Selenium Selenium:xPath 定位实践
使用过 selenium 的朋友相信都了解 selenium 给用户提供了几种不同的元素定位方式。
今天在这里我们不讨论几种定位方式的优劣,只针对性的讨论 xpath 的使用方法与一些技巧。本人一直是坚定的 xpath 党,定位方式非常灵活,而且运用熟练了之后,还可以对 UI 自动化的 PO 模式进行扩展。
绝对路径 vs 相对路径
相对其他定位方式来说,xpath 的使用有一定的门槛,刚开始接触时可能只会通过浏览器的定位元素功能直接复制 xpath 绝对路径,比如这样的
/*[@id="root"]/section/div[1]/div/div/div/form/section[1]/div[2]/ul/li[1]/button
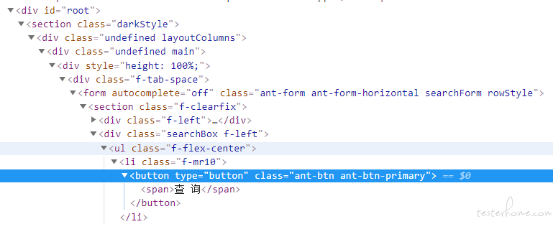
这样的绝对路径 xpath 至少存在两个方面的问题
1、可读性和可维护性很差,这一长串路径看得人眼睛都花,别说维护了。
2、健壮性差,现在的前端框架很多元素都是根据实际业务动态生成的,而页面元素结构稍微变化,继续使用绝对路径就可能会定位不到元素了。
所以说,想要使用 xpath 进行定位,使用绝对路径是肯定不行的。而是用相对路径就要求我们必须对 xpath 有一定的了解,xpath 的几个关键知识离不开以下两个方面
1、xpath 提供的各种函数
2、xpath 轴
我们再来分析一下上面这个 button 元素
首先它是在一个 id 为 root 的 div 容器里中一个 form 表单的子元素
button 的子元素是一个 innerText 为【查 询】的 span
我们可以把上面的 xpath 改造一下
//div[@id='root']//span[text()='查 询']/..
然后按 F12 打开 Chrome 浏览器的控制台,切换到 elements 标签,按 Ctrl+F 激活查询对话框,将 xpath 输入到搜索框中,可以看到浏览器定位到了这个 button 元素
这样我们就通过 xpath 的相对定位定位到了这个 button 元素,并且忽略掉了 DOM 树中大部分中间层级

可以看到通过使用 xpath 的相对路径和过滤功能使 xpath 表达式简洁了很多,并且因为忽略了中间层级,对 DOM 树结构的稳定性依赖降低了很多。
Xpath 使用介绍
由于 XML/HTML 文档都是树形结构,文档中的每一个元素对象都是树形结构中的一个节点,xpath 就是帮助我们来对树形结构中的节点进行精确定位的语言
那么,我们在做 UI 自动化时需要掌握哪些与 xpath 定位相关的知识点呢?
1、路径表达式
【.】表示当前节点,xpath 以 . 开头的话 即表示这是根节点
【..】表示当前节点的父节点
【/】表示选取当前节点的下一级节点
【//】表示选取当前节点的所有下级节点
【@】表示选取节点属性
【text()】表示选取节点文本
2、谓语
谓语被括在方括号中,可以视为查找元素的过滤条件,常见的有
使用节点属性过滤 如 .//div[@title='xpath 定位']
使用节点索引过滤 如 .//div[1] 索引下标从 1 开始
使用节点文本过滤 如 .// div[text()='xpath 定位']
3、运算符
[+] 加 [-] 减 [] 乘 [div] 除
[=] 等于 [!=] 不等于 [<] 小于 [ >] 大于
[and] 与 [or] 或
[|] 多节点选取
**4、函数*
xpath 支持的函数非常多,我们在这里只讨论 UI 自动化测试中常用到的函数,
另外由于主流浏览器现在都不支持 xpath2.0,所以我们的讨论范围仅限于 xpath1.0
contains(str1,str2) 如果 str1 包含 str2,则返回 true,否则返回 false
substring(str,start,len) 返回从 start 位置开始的指定长度的子字符串。第一个字符的下标是 1
string-length(str) 返回指定字符串 str 的长度
normalize-space(str) 删除指定字符串的开头和结尾的空白,并把内部的所有空白序列替换为一个,然后返回结果
starts-with(str1,str2) 如果 str1 以 str2 开始,则返回 true,否则返回 false
ends-with(str1,str2) 如果 str1 以 str2 结尾,则返回 true,否则返回 false
not(arg) 返回参数 arg 的相反的布尔值
5、轴 (列举几个常用的)
ancestor 选取当前节点的所有先辈(父、祖父等)。
preceding-sibling 选取当前节点之前的所有同级节点。
following-sibling 选取当前节点之后的所有同级节点。
轴使用语法为 : 轴名称::元素 xpath,
比如 .//div[@id='1']//following-sibling::input[@name]
表示选取 id 为 1 的 div 元素之后同级的所有带有 name 属性的 input 元素
实例 : 用 Chrome 打开猎聘的首页 https://www.liepin.com
首先 ,尝试定位首页的搜索输入框元素

