背景
快驴 APP 内有许多瞬时弹窗,和一些图片,其中一个功能验证点是如何验证其文案是否正确(如限购标签),单纯的用 appium-inspector 是不能对其进行定位的,那么在执行 UI 自动化时,如何对其进行校验呢?
思路
Java 中开源的 tesseract(Tesseract 是一个 OCR 库,光学字符识别 (Optical Character Recognition, OCR),也叫文字识别,可以处理很多自然语言,比如中、英文等)
Mac 下的环境配置:
安装 tesseract
brew install tesseract
查看本地存在的语言库(按照上述命令安装后的语言包里默认有 eng 英文包)
tesseract --list-langs
简体中文(chi_sim.traineddata)语言包下载地址(注意下载的语言包要和你的 tesseract 版本相对应): https://tesseract-ocr.github.io/tessdoc/Data-Files
实际应用:
在点击快驴进货 APP 中的商品详情页里的加入常买时,断言是否有 “已加入我常买” 的瞬时文字弹窗出现。
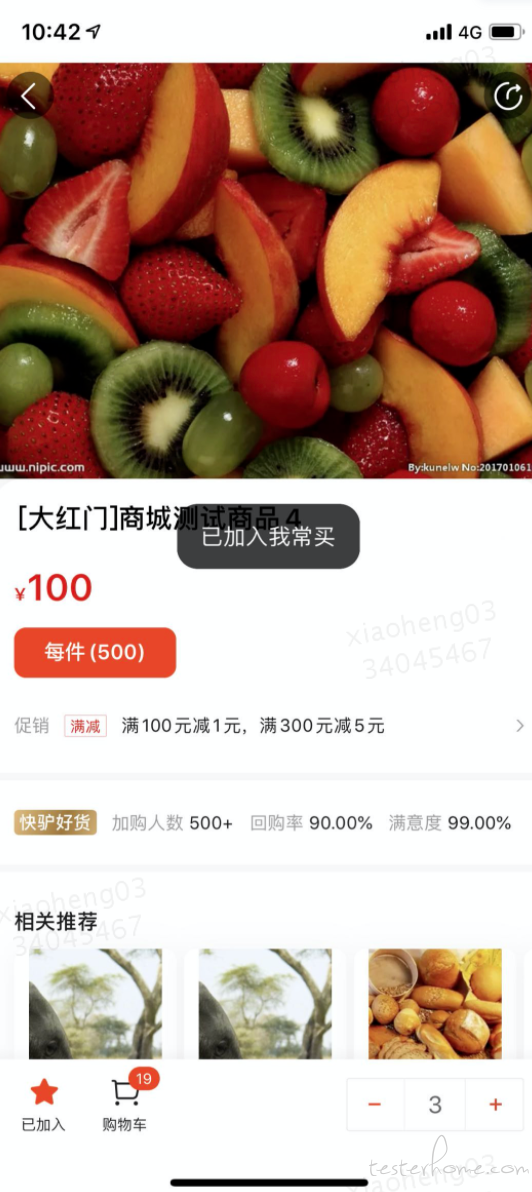
直接识别:
因为此时要识别的内容是汉字,所以用简体中文语言包。其中-l chi_sim 表示用简体中文字库
tesseract 我常买弹窗.jpeg 我常买弹窗 -l chi_sim
识别结果如下:
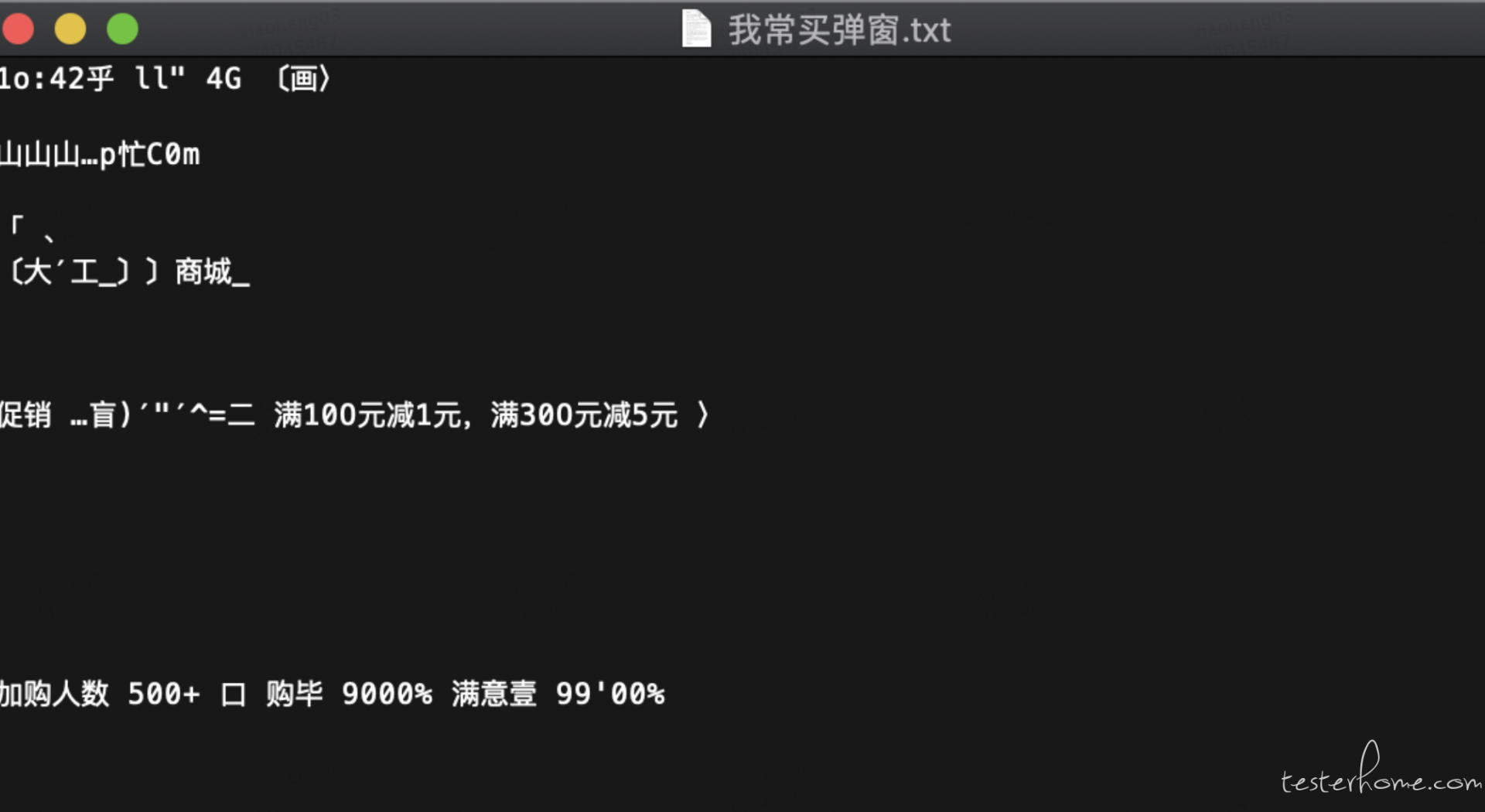
从上图的识别结果可以看出,没能识别出期待断言的文字,即 “已加入我常买”。
如何提高识别率?(官网上的一些思路:https://tesseract-ocr.github.io/tessdoc/ImproveQuality)
1、Rescaling(尺度化)
可应用到实际业务中
首先在直接用上述命令识别图片里的内容时,遇到下面这样一个提示:Warning: Invalid resolution 0 dpi. Using 70 instead.

