核版本
-s:查看内核名称
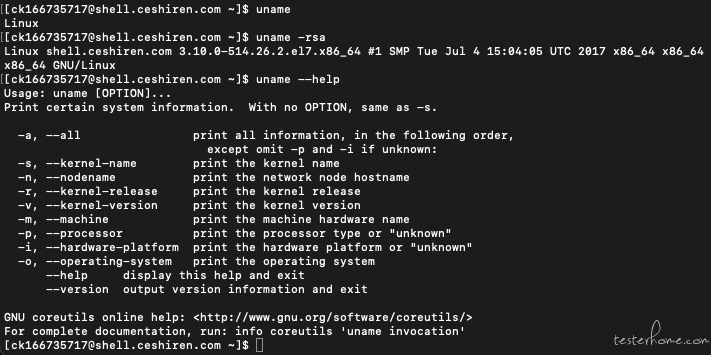
cat /proc/cpuinfo:显示 CPU 相关信息
cpu cores:cpu 核数
model name:cpu 型号
cache size:缓存大小
有 2 个 processor 表示是双核处理器:
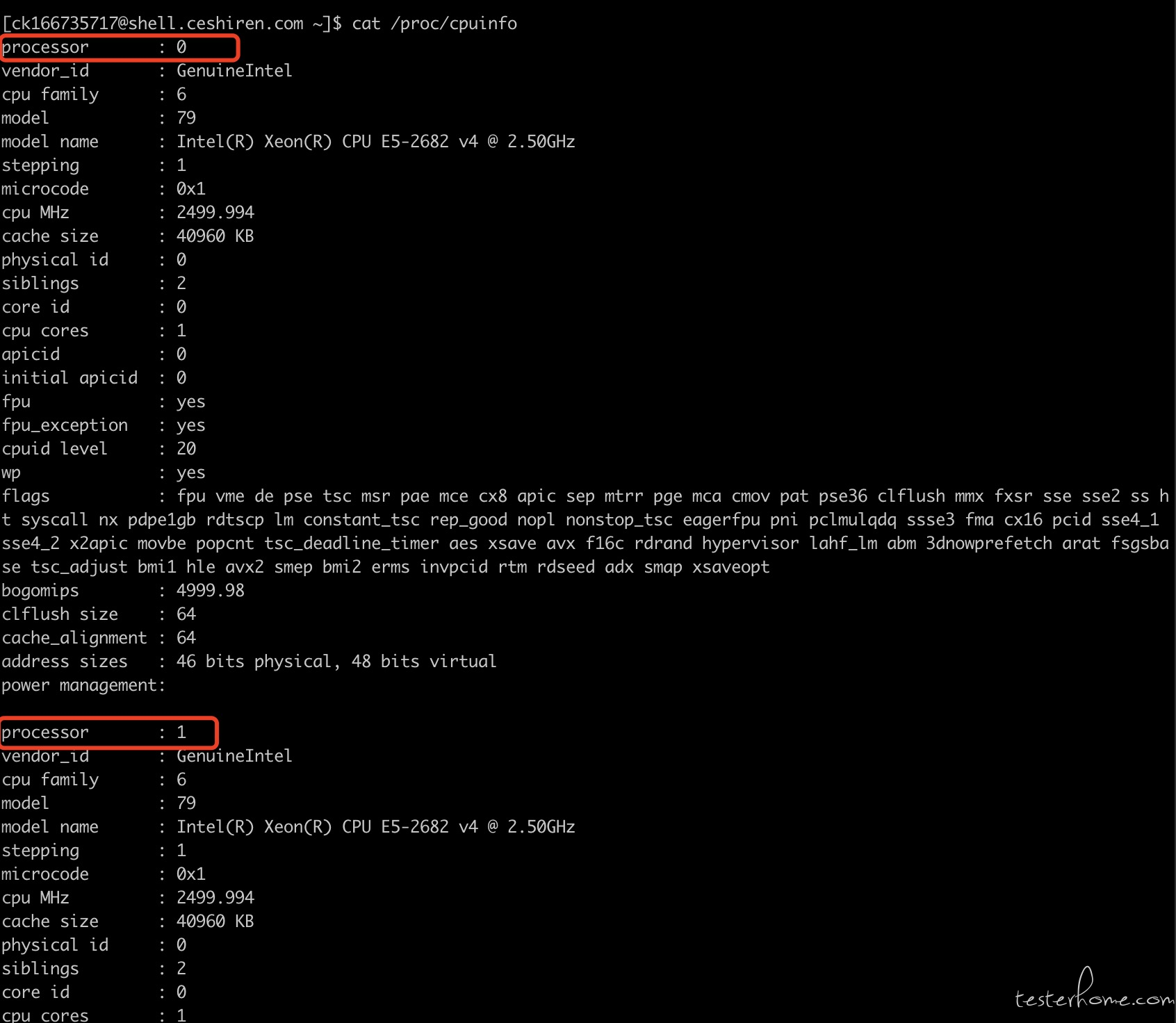
lsb_release -a:查看当前系统 linux 发行版本
LSB: Linux Standard Base
dmesg:打印开机启动信息
dmesg: display message 命令用于打印 Linux 系统开机启动信息。
dmesg | grep cpu
uptime:查看运行时长,平均负载
Uptime 显示系统已经运行了多长时间,它依次显示下列信息:当前时间、系统已经运行了多长时间、有多少登陆用户、系统在过去的 1 分钟、5 分钟和 15 分钟内的平均负载

w: 显示登录用户列表
命令用于显示已经登陆系统的用户列表,并显示用户正在执行的指令

查看系统资源常用命令
df:检测磁盘空间
df 命令用于检测文件系统的磁盘空间占用和空余情况,可以显示所有文件系统对节点和磁盘块的使用情况。
-a :显示所有文件系统的磁盘使用情况
-m :以 1024 字节为单位显示
-t :显示各指定文件系统的磁盘空间使用情况
-h :print sizes in human readable format (e.g., 1K 234M 2G)
注意:
