该文原创为新潮质量保障技术团队中的 “上进的中年软件测试从业者”,用于技术交流分享
拖延症患者还是拖到最后时刻来写这一期的内容。本来这次要写上一篇的续集或者各种架构图的画法(手有余粮,心里不慌),思来想去还是把最容易忘的点写一下,以便加深印象。废话不多述,直接上干货。
开篇
图表的作用非常直接,直观、易读、一目了然。通过图表我能知道最近的版本迭代情况,通过图表我能知道最近的人力分布情况。同时持久化的数据,能让图表讲故事,告诉我们正在发生什么,以及即将会发生什么。
近些年大数据很火,大数据的背后是有数据模型和算法作为支撑,让数据成为反哺业务的价值体现。那对于业务或者决策层来说,他们看到的还是各种会讲故事的图表。
背景
在日常的工作开展中,不管是项目付出、团队贡献、执行质量、绩效考核,最离不开的就是冰冷的数据。所以要想做到一定程度的公正、公平和公开,需要一定的规范来约束工作行为,做到工作留痕。很多小伙伴工作中不善于总结、归档资料,要写年终总结或者述职报告的时候发现没什么可写的,而有另外一小部分小伙伴却恰恰相反,能够让自己的报告充实且丰富。
在移动互联网行业,不同职级的所承载的能力和期望值是不一样的。
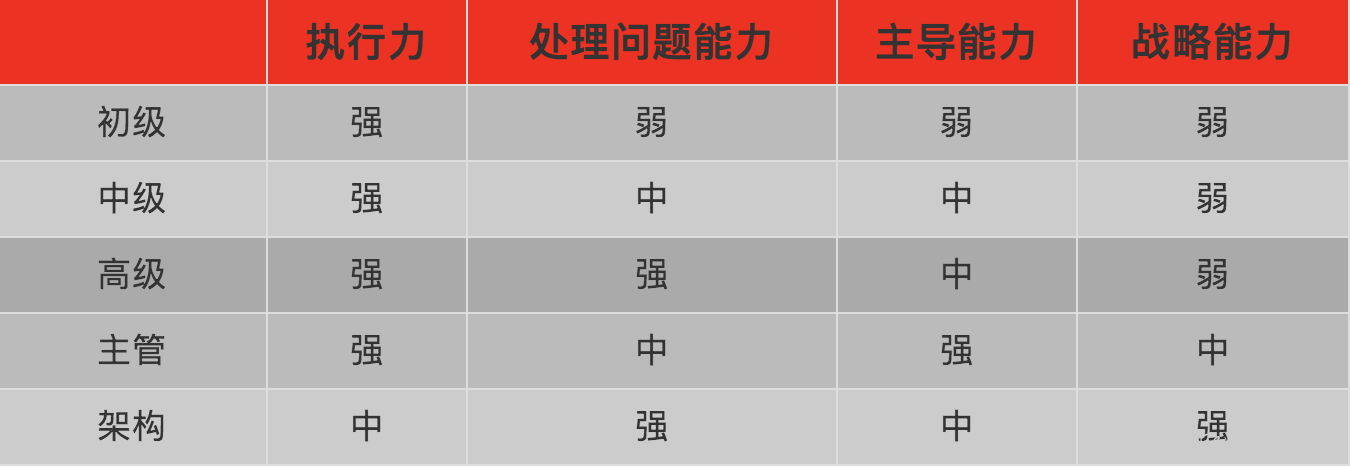
以上是我对各职级所应该具备能力的一个笼统的归纳。结合自身数据和行业标准,或许这些能够告诉我们接下来应该怎么做。
调研
之前有介绍过测试平台的报表系统测试平台之报表系统,里面有介绍为什么选择 pyechart 作为技术选型来实现报表。除了开源和较多的社区外,跨语言也是它的一大特色,所以很可能用 flask_admin+pyechart 实现过程遇到的问题,会在 stack Overflow 上面看到 js+echart 的解决方案。
实现过程
我们这次要介绍的是数据堆叠和多标签翻页功能。
数据堆叠
顾名思义就是要有一个数据累加的效果,以便能够通过一张图就能看到过程数据和汇总数据。
那么首先我们就要获取过程数据,熟悉我们测试平台的小伙伴都知道我们用的是 MongoDB 作为主要的数据库存储,MongoEngine 作为数据的持久化中间件。
聚合工具
熟悉 MySQL 语句的小伙伴知道根据条件汇总数据我们可以采用 group by; 对于 MongoDB 来说,数据聚合函数 aggregate 提供了丰富的数据整合场景:
- 如 MySQL 的字段截取,数据转换。
- 如 MySQL 的返回数据限制 limit。
- 如 MySQL 的 order by 排序功能。

具体请参照:https://docs.mongodb.com/manual/aggregation/
生成 pipeline
有了具体的办法之后,就可以生成 aggregate 需要的 pipeline 来获取自己想要的数据了, 如:
