部门开发的 app 春节期间进行了大规模的内部测试,因为之前项目之前没有做过性能测试,所以这次发现了不少问题。同时在网上搜关于 locust 压测的文章,好多都是基于 1.X 版本之前的,现在好多命令及写法都有调整。
简单记录一下自己根据春节内测的反馈,用 locust 实施性能测试的过程以及一些心得。
一、环境准备
我是在 linux 环境运行 locust 脚本的,linux 环境安装 python3 请参考
https://blog.csdn.net/zhangdongren/article/details/82685932
linux 环境装 py3 的时候务必要小心谨慎,不然很容易搞到 linux 环境命令都用不了,我之前按别的文章去装就掉坑里了。
最后,测试一下是否能访问到这台 linux 服务器的 8089 端口是否能访问
二、压测计划
根据春节期间的反馈,大家主要在产品列表、见证列表、抢红包三个操作的加载时间比较长,将这 3 个操作调用的接口作为此次压测的主要目标。
由于此次内部测试是在 uat 环境进行的,uat 环境有 103 个产品,远比未来预计上线的产品要多,但是内部测试人数比预计要能承受的并发人数少,需要对参数进行一些修改。
同时,查看 splunk 日志发现大量的 JDBC 连接失败。收集了一下报 JDBC 连接失败的接口

三、脚本准备
首先,locust 中的 Taskset 类是用来定义模拟用户的行为。一般我们会把待压测的接口内容写到这个类里面。Taskset 类里面有 2 个比较特殊的方法on_start和on_end。on_start在每次用户启动时执行,on_end在每次用户结束时执行。Taskset 类里面另一个比较重要的地方是@task修饰符,引用 locust 官网的说法:
Methods decorated with @task are the core of your locust file. For every running user, Locust creates a greenlet (micro-thread), that will call those methods.
@task修饰的方法是 locust file 的核心部分,每个运行的模拟用户,都会调用这些方法。可以将@task修饰的方法看作是一个事务。同时,@task修饰符还可以设置对应方法的权重。
从 1.x 的版本之后,locust 将 Httplocust 类改为了 Httpuser 类。现在如果是 1.x 的版本,用 locust 命令运行有 Httplocust 类的脚本会直接报错。User 类是用于定义虚拟用户的,而 Httpuser 类则是用于定义 User 类下面 Http 请求的虚拟用户。Httpuser 类下面主要设置等待时间wait_time = between(min, max)和设置运行的 Taskset 类tasks = {类名},也可以在 Httplocust 类定义各 Taskset 类的执行比重:
class WebsiteUser(HttpUser):
wait_time = between(5,6)
tasks = {
login:1000,
confirm:500,
trade:500
}
最后说一下参数化,现在直接去网上搜 locust 参数化甚至你在 TesterHome 里面搜,搜到的基本都是 1.x 版本之前的参数化操作,让你用 queue 队列,然后在 Taskset 类中使用self.locust.队列名.get()方法获取传参,这个方法在 1.x 版本中使用会报错。最后终于在官网的 Changelog 里面找到了
We’ve renamed the Locust and HttpLocust classes to User and HttpUser. The locust attribute on TaskSet instances has been renamed to user.