du,disk usage,是通过搜索文件来计算每个文件的大小然后累加,du 能看到的文件只是一些当前存在的,没有删除的。他计算的是当前他认为的所有文件大小的累加。
df,disk free,通过文件系统来快速获取空间大小的信息,当我们删除一个文件的时候,这个文件不是马上就在文件系统中消失了,而是暂时消失了,当所有程序都不用时,才会根据操作系统的规则释放掉已经删除的文件,df 记录的是通过文件系统获取到的文件的大小,他比 du 强的地方就是能看到已经删除的文件。
当文件系统也确定删除了该文件后,这时候 du 与 df 就一致了。
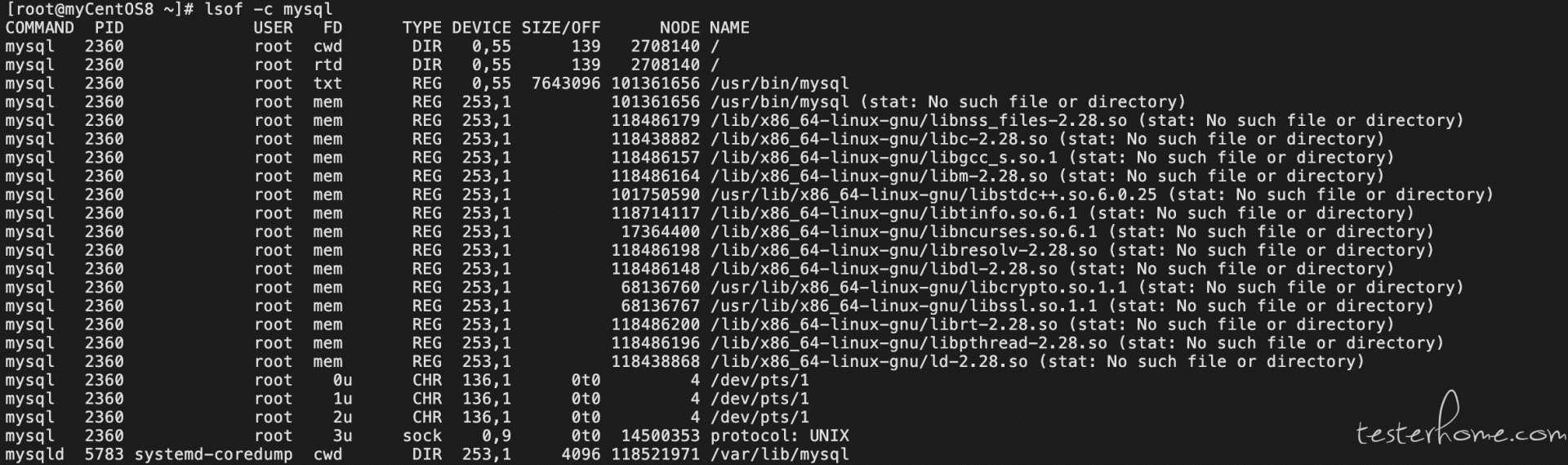
lsof :列出进程调用或者打开的文件信息
lsof -c 字符串:列出以字符串开头的进程打开的文件
lsof -u 用户名:列出某个用户的进程打开的文件
lsof -p pid:列出某个 pid 进程打开的文件
lsof -i :port:列出谁在使用某个端口
lsof | more:查询系统中所有进程调用的文件
lsof /sbin/init:查询某个文件被哪个进程调用
lsof -c nginx :查看 nginx 进程调用了哪些文件
lsof -u root :按照用户名,查询某用户的进程调用的文件名
lsof -i :5672:列出在使用 5672 的进程

top:用于实时显示 process 的动态
top 命令是一个功能十分强大的监控系统的工具,对于系统管理员而言尤其重要。但是,它的缺点是会消耗很多系统资源。前 5 行为系统总体资源统计情况
命令选项:
