初衷
作者是在一家互联网金融公司上班的,IT 中加班做个排名的话,根据自己多年的从业经验自认为互联网金融可以排个前三吧。本人公司现状:一周一版本,每周版本迭代分到个人身上的任务平均 3-5 个不等,一般周五开发移交测试,周一环境冒烟,测试用例编写、评审,由于不同组都在一套环境测试,部署各种问题基本周一系统部署起来,数据冒烟通过,干不了什么测试的活;周二正式测试、和开发、业务沟通测试中问题,这天加班是必须的;周三测试 80% 的给业务准备验收数据或者配合业务造场景数据验收,这天加班也是常态;周四就各种回测测试(不限于 a 本周版本,分支控制可能上个版本漏归并问题,还得 b 回归上周版本内容,自己 c 负责系统、模块的回测),验收完当天就上线了。分析一波发现其实大部分的内容都是稳定的功能,可以考虑用自动化方式回归。
选型
自动化前期没多想就接口层面的吧,跑稳定了再补充点 ui 的自动化辅助。之前公司其实有一套接口自动化,自己也参与过建设,可以直接拿来用,主要是 python+openpyxl+pymysql+smtplib 这几个库写成的,由于用例编写是用可视化的文档管理,编写用例的人员很容易上手,测试结果也会回写到新的 excle,观察的测试结果也很直观,对维护用例的同学技术门槛比较低;优点也是它的缺点吧,用例较多,操作 excle,对程序的读写压力较多,效率比较慢,程序读数据的格式不好处理。社区找到了一个 star 特多的接口自动化框架-httprunner,看了下官方文档,发现它的用例维护是用 yaml 格式维护的,通过 yaml 库库轻松转换储层 json 格式的数据,而且最新版本的还接入了 allure 报告,是个不错的选择。结合公司业务,接口大部分参数需要直接通过数据库获得,结合以前的框架经验 +httprunner 设计用例的思想,决定自己整合下吧。
参数化设计
如果不考虑参数化的话 yaml 读出来的用例,组装一下就可以调用了。参数化方式多种多样,可以读文件、读数据库、读变量、读函数返回值等等;根据自己目前业务主要考虑设计以下几种:读数据库、读变量、读函数返回值,以后有需要其他方式也可拓展。yaml 写用例,我的理解是一个 key 就是一个关键字,参数需要先用一个关键字做个申明,让程序能够识别到它。大概设计思想:
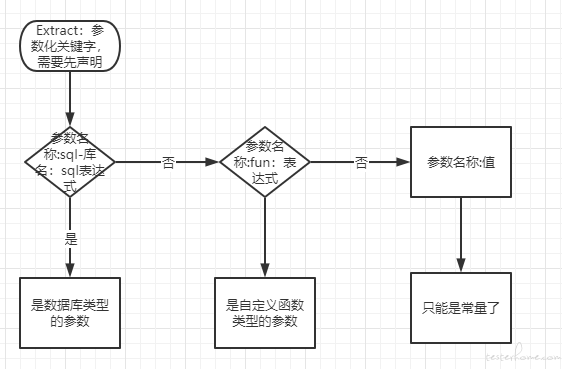
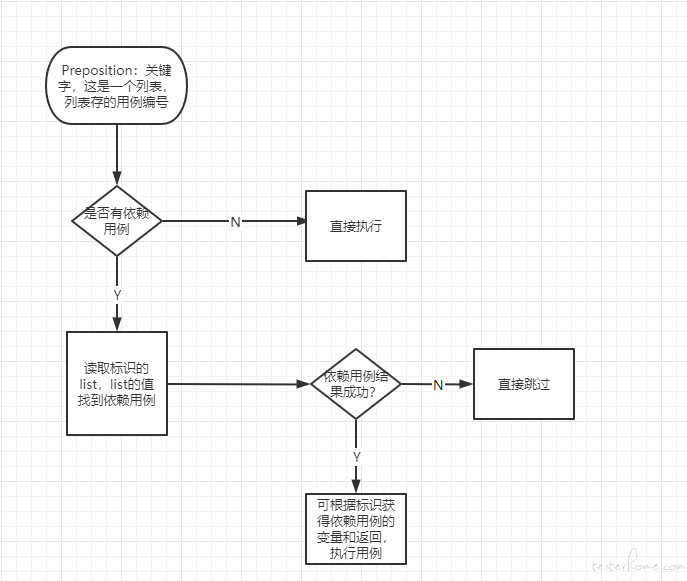
依赖用例设计
设计之初本来没考虑要依赖的,就想接触用例之间的耦合度,通过查数据库找自己的用例场景数据。但是有的场景在数据库找数据是在是不好找,必须要依赖其他的接口调用。这部分跟参数化设计差不多,先找个关键字告诉程序这个用例是有依赖其他用例的,然后根据关键字找到依赖用例列表,然后顺序执行依赖用例获取依赖用例响应和其使用到的变量,若依赖的用例响应结果是跳过(程序替换参数失败,或者用例编写格式不对,或者接口本身问题)或者失败了,那本用例不执行直接返回跳过;若依赖用例通过了,替换依赖用例的参数或结果后继续执行本用例。
多线程分发用例
简单思路。默认分创建 10 个线程,根据用例数均分,最后的那个吃点亏拿下剩余的用例消费。
99个用例,默认10个线程,怎么分发用例?简单整理
每个线程分的用例数:[10, 10, 10, 10, 10, 10, 10, 10, 10, 9]
线程对应用例索引下标:[[0, 9], [10, 19], [20, 29], [30, 39], [40, 49], [50, 59], [60, 69], [70, 79], [80, 89], [90, 99]]