按 F12 打开 Chrome 开发工具,查看该元素属性

切换到 Console,输入 $x(".//input[contains(@placeholder,'输入职位关键词')]")

可以看到 定位到了两个 input 元素,把鼠标移动到第一个 input 元素上,搜索栏元素激活,第二个是一个相同的 input 的元素但是当前是隐藏状态
然后,我们吧 xpath 改一下,指定取第一个匹配到的元素,这样就可以精确匹配到这个搜索输入框了

如果不希望使用写死索引的方式定位,我们可以再分析下这两个 input 有什么区别
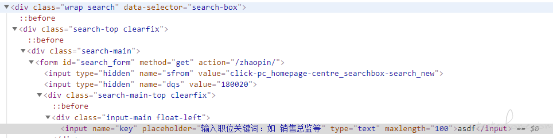
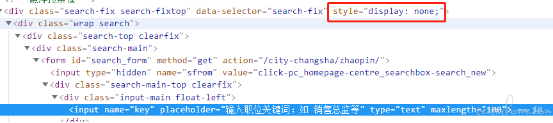
上面分别是两个 input 及其容器元素的结构,可以看到第二个 input 的容器 div 元素多了个 style 属性,data-selector 也不同,那么我们可以再改造一下 xpath
.//div[@data-selector='search-box' and not(contains(@style,'none'))]//input[contains(@placeholder,'输入职位关键词')]
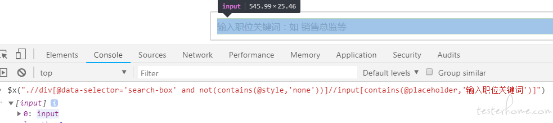
这样 ,我们就定位到了搜索输入框元素 ,这里的 xpath 定位我们使用到了 contains 函数、@ 属性定位、索引定位、and 与操作 、not 函数
接下来再看看下搜索栏下面的行业分类索引链接

假如我们希望能够通过分页文本内容【IT·互联网】来定位到这个 a 元素
xpath : .//p[@data-selector='subsite-btn']//b[text()='IT·互联网']/..
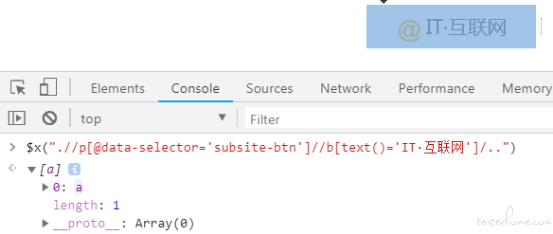
这里,我们使用了【..】来选取父元素,直接使用【..】来定位父元素比较简单,但是不能加任何过滤条件,
如果还想要对父元素或更上层的元素进行过滤选择的话需要用 xpath 轴 ancestor

我们可以看到,xpath 的相对定位是非常灵活并且健壮性较强的一种定位方式,在实际工作中也是使用的非常多的,非常推荐大家使用。