现在要将self.locust.队列名.get()改为self.user.队列名.get()
以我自己的脚本为例,我这边遍历 test 环境的所有用户(不循环去取)去交易同一个订单:
class UserBahavior(TaskSet):
@task
def confirm(self):
try:
userid = self.user.userid_list.get()
print(userid)
except queue.Empty:
print('no data exist')
exit(0)
self.client.post('/pay/tx/confirm',json={
"sn": "1602484897148264",
"cc": "be940caa5c6c0bbd1608950b27e59fe2",
"os": "100",
"source": 5,
"devId": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"udid": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"uid": userid,
"ip": "183.62.131.138",
"data": {
"orderId":93,
"isAgreed": 1
},
"version": "10.0",
"appVersion": "1.0",
"MFR": "apple",
})
class WebsiteUser(HttpUser):
wait_time = between(5,6)
tasks = {UserBahavior}
userid_list = queue.Queue()
for i in range(1,97):
userid_list.put_nowait(i)
如果要改成循环去取,TaskSet 类里面的方法每次从队列里取完数后,再加回去就可以。
还是上面的脚本,只需加一行代码即可:
class UserBahavior(TaskSet):
@task
def confirm(self):
try:
userid = self.user.userid_list.get()
print(userid)
except queue.Empty:
print('no data exist')
exit(0)
self.client.post('/pay/tx/confirm',json={
"sn": "1602484897148264",
"cc": "be940caa5c6c0bbd1608950b27e59fe2",
"os": "100",
"source": 5,
"devId": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"udid": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"uid": userid,
"ip": "183.62.131.138",
"data": {
"orderId":93,
"isAgreed": 1
},
"version": "10.0",
"appVersion": "1.0",
"MFR": "apple",
})
self.user.userid_list.put_nowait(userid)
class WebsiteUser(HttpUser):
wait_time = between(5,6)
tasks = {UserBahavior}
userid_list = queue.Queue()
for i in range(1,97):
userid_list.put_nowait(i)
