-
一、思考一下,我们运行性能测试的时候,需要哪些数据呢?
-
step1 准备脚本过程数据
- 1.全局数据:exp(一批测试用户、一批测试商品)
- 2.局部数据:
- a) 用于接口动态入参,不用从上下文中获取 (exp:时间戳)
- b) 用于接口动态入参,需要从上下文中获取(exp:用户登录 token 或者 cookie,订单 ID)
- 3.转换数据:exp(将明文密码转换为 md5 加密)
-
setp2 运行脚本过程中数据使用
- 1.同一批数据:每个接口可重复取数
- 2.同一批数据,每个接口取数不重复
- 3.不同批数据:每个接口分别随机取值,不同批数据无关联关系,可随机匹配
- 4.不同批数据:每个接口分别随机取值,不同批数据有对应关联关系
-
step1 准备脚本过程数据
-
二、关于上述场景数据参数化
-
step1 准备脚本过程中参数化处理
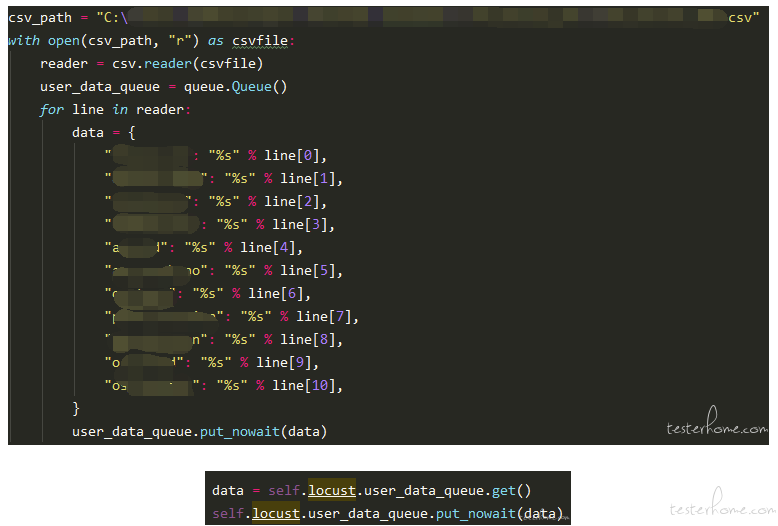
- 1.全局数据:(对比 jmeter 调用 text 或者 csv 的文档方法)
- 可以使用 txt 或者 csv,在通过 pyton 中文件读取函数读取出来,有数据关联的建议每条以 dict of list 形式进行存储
- 使用 python 中 list 类型读取
- 2.局部数据:
- a.上下文无关的动态参数,使用 def 函数返回值进行动态获取
- b.上下文相关的动态参数,使用 taskset 中类属性来进行获取并参数化
- 1.全局数据:(对比 jmeter 调用 text 或者 csv 的文档方法)
-
step1 准备脚本过程中参数化处理
# txt中数据为1,2,3,4,5,6
def get_txt_data():
with open("user.txt", "r") as f:
data = f.read()
return data
# 列表形式数据
s = [1, 2, 3, 4, 5, 6]
s1 = [{"user_name": "张三", "password": 123456},
{"user_name": "李四", "password": 456789},
{"user_name": "王五", "password": 123789}]
# 从上下文中取数据
from locust import Locust, TaskSet, task, between
from time import time
from uuid import uuid1
# 返回当前时间戳
def get_time_stamp():
return str(int(time()))
class MyTaskSet(TaskSet):
# 该函数不是task任务的,可以添加函数来进行获取token,方便任务来调用
def get_login_token(self):
return uuid1()
# 使用类属性来进行参数传递
token = None
# TaskSet相当于下面所有task的大脑
@task(1) # 声明任务
def my_task(self):
print("执行task1" + get_txt_data())
MyTaskSet.token = uuid1()
@task(2)
def my_task_2(self):
print("执行task2" + str(s[0])+str(MyTaskSet.token))
class AppUser(Locust):
weight = 1 # 赋值权重 weight = 10 默认为10
task_set = MyTaskSet
wait_time = between(1, 2)
host = "" # 域名host
-
step2 脚本运行过程中
- 1.同一批数据或者多批数据:
- 不同的 taskset 对应的 user 类中,使用相同的 data 数据
- 不同的 taskset 对应的 user 类中,通过一个或者多个队列进行不重复取值 (如果有关联关系的数据,可以重新一个队列,把对应关系用字典存入到队列)
- 1.同一批数据或者多批数据:
# 两个UserLocust重复调用一个list数据
from locust import HttpLocust, TaskSet, task, Locust, between
import queue
# from multiprocessing import Queue
s=[1,2,3,4,5,6]
class MyTaskSet(TaskSet):
@task()
def task_test1(self):
print(queue_data_test1[0])
class MyTaskSet2(TaskSet):
@task()
def task_test2(self):
print(queue_data_test2[0])
class UserLocust2(Locust):
task_set = MyTaskSet2
wait_time = between(3, 10)
queue_data_test2 =s
class UserLocust(Locust):
task_set = MyTaskSet
wait_time = between(3, 10)
queue_data_test1 = s
# 两个UserLocust调用同一个队列,数据取值不重复;(存在多批次不重复,可定义多个Queue()对象)
from locust import HttpLocust, TaskSet, task, Locust, between
import queue
# from multiprocessing import Queue
def queue_data():
queue_data = queue.Queue() # 默认为先进先出 该队列为task_set共享
# queue.LifoQueue(),后进先出
for i in range(0, 13):
queue_data.put_nowait(i) # put_nowait 不阻塞
return queue_data
class MyTaskSet(TaskSet):
@task()
def task_test1(self):
print(self.locust.queue_data_test1.get())
class MyTaskSet2(TaskSet):
@task()
def task_test2(self):
print(self.locust.queue_data_test2.get())
class UserLocust2(Locust):
weight =1
task_set = MyTaskSet2
wait_time = between(3, 10)
queue_data_test2 = queue_data() # 默认为先进先出 该队列为task_set共享
class UserLocust(Locust):
weight =3
task_set = MyTaskSet
wait_time = between(3, 10)
queue_data_test1 = queue_data()
-
三.总结:
- 上面只是用了样例描述了一下 locust 参数化的过程,基本上是用 python 的方法或者类调用来获取数据和传递参数
- 选择使用 Queue() 对象来实现数据的不重复调用,从其他资料中也可以看到使用 from multiprocessing import Queue 的队列对象来控制多进程安全数据传递
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!