WeTest腾讯质量开发平台 跨越适配&性能那道坎,企鹅电竞 Android weex 优化
企鹅电竞从 17 年 6 月接入 weex,到现在已经有一段时间了,这段时间里面,针对遇到的问题,企鹅电竞终端主要做了下面的优化:
image 组件
预加载
预渲染
Image 组件
weex 的 list 组件和 image 组件非常容易出问题,企鹅电竞本身又存在很多无限列表的 weex 页面,list 和 image 的组合爆发的内存问题,导致接入 weex 后 app 的内存问题导致的 crash 一直居高不下。
list 组件问题
首先来说一下 list,list 对应的实现是 WXListComponent,对应的 view 是 BounceRecyclerView。RecyclerView 应该大家都很熟悉,android support 库里面提供的高性能的替代 ListView 的控件,它的存在就是为了列表中元素复用。本来 weex 使用了 RecyclerView 作为 list 的实现,是一件皆大欢喜的事情,但是 RecyclerView 中有一种使用不当的情况,会导致 view 不可复用。
下图描述了 RecyclerView 的复用流程:
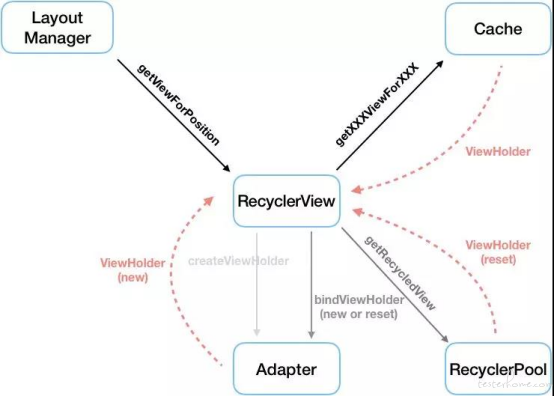
[ RecyclerView 复用 ]
weex 中的 RecyclerView 并没有设置 stableId,所以 RecyclerView 的所有复用都依赖于 ViewHolder 的 ViewType,Weex 的 ViewType 生成见下图:
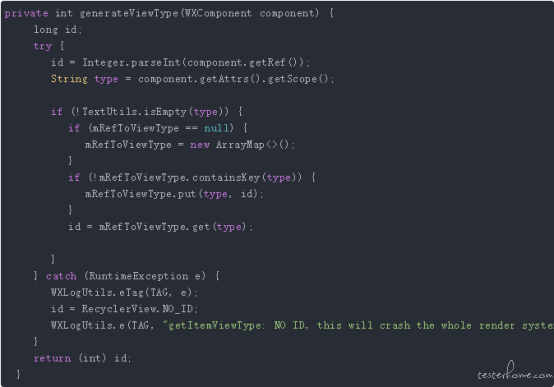
在没有设置 scope 的情况下,viewHolder 的 component 的 ref 就是 viewType,即所有的 ViewHolder 都是不同且不可复用的,此时的 RecyclerView 也就退化成了一个稍微复杂一点的 ScrollView。
如果设置了 scope 属性,但你绝对想不到,scope 本身也是一个坑。下面直接上代码:
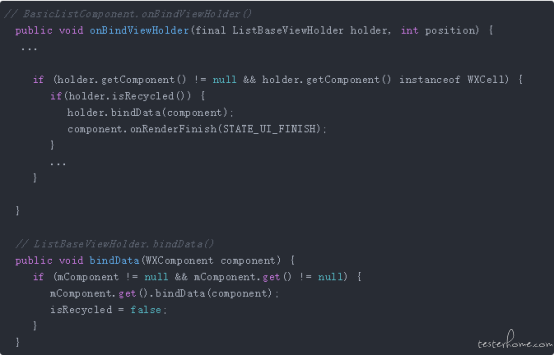
上面代码中,可以看到,使用了 scope,当复用 Holder 时,会把需要展示的 component 的数据绑定到复用的 component 中。那么问题来了,如果我不是只是想修改部分属性,而是需要改变 component 的层级关系呢?例如从 a->b->c 修改成 a->c->b,那么是不是只能用不同的 viewType 或者是说变成下面的结构:a->b a->c b->b1 b->c1 c->c2 c->b2 这样的结构,但是 view 的实例多了,必然又会导致内存等各种问题。最为致命的问题是,createViewHolder 的时候,传给 ViewHolder 的 component 实例就是原件,而非拷贝,当 bindData 执行了以后,就等用于你复用的那个 component 的数据被修改了,当你再滑回去的时候,GG。
所以 scope 属性基本不可用,留给我们的只有相当于 scrollView 的 list。
还好,为了解决 list 这么戳的性能,有了 recyclerList,从 vue 的语法层,支持了模板的复用。但是坑爹的是,0.17 、 0.18 版本 recyclerList 都有这样那样的问题,重构同学觉得使用起来效率较低。0.19 版本 weex 团队 fix 了这些问题后,企鹅电竞的前端同学也正在尝试往 recyclerList 去切换。
image 组件问题
相信 android 开发们都清楚,图片的问题永远是大问题。OOM、GC 等性能问题,经常就是伴随着图片操作。
在 0.17 版本以前,WXImageView 中 bitmap 的释放都是在 component 的 recycle 中执行,0.17 版本之后,在 detach 时也会执行 recycle,但是 WXImageView 的 recycle 只是把 ImageView 的 drawable 设置为 null,并没有实际调用 bitmap 的 recycle。
而企鹅电竞在版本运行过程中发现,仅仅把 bitmapDrawable 设置为 null,不去调用 bitmap 的 recycle,部分机型上面的 oom 问题非常突出(这里一直没想明白,为啥这部分机型会出现这个问题,后面替换成 fresco 去管理就没这个问题了)。当然,如果直接 recycle bitmap,不设置 bitmapDrawable,会直接导致 crash。
回到企鹅电竞本身,企鹅电竞中的图片管理使用了 fresco,在接入 weex 以前,我们已经针对 fresco 加载图片做了一系列优化,而且 fresco 本身已经包含了三级缓存等功能。
