性能常识 线下混合场景压测方法指导
线下混合场景压测方法指导
1、为什么要编写此文档
2、为什么要做混合场景压测
3、混合压测数据准备
3.1 数据分析
3.1.1 铺底数据
3.2 数据准备
3.2.1 铺底数据准备
3.2.2 测试数据准备
4、混合场景如何设计
4.1 混合压测业务占比分析
4.1.1 有生产历史数据的系统
4.1.2 没有生产历史数据
5、如何开展混合压测
6、结果分析
1、为什么要编写此文档
帮助大家快速了解如何开展混合场景压测任务
2、为什么要做混合场景压测
线下压力测试场景 需要模拟生产环境真实用户访问情况,多用户同时访问系统会调用系统各个接口,对各个系统产生并发压力;单个接口无法模拟多用户真实行为,所以需要根据用户行为进行数据建模,设计混合测试场景进行压测,从而保障系统性能稳定性。
从影响面考虑
(1) 用户量:线上环境为多用户访问,线下需要设计用户数据模型
(2) 请求接口量:线上多接口同时访问,线下需要考虑接口占比
(3) 耦合系统或组件:线上系统架构比较复杂,公共系统涉及相关调用情况需要考虑,如定时任务、异步线程等,相互耦合的系统对应接口需要混合压测
案例:
举例说明:如下图所示,是一个电商的系统架构概要图
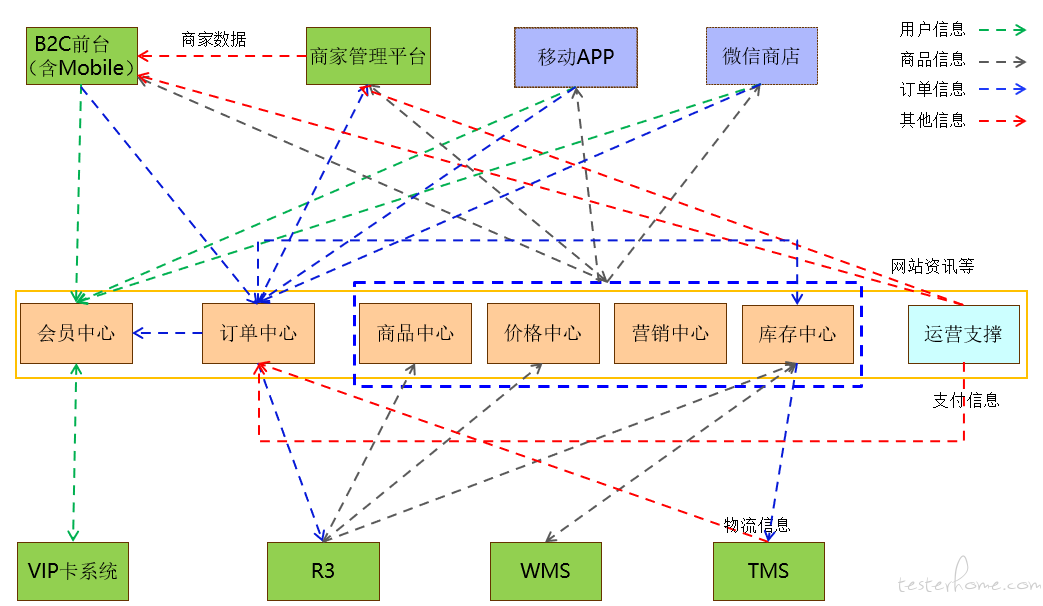
(1):用户既包括从 C 端来的个人用户,也包含系统本身的操作类用户,其中有注册用户,活跃用户之分,混合压测的时候需要考虑用户模型。
(2):接口既包括从 B2C,APP,小程序,等流量入口的访问,也包含内部关联系统之间的交互,例如库存中心和 TMS 物流中心的交互
(3):耦合系统及组件:A:当有提交订单的时候,即会有库存的锁定,这时候即一定会有出库等操作,对应 TMS 即会有相关信息消费等;
定时任务: B:R3 通过定时任务的方式同步相应的价格信息给价格中台
3、混合压测数据准备
3.1 数据分析
压测数据主要分 2 块
- 3.1.1 铺底数据
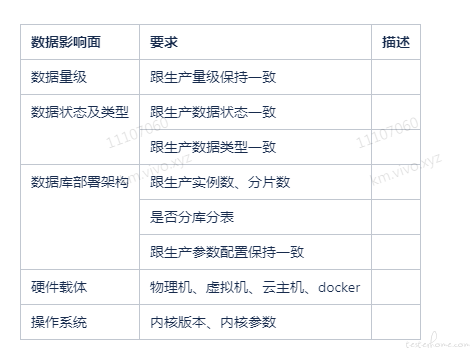
所谓铺底数据,就是压测环境系统中,存储里存放的数据,此数据理论上要求跟生产数据模型保持一致,即数据量大小,数据分布(时间分布、状态分布)情况、数据存储服务器架构环境等都需要跟生产环境保持一致;
铺底数据主要考虑以下因素
- 3.1.2 测试数据
所谓测试数据,就是我们跑每个测试场景需要准备的数据,测试数据需要考虑点如:
(1) 测试数据量级
(2) 数据状态及类型分布
(3) 涉及到分库分表,测试数据是否需要在多库多表内均匀分布
(4) 涉及到缓存,也需要考虑多实例数据是否均匀分布
3.2 数据准备
- 3.2.1 铺底数据准备
数据库搭建完成后,需要我们构造跟生产环境类似的数据模型,准备数据方法有几种