Tesseract 对于 dpi >= 300 的图片有更好的识别效果。所以在识别之前将图片调整到合适的尺寸有助于提高识别效果。(DPI:Dots Per Inch,每英寸点数,图像每英寸长度内的像素点数)
tesseract 我常买弹窗_300dpi.jpeg 我常买弹窗_300dpi -l chi_sim
2、Binarisation(二值化)
可应用到实际业务中
在这里先用 Python 里的 opencv 对其二值化(将整个图像呈现出明显的黑白效果的过程),然后用 tesseract 来识别的
def gray_scale(img_src_path, img_dst_path):
"""
:param img_src_path:图片的源路径
:param img_dst_path:灰度化的图片路径
:return:img_dst_path
"""
img = read_img(img_src_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imwrite(img_dst_path, gray)
return img_dst_path
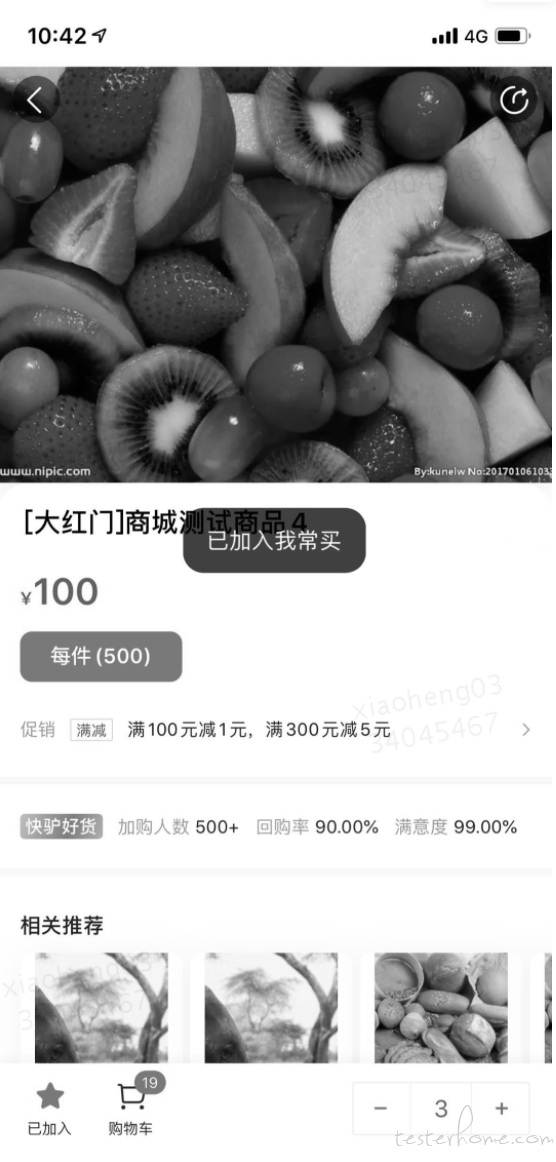
tesseract 我常买弹窗_gray_scale.png 我常买弹窗_gray_scale -l chi_sim
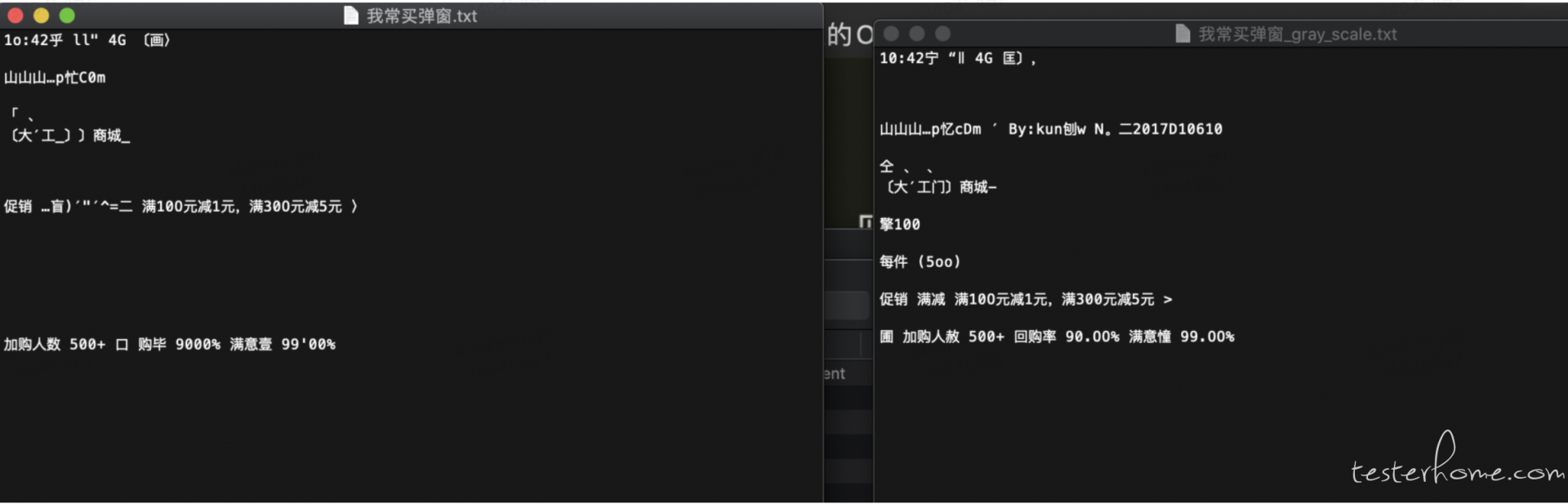
从上图的对比中可以看到经过二值处理后的图片识别出来的结果变多
3、Noise Removal(去噪)
噪声是图像亮度或颜色的随机变化,会使图像的文本更难阅读。在二值化步骤中,某些类型的噪声无法通过镶嵌消除,这可能导致准确率下降。
但是在 APP 内的截图基本都没噪声,采用对 APP 内的图片去噪的方式来提高识别率基本没效果。
4、Dilation and Erosion(膨胀与腐蚀)
粗体字符或细字符(特别是带有衬线的字符)可能会影响对细节的识别,并降低识别精度。许多图像处理程序允许在一个共同的背景下对字符的边缘进行膨胀和侵蚀,从而使字符的大小(膨胀)或缩小(侵蚀)。历史文献中大量的墨水流失可以用腐蚀技术来弥补。侵蚀可以用来缩小字符的正常字形结构。
但是在 APP 内截图中的文字没上面这种情形,采用对 APP 内的图片图像膨胀与腐蚀的方式来提高识别率基本没效果。