接入 weex 后,首先想到的就是使用 fresco 的管线加载出 bitmap 后给 WXImage 使用。在这个过程中,先是遇到了对 CloseableReference 管理不恰当导致 bitmap 还在使用却被 recycle 掉了,然后又遇到了没有执行 recycle 导致 bitmap 无法释放的坑。在长列表中,图片无法释放的问题被无限放大,经常出现快速滑动几屏就 oom 的问题。而且随着业务发展使用 WXImage 无法播放 gif 和 webp 图片也成为瓶颈。
后续版本中,企鹅电竞直接重写了 image 和 img 标签,使用 Fresco 的 SimpleDraweeView 替换了 ImageView。该方案带来的收益是 bitmap 不在需要自己管理,即 oom 问题和 bitmap recycle 之后导致的 crash 问题会大大减少,且 fresco 默认就支持 gif 和 webp 图片。但是,这个方案也有个致命的问题:圆角。
圆角问题得先从 fresco 和 weex 各自的圆角方案说起。
weex 圆角 (盒模型-border):https://weex.apache.org/cn/wiki/common-styles.html#shi-li
fresco 圆角:https://www.fresco-cn.org/docs/rounded-corners-and-circles.html
fresco 圆角方案具体可见 RoundedBitmapDrawable,RoundedColorDrawable,RoundedCornersDrawable 这 3 个类,fresco 圆角属性的改变最终都只是修改这 3 个类的属性,圆角也是基于 draw 时候修改 canvas 画布内容实现,BtimapDrawable 的裁减以及边框的绘制都是在 draw 的时候绘制上去。
weex 圆角方案具体可见 ImageDrawable,实现方案为借助 android 的 PaintDrawable,通过设置 shader 实现 bitmapDrawable 的裁减,但是边框的绘制则依赖于 backgroundDrawable。
而且在 fresco 中,封装了多层的 drawable,较难修改 drawabl 的 draw 的逻辑,而且边框参数的设置也不如 weex 众多样化。
针对两者的差异性,企鹅电竞的解决方案是放弃 fresco 的圆角方案,通过 fresco 的后处理器裁减 bitmap 达到圆角的效果,边框复用 weex 的 background 的方案。这个方案唯一的问题后处理器中必须创建一份新的 bitmap,但是通过复用 fresco 的 bitmapPool,并不会导致内存有过多的问题。
下面贴一下后处理器处理圆角的关键代码:

当 list 和 image 组合在一起的时候,由于 weex 的 image 并没有 recycle 掉 bitmap,而且没有 bitmapPool 的使用,会导致长列表 weex 页面占用内存特别高。而替换为 fresco 的 bitmap 内存管理模式后,由于 weex 导致的内存 crash 问题占比明显从最开始版本的 2% 下降到了 0.1%-0.2%。
预加载
当踩完大大小小的坑,缓解了内存和 crash 问题之后,企鹅电竞在 weex 使用上又遇到了 2 大难题:
1. 调试困难
2. 页面加载慢
调试困难
weex 的页面并不能给前端的开发同学丝滑的调试体验。最开始前端同学是采用终端日志或者弹框的方式调试(心疼前端同学就这么学会了看 android 日志),后面通过再三跟 weex 团队的沟通,终于确定了 weex 和 weex_debuger 对应的版本,前端同学可以在 chrome 上面调试 weex 页面。
然而 weex_deubgger 并不是完美的解决方案,weex 本身是 jscore 内核,而 weex_debugger 只是通过 chrome 调试协议开了个服务,等同于使用的是 chrome 的内核,内核的不一致性无法保证调试的准确性。连 weex 的开发同学自己都说了会遇到 debug 环境和正式环境结果不一致的情况。
解决方案也很简单,那就是可以在 mac 的 xcode 和 safari 上面调试。当时由于替换 mac 的成功过高,就将就使用了 weex_debugger 的方案,后面怎么解决了相信大家心里有数。
页面加载速度慢
随着企鹅电竞业务的发展,很快前端同学就反馈过来,怎么 weex 页面打开的速度这么慢,这个菊花转了这么久。当时的内心是崩溃的,明明接入的时候好好的,一个页面轻轻松松 500-600ms 就加载回来了,哪里会有问题?