-d:间隔时间,top -4 表示每 4 秒更新一次
-n:获取多次 cpu 的执行情况,top -n 4 表示跟新 4 次
-p:获取指定端口的进程数据
-u,显示指定用户的进程
-b:批处理模式
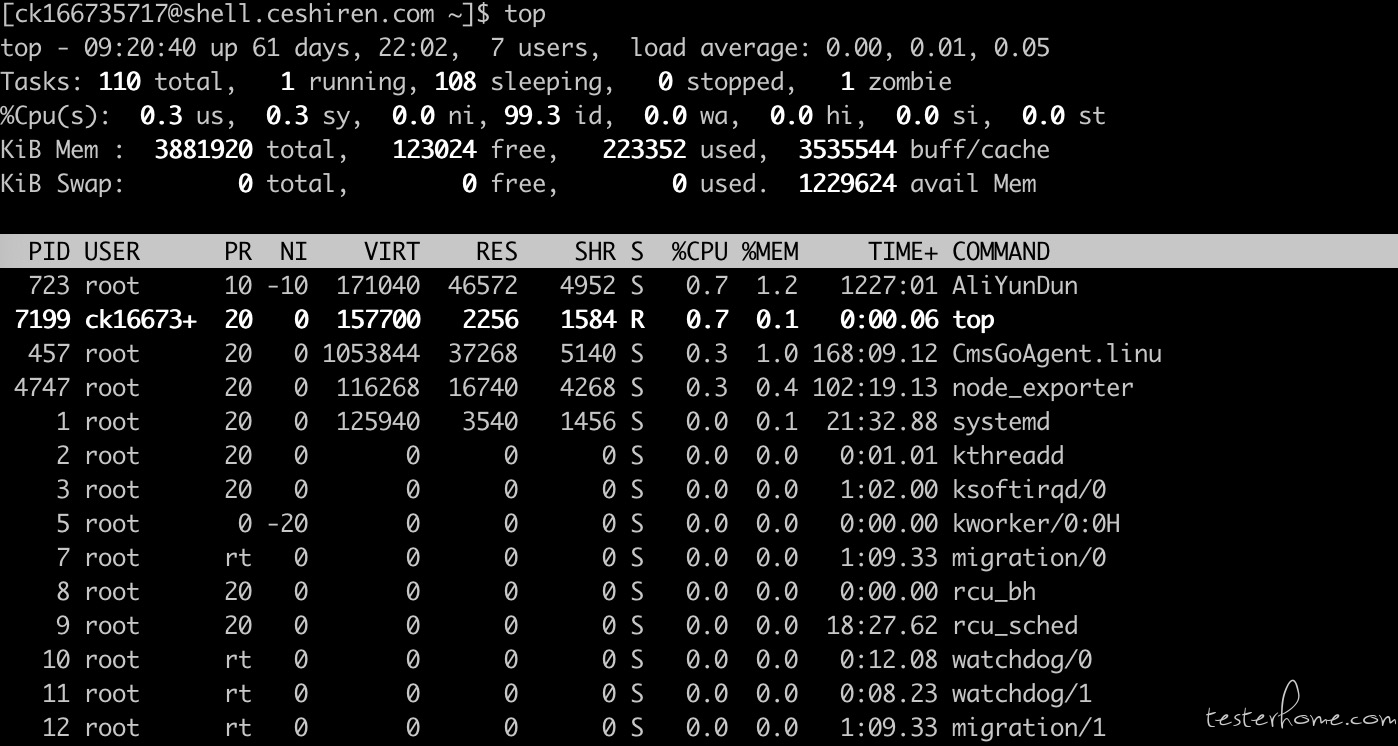
前两行信息:
load average: 1 分钟,5 分钟,15 分钟,平均负载>2 时,表示系统性能不够
tasks:110,一共有 110 个进程在运行,running:1 个运行,sleeping:108 个休眠,stopped:停止的进程数
zombie:1 个僵尸进程
CPU 信息:
us:user time,用户空间占用 CPU%
sy:system time,内核空间占用 CPU%
ni:nice 改变过优先级的进程占用 CPU%
id:idle 空闲 CPU%
wa:IO 等待占用 CPU%
hi:hardware interrupt 硬中断占用 CPU%
si:software interrupt 软中断占用 CPU%
st:steal time 虚拟机中的其他任务所占 CPU 时间的比率
系统交换区信息:
total:系统全部的交换区总量
used:当前已经使用的物理内存总量
free:当前空闲的交换区总量
cached:被缓冲的交换区总量
进程信息:
PR:进程优先级,程序被 CPU 执行的先后顺序,此值越小进程的优先级别越高
NI:nice 值,负值表示优先级高,正值表示优先级低,进程可被执行的优先级的修正数值。
PR_new = PR_old + nice,nice 越小 PR 越优先,其优先权变高,就越快被执行。如果 nice 相同,进程为 root 的优先权更大
VIRT:进程使用的虚拟内存总量,单位 KB,VIRT=SWAP+RES
RES:进程使用的,没有被换出的物理内存大小,单位 KB
SHR:共享内存大小,单位 KB
S:进程状态,进程状态:
D = uninterruptible sleep
I = idle
R = running
S = sleeping
T = stopped by job control signal
t = stopped by debugger during trace
Z = zombie
%CPU:上次跟新到现在的 CPU 时间占用百分比
%MEM:进程使用的物理内存百分比
TIME+:进程使用 CPU 的时间总和,单位 1/100s
COMMAND:进程名
常见情形:
用户进程 us 占比高,I/O 操作 wa 低:说明系统缓慢的原因在于进程占用大量 CPU,通常还会伴有教低的空闲比率 id,说明 CPU 空转时间很少。
I/O 操作 wa 低,空闲比率 id 高:可以排除 CPU 资源瓶颈的可能。
I/O 操作 wa 高:说明 I/O 占用了大量的 CPU 时间,需要检查交换空间的使用,交换空间位于磁盘上,性能远低于内存,当内存耗尽开始使用交换空间时,将会给性能带来严重影响,所以对于性能要求较高的服务器,一般建议关闭交换空间。另一方面,如果内存充足,但 wa 很高,说明需要检查哪个进程占用了大量的 I/O 资源。
linux 机器的平均负载:
什么是机器平均负载?
特定的时间间隔内,排队等待 cpu 处理的进程数,排队等待的进程越多,说明 cpu 处理的慢,机器的平均负载约大。
如何衡量当前系统是否负载过高?
如果每个 cpu(可以按 CPU 核心的数量计算) 上当前活动进程数不大于 3,则系统性能良好;不大于 4,表示可以接受;如大于 5,则系统性能问题严重。
查看平均负载的方法:
先查看 Linux 机器的 CPU 核数,可以用 cmd:cat /proc/cpuinfo | grep 'model name' | wc -l

然后用 cmd:m 或者 uptime 或者 top 查看平均负载的数值,评价系统的负载一般采用 15 分钟内的平均负载值。为了系统顺畅运行,单核系统 load 值最好不要超过 1.0;双核系统的 load 值健康值应该为 2,以此类推。
free:用于显示内存使用情况
free -h -s5
free 命令是用来查看内存使用情况的主要命令。和 top 命令相比,它的优点是使用简单,并且只占用很少的系统资源。通过-S 参数可以使用 free 命令不间断地监视有多少内存在使用,这样可以把它当作一个方便实时监控器。

total:总的物理内存
used:已经使用的物理内存
free:没有被使用过的物理内存
shared:多进程共享内存
buff/cache:读写缓存内容,这部分内存是当空闲来用的,当 free 内存不足时,linux 内核会将此内存释放。
available:可用物理内存
缓存 catch 是用于存取从磁盘中读取的数据;
缓冲 buffer 是暂存需要写入磁盘的数据。
vmstat:用于显示服务器整体使用状态
展现给定时间段的服务器的状态值,包括 CPU 使用率,内存使用,虚拟内存交换情况,IO 读写情况
#vmstat 1 2 //每 2 秒采样一次服务器状态
第一个参数是采样的时间间隔(s)第二个参数是采样的次数
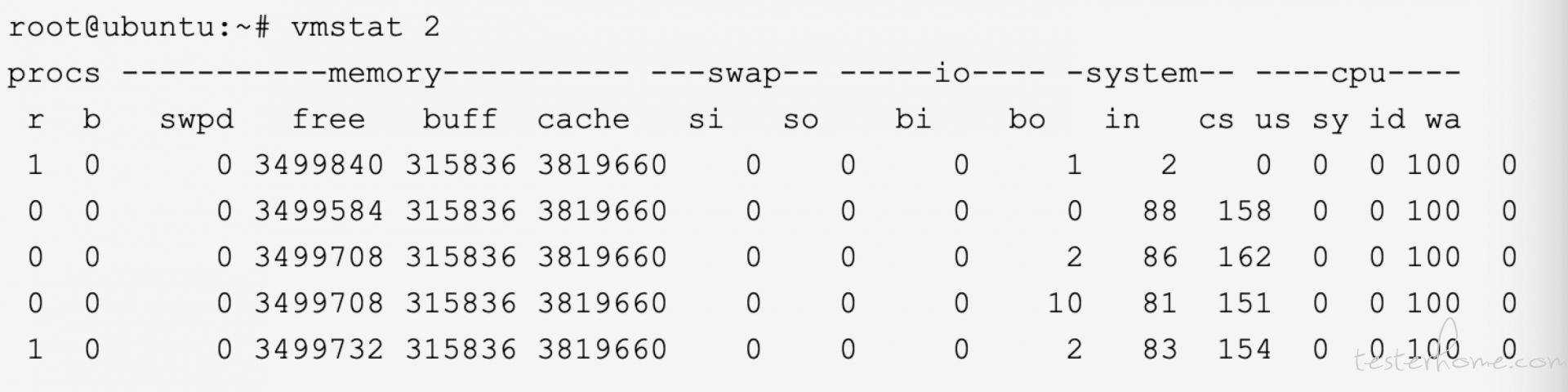