[{'$project': {'updated': {'$substr': ['$updated', 0, 7]}, 'project': 1}}, {'$match': {'updated': {'$gte': '2019-06'}}, {'$group': {'_id': {'project': '$project', 'updated': '$updated'}, 'count': {'$sum': 1}}}, {'$limit': 1000}]
生成聚合数据
IssuesForm.objects(
updated__gte=(datetime.datetime.now() - datetime.timedelta(days=365)).strftime("%Y-%m"),
status=u"关闭").aggregate(*pipeline,
batchSize=1000)
batchSize 的作用
由于数据量比较大,在执行的过程中发现程序执行和 Navicat 客户端执行的效果不一样,程序会有数据少的情况,查了 pipeline、objects 的过滤条件、代码逻辑。最后还是通过 debug 发现每次返回的数据都是 100 条,然后一路追踪源码:queryset->aggregate->pymongo.collection.aggregate 找到了可以修改默认拉取数据的参数 batchSize。
堆叠数据的渲染
echart 图表生成过程就不过赘述了,可以参照之前写的文章学习。这里只讲堆叠过程的实现:
add_yaxis(series_name=series["series_name"], yaxis_data=series["yaxis_data"], color=Faker.rand_color(),
is_selected=is_selected, stack="same stack name“)
Y 轴的数据可以添加很多次,只需要把 stack 命名为相同的名称就可以实现堆叠的效果,如下图:

与此同时,上方月份的标签可以进行选取来生成不同场景的数据,如过去一个月、过去一个季度、过去半年等。
场景升级
多标签翻页
上面我们讲了堆叠数据图表的生成过程。在另外的一个场景中,我们发现当标签过多时,默认情况下标签是无法完全展示并造成图表区域间重叠的情况,如 legend 与 data 区域的重叠、Y 轴与 legend 区域的重叠。
本身就对前端知识匮乏的情况下,尝试通过修改位置属性来调整,发现无法解决。最后还是在第二天的在上重新阅读了官方文档后,找到了解决办法:
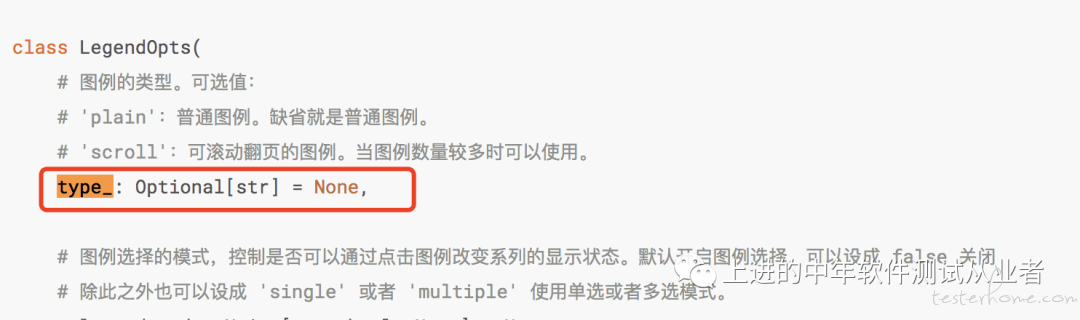
最终的实现效果如下(图例没有什么数据,见谅):
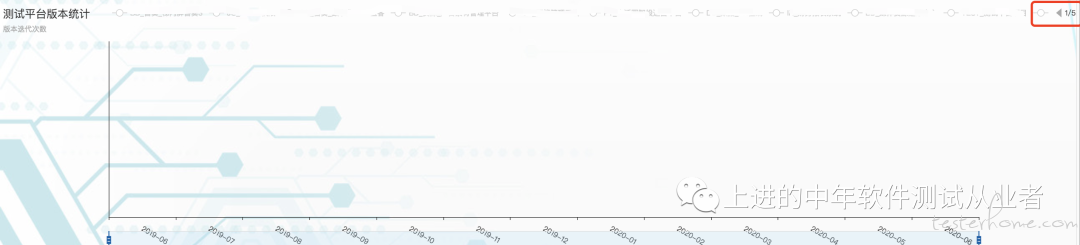
感兴趣的可以参照 pyechart 的官网学习:https://pyecharts.org/#/zh-cn/intro,也欢迎大家交流学习。
结语
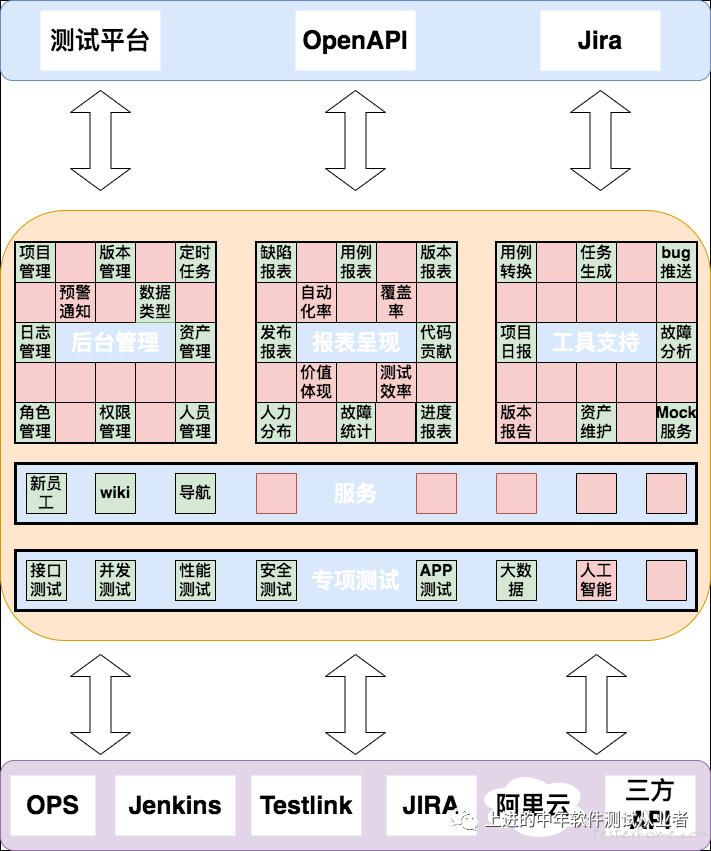
最近在学着画一些架构图,附上测试平台的业务架构图,祝大家周末愉快!