业务的发展速度永远是你想象不到的,2 个版本不到的时间,企鹅电竞中的 weex 页面轻轻松松从个位数突破到两位数,bundle 大小也轻轻松松从几十 kb 突破到了上百 kb,由此带来的问题是打开 weex 页面后能明显看到菊花转动了,甚至打开速度上还不如直出的 web 页面。
首先从数据报表中发现,页面打开速度中,1s 中有 300-400ms 是 bundle 从网络下载的时间,那是不是把这段时间省了,页面有轻轻松松回到毫秒级别打开速度了。
下图展示了预加载的整体流程。
[ 预加载流程 ]
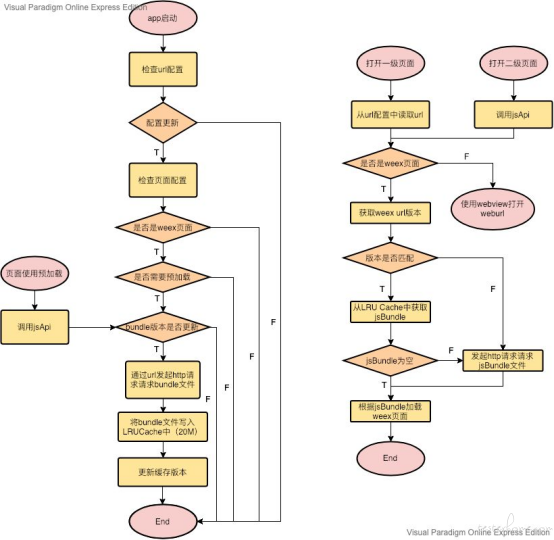
预加载方案上线后,页面成功节省了将近 200ms 的耗时。20M 的 LRUCache 大小也是参考了 http cache 的默认大小值,页面打开的预加载率在 75%-80%。
预渲染
做了预加载之后,很快又发现,就算没有网络请求,页面打开耗时还是超过了 1s。这种情况下,现有的方案已经无法继续优化页面。这个时候突然有了个想法,weex 本身是把前端的虚拟 dom 转化为终端的各种 view 控件,那么为什么 weex 页面的打开会慢终端页面打开这么多呢?
定义问题
解决问题之前,先来定义一下问题具体是什么。针对渲染速度慢,企鹅电竞对 weex 渲染的耗时定义如下:
· renderStart = 调用 WXSdkInstance.render() 的时间点
· httpFinish = httpAdapter 请求回来之后调用 WXSdkInstance.onHttpFinish() 的时间点
· renderFinish = 回调 IWXRenderListener.onRenderSuccess() 的时间点
· 页面打开耗时 = renderFinish - renderStart
· 网络耗时 = httpFinish - renderStart
· 渲染耗时 = renderFinish - httpFinish
所以之前的预加载,已经优化了网络耗时,但是渲染耗时在页面大了之后,依旧会有很大的性能问题。
为了揭开这个问题的本质,先来看一下 weex 整体的框架:
[ weex 框架图: ]

JSFrameWork
提供给前端的 sdk,对 vue 的 dom 操作做了各种封装,JSFrameWork 单独打包到 apk 包中。
JavaScriptCore
使用与 safari 的 JavaScript 引擎,专门处理 JavaScript 的虚拟机,对应 chrome 的 v8,功能可以大体联想成 java 的 jvm。
JSS
weex core 的 server 端,封装了对 JavaScripteCore 的调用,封装了 instance 的沙盒,多进程实现中,JSS 和 JavaScriptCore 的执行在另外的进程,防止 JS 执行异常导致主进程崩溃。
JSC
weex core 的 client 端,作为 WeexFrameWork 和 JSS 桥接层,另外从 0.18 版本开始,cssLayout 也下沉到了这一层。
WeexFrameWork