r:表示运行队列,多少个进程真的分配到 CPU,一般负载超过了 3 就比较高了,超过 5 就高了,超过 10 就不正常了。
b:表示阻塞进程个数
swpd:虚拟内存已使用的大小,如果大于 0,表示物理内存不足。
free:空闲的物理内存的大小
buff:缓存的大小
si:每秒从磁盘读入虚拟内存的大小
so:每秒缓存写入磁盘的大小
bi:块设备每秒接受的块数量
bo:块设备每秒发送的块数量
in:每秒 cpu 的中断次数
cs:每秒上下文切换次数
us:用户 CPU 时间
sy:系统 CPU 时间
id:空间 CPU 时间
id + us + sy = 100,id 是空闲 CPU 使用率,us 是用户 CPU 使用率,sy 是系统 CPU 使用率。
wt:等待 IO CPU 时间
例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在 apache 和 nginx 这种 web 服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择 web 服务器的进程可以由进程或者线程的峰值一直下调,压测,直到 cs 到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的 CPU 大部分浪费在上下文切换,导致 CPU 干正经事的时间少了,CPU 没有充分利用,是不可取的。(摘抄自性能测试,没太明白)
iostat:查看系统 IO 的状况
iostat 命令可以查看系统分区的 IO 使用情况
iostat -x -k -d 1 2。每隔 1S 输出磁盘 IO 的详细,总共采样 2 次。-c:只查看 CPU 信息 -d:只看硬盘信息
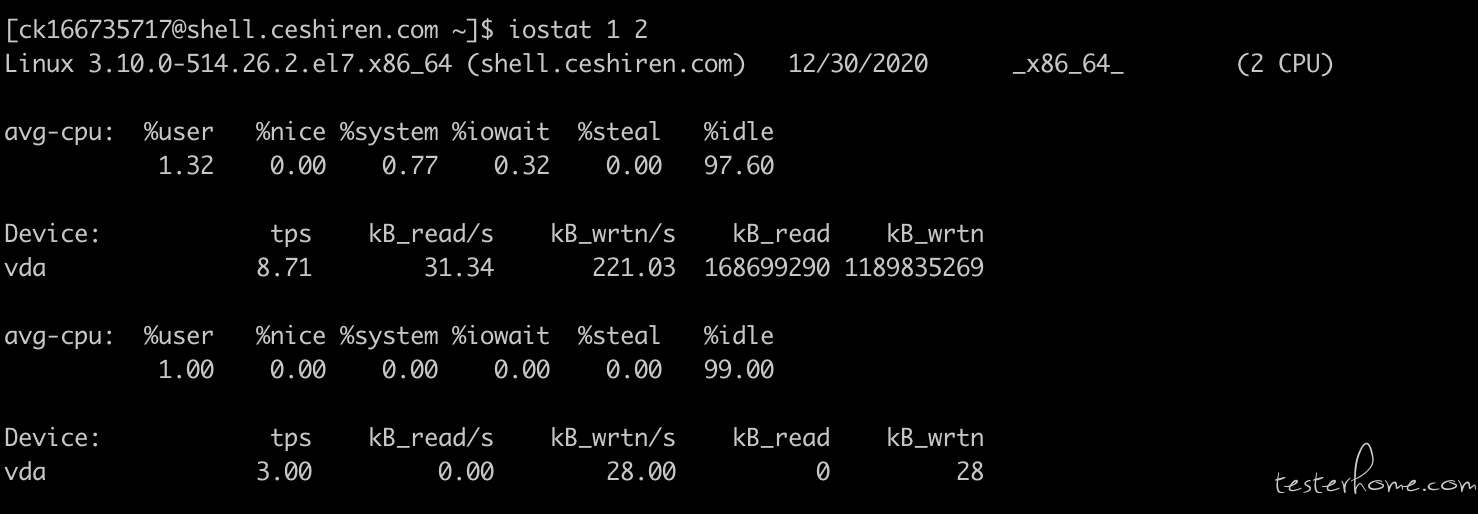
Device : 磁盘名称
tps : 每秒 I/O 传输请求量
Blk_read/s : 每秒读取多少块,查看块大小可参考命令 tune2fs
Blk_wrtn/s : 每秒写取多少块