第一种:从真实环境中导出数据并脱敏,这种方式是最推荐的一种数据准备方法
第二种:在数据库中直接插入数据。
第三种:通过调用接口 api 方式准备数据,需要注意几点:
1、 文档 3.1.1 内容;
2、 时间效率方面,如果构造压测数据要花个几天时间,那这种方法分析下是否可行
-
3.2.2 测试数据准备
有了铺底数据以后,测试数据主要从铺底数据里获取
数据准备方法请参考

4、混合场景如何设计
4.1 混合压测业务占比分析
- 4.1.1 有生产历史数据的系统
是从生产历史数据来分析,进而推断业务模型;早期性能测试人员会通过分析历史数据来设计业务模型,不过近些年链路追踪(如 zipkin、pinpoint、调用链等)系统发展比较成熟,各个公司都有自己的 trace 系统, 对于我们 XX 公司来说, 可以借助调用链帮助我们拉取过去一段时间生产环境用户访问(系统接口)数据;
从业务类型维度分析思路如下:
业务类型:非活动类业务【线上不会出现业务突变情况】
评估策略:通过调用链统计接口请求总量占比作为压测业务占比
数据采集时间段:过去 7 天(建议采集建模的业务数据以峰值段为准,从天到时段。)
采集内容:XX 接口请求总量
业务类型:活动类业务【线上极可能出现业务突变情况】,如 xx 春节发红包活动。运营 push 活动等
评估策略:根据业务漏斗图【见 4.1.2 小节】分析接口占比作为压测业务占比
说明:对于全新活动,无历史数据的业务,需要参考业务漏斗图分析【见 4.1.2 小节】,对于有历史数据的活动,需要参考过去活动的调用链数据进度分析
以 XX 首页混合压测为例,最近 7 天 XX 首页各接口流量占比:
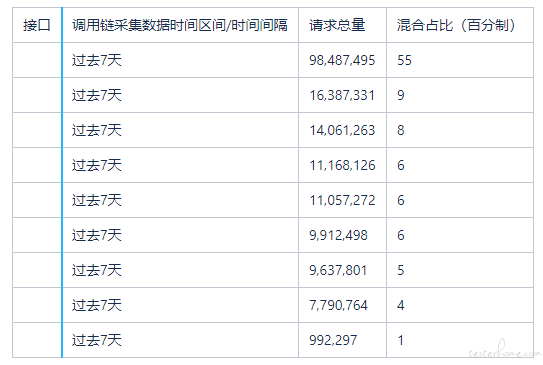
其他的接口 7 天请求总量小于 990,000 ,混合占比小于 1,忽略不计;
- 4.1.2 没有生产历史数据
首先需要产品给出业务漏斗图;
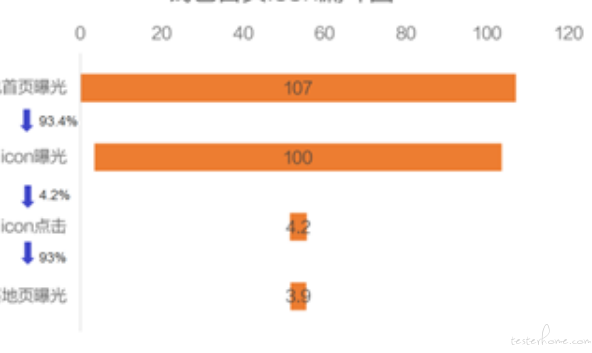
根据以上漏斗图可理解为:
xx 首页曝光是一级页面、
icon 曝光是二级页面、
icon 点击是三级页面、
落地页曝光是四级页面。
一级页面到二级页面转化率是 93.4%,
二级页面到三级页面转化率是 4.2%,
三级页面到四级页面转化率是 93%,
蓝色箭头的百分比即为转化率。
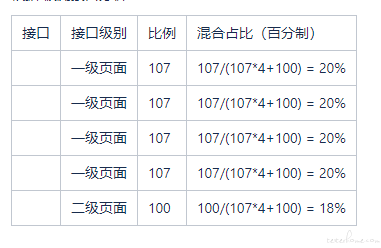
一级页面:二级页面:三级页面:四级页面占比=107:100 :4.2 :3.9。
根据 被测接口分析
5、如何开展混合压测
5.1、混合压测脚本编写
略过
6、结果分析
- **1、接口性能是否达标
(1)每个接口都要满足性能目标
(2)系统无性能问题
