AI测试 AI 模型常见的评价指标汇总
在进行算法模型测试时,通常需要依据各种评价指标,这里汇总一些常见的评价指标。
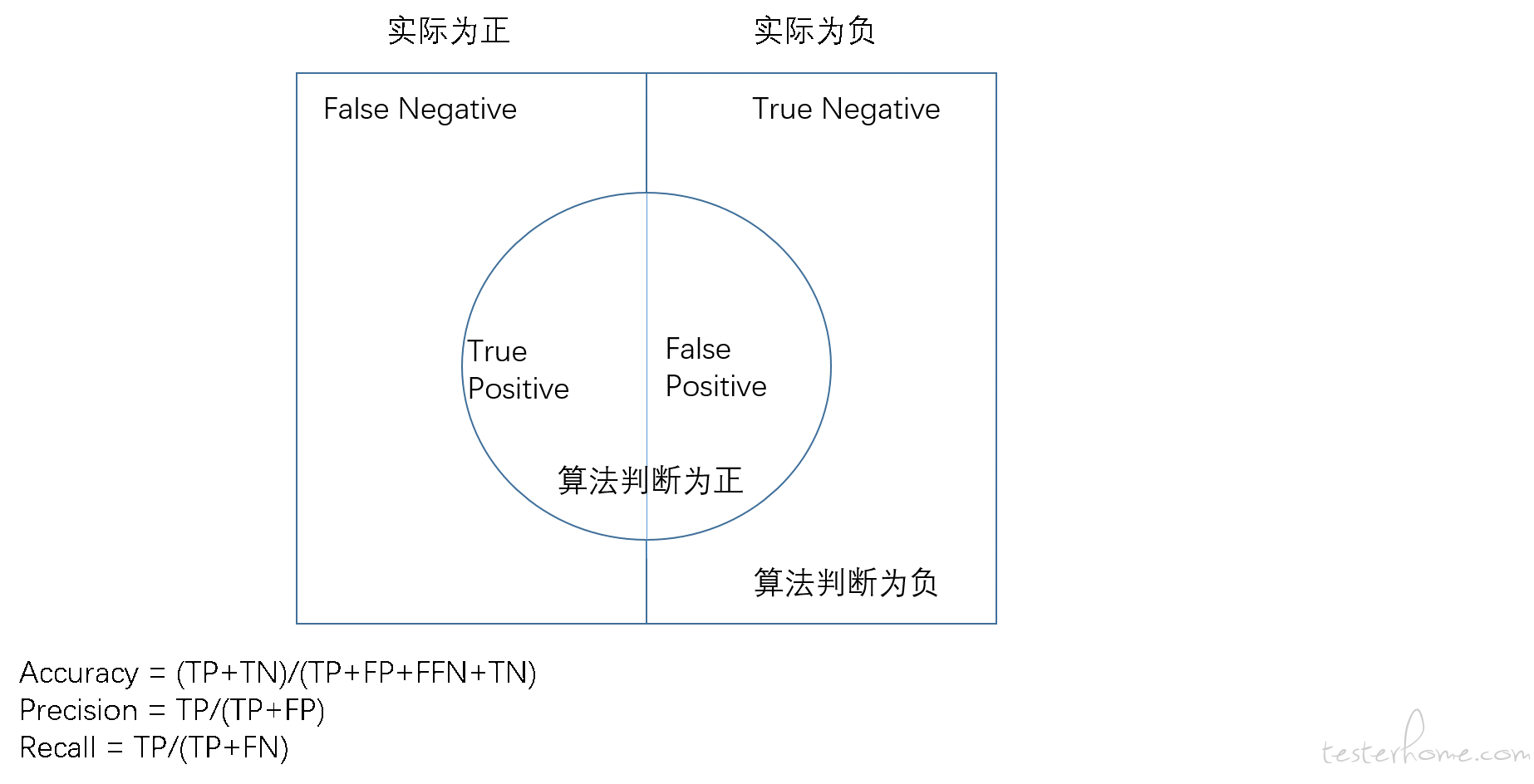
算法模型的任务通常是进行识别或者分类。对于这类任务来说,最终的结果可以分为如下四类:
TP(True Positive):预测为正,实际为正
FP(False Positive):预测为正,实际为负
TN(True Negative):预测为负,实际为负
FN(False Negative):预测为负,实际为正
其中 TP 和 TN 都表示预测结果和实际结果一致,FP 和 FN 表示预测结果和实际结果不一致。再次基础上,可以使用如下评估指标:
召回率:也叫查全率或者 Recall,计算公式为:R = TP / (TP+FN)
召回率的本质可以理解为模型找到数据集中所有感兴趣的数据点的能力。衡量的是模型的查全率。
查准率:也叫精准率,计算公式为:P = TP / (TP+FP)
查准率表达的是模型找到数据点中实际相关的比例。它是指检索出的正确的正例点与检出的所有正例点总量的比例,用于衡量模型检出正例点准确度的尺度。
精度 - 召回率之间存在制衡:随着精度的增加,召回率会降低,召回率增加,精度就会降低。这个可以这样理解:
召回率提高,说明在所有的正样例中发现正样例的能力比较强,那就是说模型倾向于将负样本也判断为正样例,那么精度就会降低。
精度提高,模型可以只将一个正样本预测正确即可,其余的样本可以都预测为负样本,那么此时精度为 100%,但是在众多的正样本中,只找到了一个正样本,召回率就很低。
比如说在极端情况下,模型将所有的样例都判断为正样例,根据召回率的公式 R = TP / (TP+FN),其中 FN=0,因为没有被预测为负的样本,则该模型的召回率为 100%,即把所有实际为正的样本都找到了。但是模型的查准率会很低,因为样例中所有的负样本也都被预测成了正样本,根据查准率的公式 P = TP / (TP+FP),分母中的 FP 会很大。
阴性预测值(NPV):这个可以理解为负样本的查准率,计算公式:NPV = 正确预测到的负例数/预测为负例的总数 = TN/(TN+FN)。
F1 Score:
上面介绍的都是一些单一指标,因为有些指标之间是有制衡的,为了得到一个精度和召回率比较好的组合,可以使用 F1 score 进行判断。
F1 score 是对精度和召回率的调和平均:
F1 score = 2*(precision * recall) / (precision + recall)
使用调和平均而不是简单的算数平均的原因是:调和平均可以惩罚极端情况。一个具有 1.0 的精度,而召回率为 0 的分类器,这两个指标的算术平均是 0.5,但是 F1 score 会是 0。F1 score 给了精度和召回率相同的权重,它是通用 Fβ指标的一个特殊情况,在 Fβ中,β 可以用来给召回率和精度更多或者更少的权重。(还有其他方式可以结合精度和召回率,例如二者的几何平均,但是 F1 score 是最常用的。) 如果我们想创建一个具有最佳的精度—召回率平衡的模型,那么就要尝试将 F1 score 最大化。
当召回率和查准率的重要性不同时,F1 度量的一般形式是:
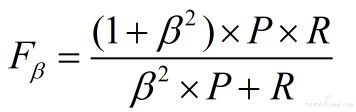
其中β表示召回率 和查准率的权重。
β=1,召回率权重=查准率权重,就是 F1
β>1,召回率权重>查准率权重
β<1,召回率权重<查准率权重