Blk_read : 一共读了多少块
Blk_wrtn : 一共写了多少块
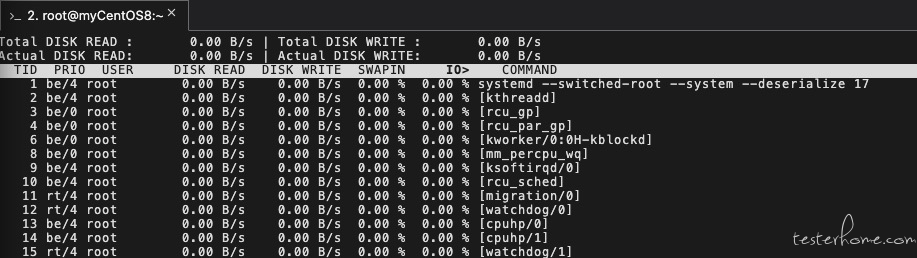
iotop:查看进程 I/O 情况
iotop 命令类似于 top 命令,但是显示的是各个进程的 I/O 情况,对于定位 I/O 操作较重的进程有比较大的作用。
netstat:查看网络负载情况
-t:列出所有 tcp
-n:以数字形式显示地址和端口号
-p:显示进程的 pid 和名字
-l:仅列出在 Listen 监听状态的服务
iftop:查看网络 IO
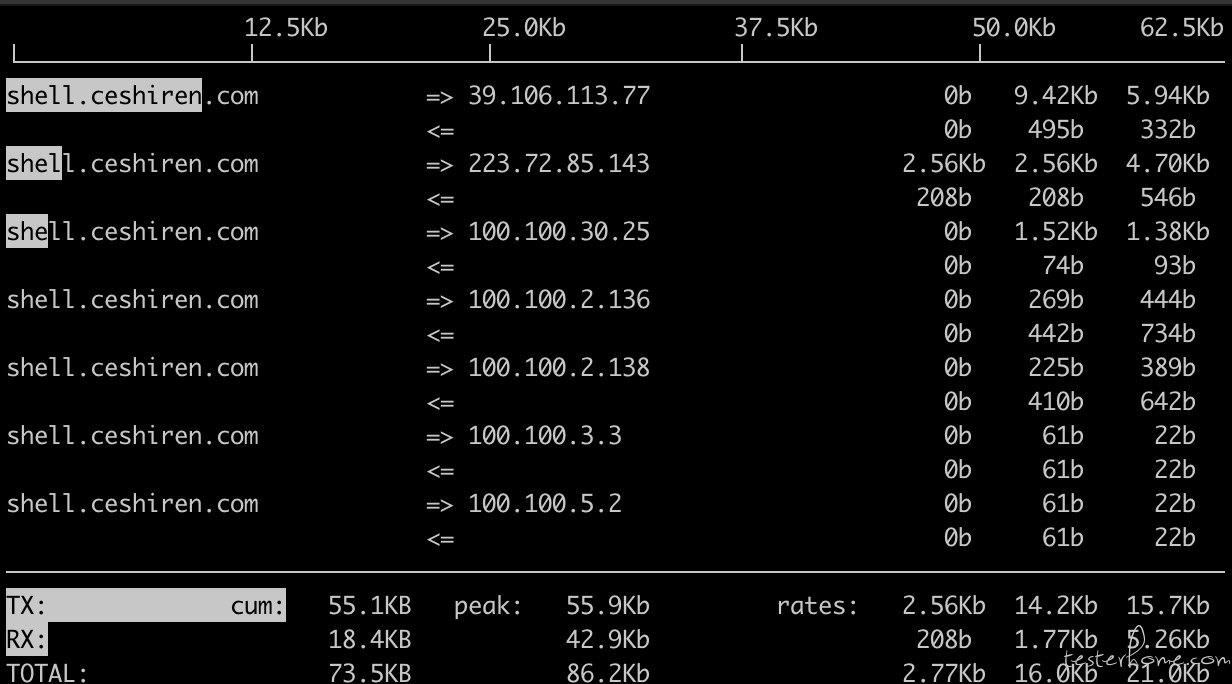
iftop -n -i eth0:不进行 DNS 反解析
=>:代表发送数据
<=:代表接受数据
TX:Transmission 发送
RX:Reception 接受
TOTAL:全部流量
cum:cumulative 目前累计流量
peak:峰值流量
rates:平均值,2s,10s 和 40s 的平均流量
sar:System Activity Reporter 系统活动情况报告
https://www.cnblogs.com/qiumingcheng/p/10769980.html
sar 是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘 I/O、CPU 效率、内存使用状况、进程活动及 IPC 有关的活动等。
sar [options] [-A] [-o file] t [n]
t 为采样间隔,n 为采样次数,默认值是 1;
-o file 表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项,
sar 命令常用选项如下:
-A:所有报告的总和
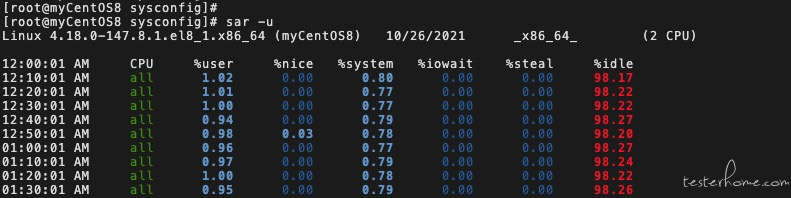
-u:输出 CPU 使用情况的统计信息