膨胀:将图像的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大,线条变细
腐蚀:将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小,线条变粗
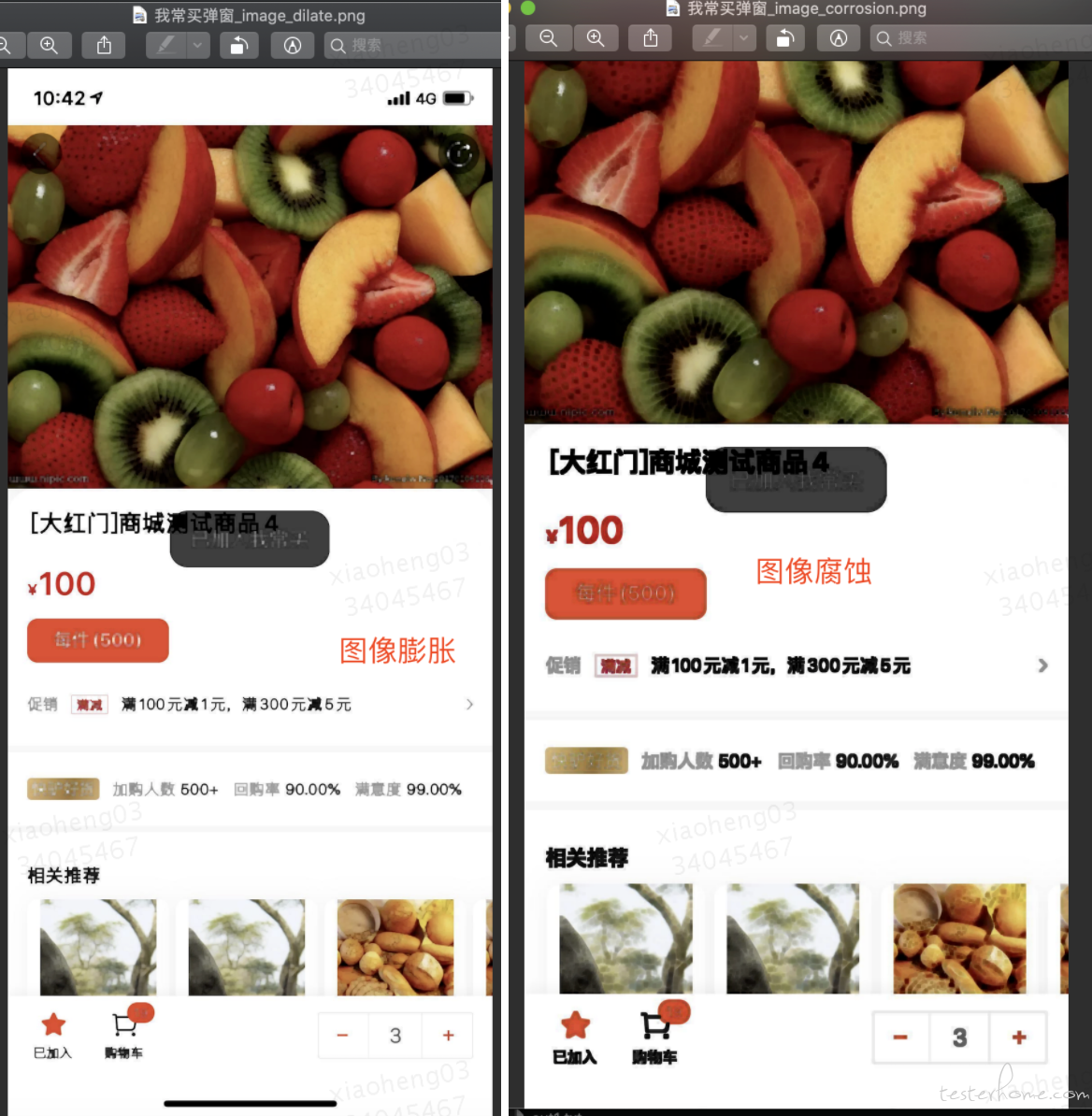
通过 tesseract 用以上两种图像预处理的方法对图片处理后识别的结果也不理想,不能识别出期待的内容:已加入我常买
5、Rotation / Deskewing(旋转/反旋转)
歪斜图像是指页面扫描不直的情况。如果页面倾斜过大,则 Tesseract 的行分割质量会显著降低,严重影响 OCR 的质量。若要解决此问题,请旋转页面图像,使文本行水平。
可以针对倾斜文字提高识别率
但是在 APP 内的截图里的文字基本都没倾斜,采用对 APP 内的图片旋转/反旋转的方式来提高识别率基本没效果。
6、Borders(边框)
Scanning border Removal(删除扫描边框)