提供各种 sdk 接口的 java 调用,虚拟 dom 和 Android 控件树的转换,控件管理等。
了解完了 weex 框架,再把关注点转移到 js build 之后生成的 jsBundle,细心的同学肯定能够发现,生成的 jsBundle 本质上就是一个 js 方法,所以 weex 页面 render 的过程本质上是执行一个 js 方法。
针对企鹅电竞关注的游戏首页,对整个 weex 框架加了完整的打点,看到在 nexus 6 上面,对应的耗时以及整体流程如下图:
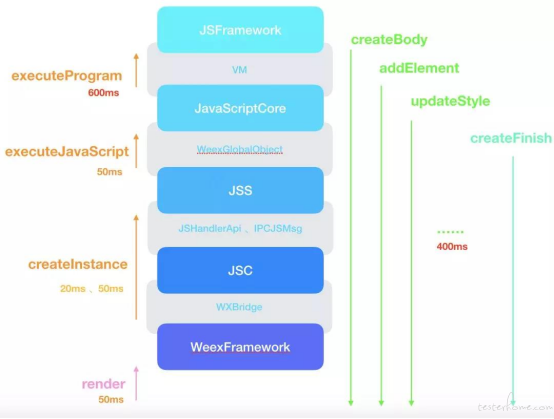
[ weex 执行流程以及耗时 ]
可以看到性能的热点主要在执行 js 方法以及虚拟 dom 的执行这两个关键步骤上,根据打点来看,单个 js 方法和单个虚拟 dom 的执行,耗时都很低。企鹅电竞抓了多次打点,看到启动时候执行 js 最慢的也仅仅是 3ms,大多数执行都在 0.1ms - 0 ms 这个区间。但是,再快的执行耗时,也架不住量多,同样以企鹅电竞游戏首页为例,启动的时候该页面执行的 js 方法多大 2000+ 个,这 2000+ 个方法执行再加上方法调度的耗时,能成为性能热点一点也不意外。而虚拟 dom 的执行也同理,单次执行经过 weex 团队的优化,执行耗时基本在 1ms-3ms 之间,但是同样的架不住量多以及线程调度的时间问题。
预渲染方案
了解 RN 的同学应该也知道,js 方法的执行和虚拟 dom 的执行是这种框架的核心所在,想要撬动整个核心,基本上难度等同于重写一个了。那么剩下的方案也就只有一个:提前渲染。
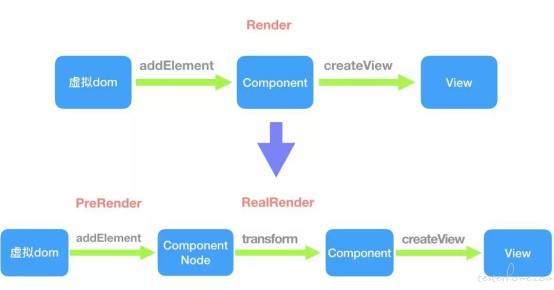
[ 预渲染 ]
预渲染的方案修改了 WeexFrameWork 虚拟 dom 和 Android 控件树转换的部分,在预渲染时,不生成真正的 component 和 view 结构,用抽象出来的 ComponentNode 存储虚拟 dom 的操作,并在 RealRender 的时候将 node 转换成一个个 component 以及 View。
这个方案的基本原理就是典型的以提前消费的空间换取时间,不去转换真正的 component 和 View 原因是 view 在不同 context 中的不可复用性以及 view 本身会占用大部分内存。
预渲染优化数据
内存消耗
提前渲染必然导致类内存的提前消耗,在 huawei nove3 上测试得到,预渲染游戏首页时的峰值内存会去到 10M,但是在最后预渲染完成后 GC 会释放这部分内存,最终常驻内存为 0.3M。 真正渲染游戏首页的内存峰值会去到 20M,最后的常驻内存为 5.6M。
可以看到预渲染对常驻内存的消耗极少,但是由于虚拟 dom 执行,导致峰值内存偏高,在某些内存敏感场景下,还是会有一定风险。
页面打开耗时
实验室中游戏首页的正常加载数据为 900ms(已经预加载,无网络耗时),经过预渲染,页面打开仅需要 150ms。
现网数据:
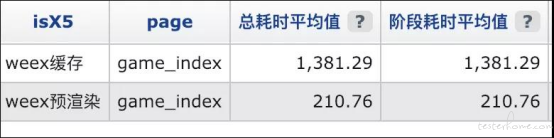
[ 预渲染页面打开上报 ]
最后,来两张优化前后的对比图:
[ 预渲染: ]
[ 非预渲染: ]