-v:输出 inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示 I/O 和传送速率的统计信息

-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
很多时候当检测到或者知道历史的高负载状况时,可能需要回放历史监控数据,这时 sar 命令就派上用场了,sar 命令同样来自 sysstat 工具包,可以记录系统的 CPU 负载、I/O 状况和内存使用记录,便于历史数据的回放。
sysstat 的配置文件在 /etc/sysconfig/sysstat 文件,历史日志的存放位置为 /var/log/sa\ 统计信息都是每 10 分钟记录一次,每天的 23:59 会分割统计文件,这些操作的频率都在 /etc/cron.d/sysstat 文件配置。
CPU 负载和 CPU 利用率
CPU 负载:load average,系统平均负载是 CPU 的 Load,是在一段时间内 CPU 正在处理以及等待 CPU 处理的进程数之和的统计信息。也就是 CPU 使用队列的长度的统计信息,这个数字越小越好。
CPU 使用率:显示的是程序在运行期间实时占用的 CPU 百分比。
CPU 利用率高,并不意味着负载就一定大:
如果有一个程序它需要一直使用 CPU 的运算功能,那么此时 CPU 的使用率可能达到 100%,但是 CPU 的工作负载则是趋近于"1",因为 CPU 仅负责一个工作!
如果同时执行这样的程序两个呢?CPU 的使用率还是 100%,但是工作负载则变成 2 了。所以也就是说,当 CPU 的工作负载越大,代表 CPU 必须要在不同的工作之间进行频繁的工作切换。
& :设置为后台进程
& 放在启动参数后面表示设置此进程为后台进程
默认情况下,进程是前台进程,这时就把 Shell 给占据了,我们无法进行其他操作,对于那些没有交互的进程,很多时候,我们希望将其在后台启动,可以在启动参数的时候加一个'&'实现这个目的。