扫描的页面周围通常有深色边框。这些字符可能会被错误地选作额外字符,尤其是在形状和层次不同的情况下。
但是在 APP 内的截图里基本都没深色边框,采用对 APP 内的图片删除扫描边框的方式来提高识别率基本没效果。
前面这六种都是官网上有的
7、图片切割
下图是对原图切割后的图片

tesseract 我常买弹窗_small.png 我常买弹窗_small -l chi_sim
识别结果如下:

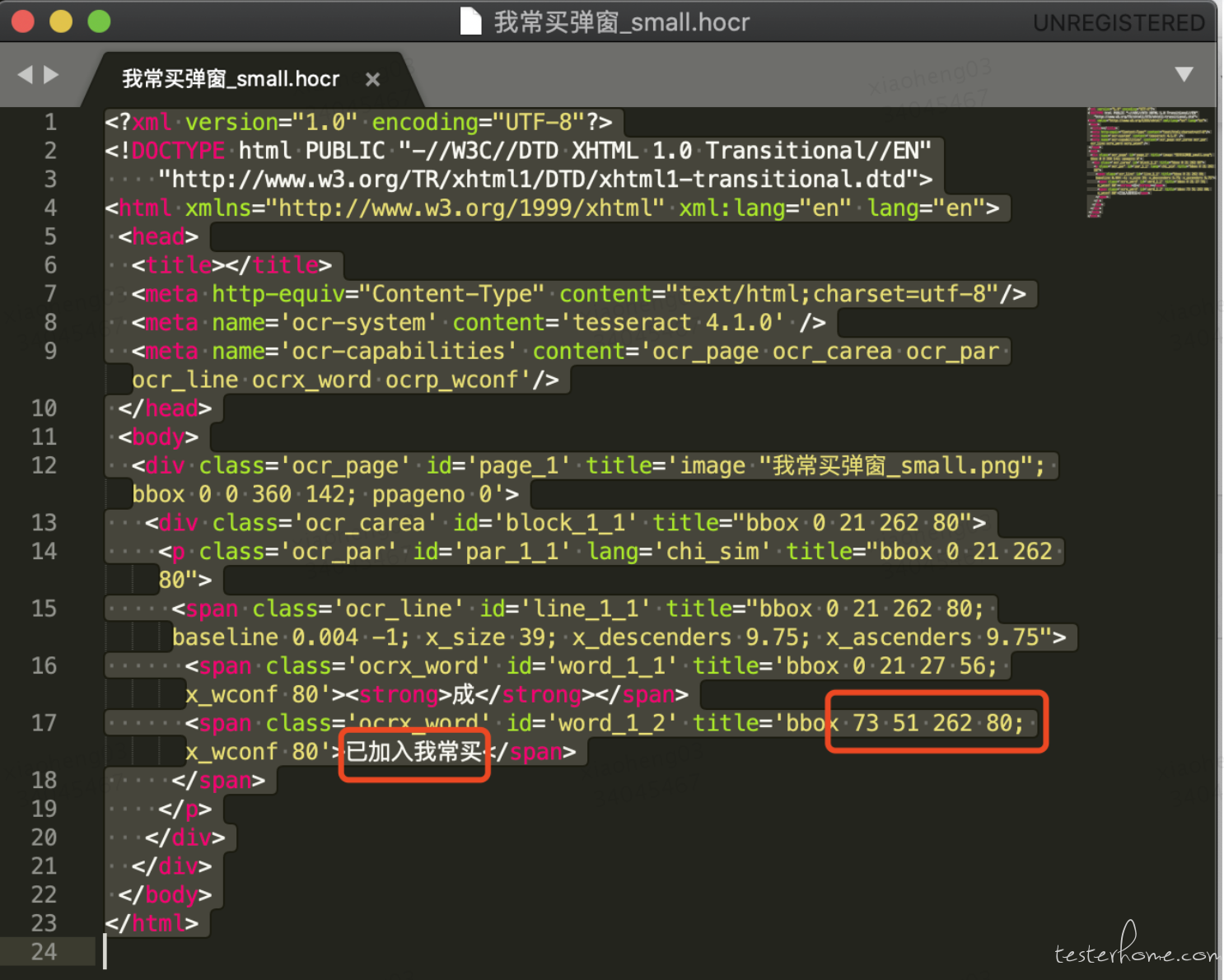
如果想得到识别出来的内容在待识别图片上的坐标的话,可以加 hocr 参数(html 文件)
tesseract 我常买弹窗_small.png 我常买弹窗_small -l chi_sim hocr
得到的识别结果如下:其中 x_wconf 80 就是信心值了,bbox 后面的就是其相对截图左上角的坐标了
可应用到实际业务中
8、选择合适的字体库来识别
如果想识别的内容是英文的话,用英文库识别效果更佳
可应用到实际业务中
总结
在识别 APP 内图片里的文字时,可先自动采用尺度化,然后根据实际情形结合二值化、图片切割、选择合适的字体库识别方法来提高 OCR 识别率。