从前面请求的响应报文中,获取某个字段来进行参数化:
class UserBahavior(TaskSet):
def mobile_login(self):
js ={
"sn": "1602295033826",
"cc": "b83349e2ea84ce1b656e9ce01aff1e28",
"os": "400",
"model": "MI8SE",
"channel": "pycredit",
"source": 4,
"ip": "183.62.131.138",
"data": {
"mobile": "13543296510",
"code": "666666",
"codeId": "-1",
},
"version": "10.1",
})
res = self.client.post('/app/login/sms',json=js).text
uid = res['data']['uid']
return uid
@task
def confirm(self):
userid=self.mobile_login()
self.client.post('/pay/tx/confirm',json={
"sn": "1602484897148264",
"cc": "be940caa5c6c0bbd1608950b27e59fe2",
"os": "100",
"source": 5,
"devId": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"udid": "6617DD18-6BA3-4F49-B67E-7000420BEB69",
"uid": userid,
"ip": "183.62.131.138",
"data": {
"orderId":93,
"isAgreed": 1
},
"version": "10.0",
"appVersion": "1.0",
"MFR": "apple",
})
四、脚本调试
脚本编写完成后,需要进行一下调试,看是否有达到自己的预期。
结合日志,查看 log 里面,压测的这些传参是否有问题。由于我一开始的传参没设置成 json 格式,导致接口的报文返回 “系统有点忙”,在 Splunk 里面查到请求日志:

所以大家不要匆忙地开始压测,要先检查下日志看下自己压测的请求是否有问题。
五、分布式运行
1.x 版本的分布式运行命令也与之前有点小变化:
通过--master 启动 master 节点
locust -f my_locustfile.py --master
通过--worker 启动分布式工作模式,每个 worker 相当于 slave 机
1)通过 master 机 ip
locust -f my_locustfile.py --worker --master-host=192.168.232.134
2)通过 master 机端口
locust -f my_locustfile.py --worker --master-port=5557
六、服务器及数据库监控
我使用的是 node_exporter+prometheus+grafana 的组合:
在需要性能监控的服务器上装 node_exporter
在 prometheus.yml 文件中添加相应的配置:

通过配置去启动 prometheus:
./prometheus --config.file=prometheus.yml`
在 grafana 中添加 Database(以 prometheus 作为 Database):
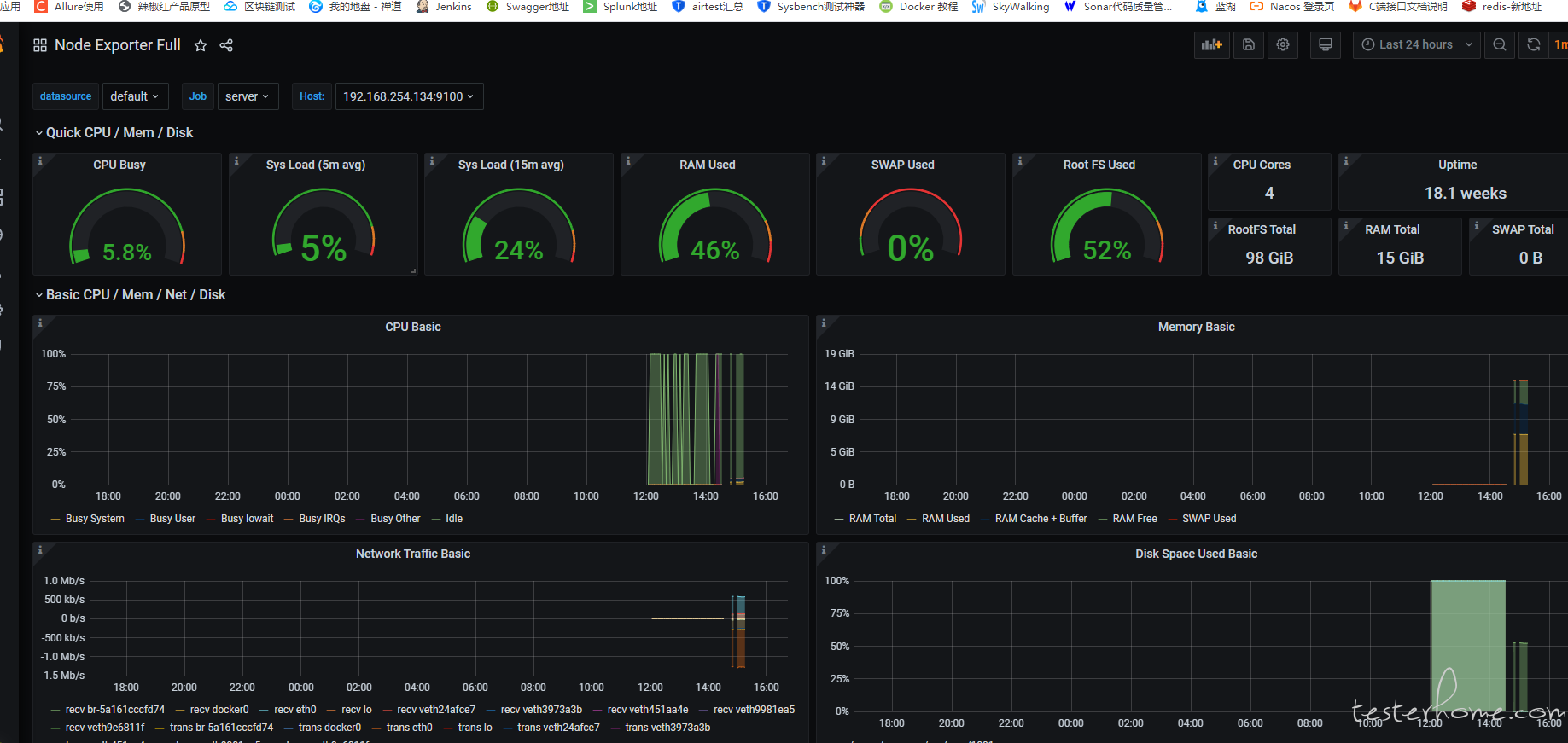
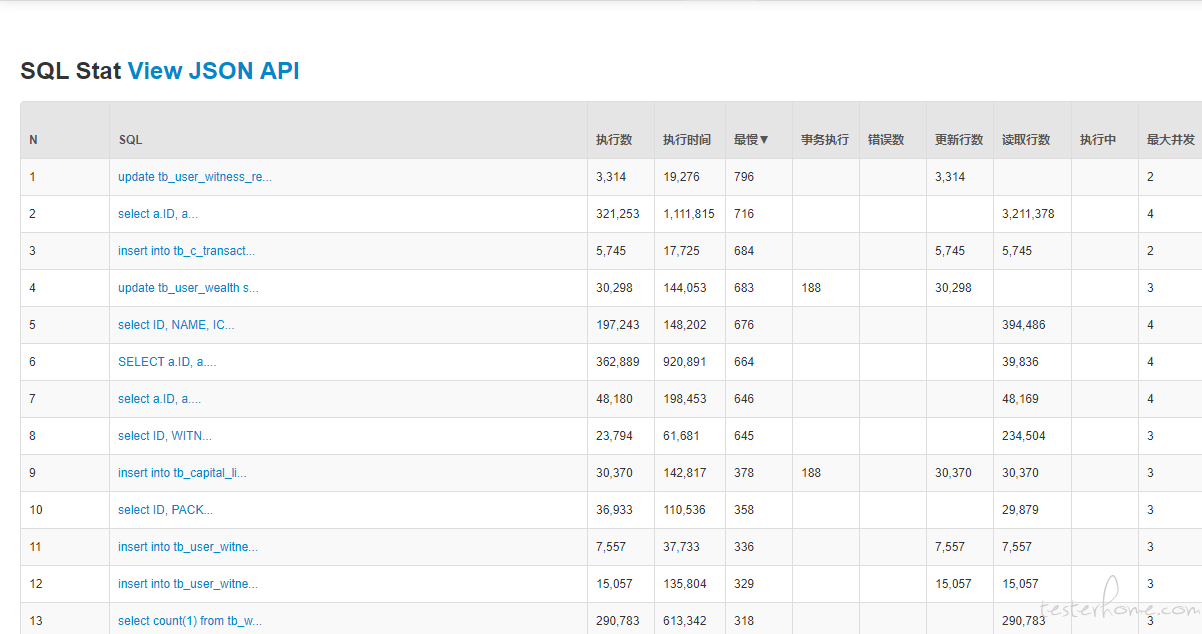
数据库连接我是用 druid 去看的,统计那些速度比较慢或者读取行数特别多的 sql 发给开发去进行调优: