演练目标
- 背景:渲染组切换 redis 集群,统一 redis 版本。目前 redis 版本有 3.0.9,3.2.9,现在统一到 5.0.4
- 目标:演练切换过程和 5.0.4 redis 的可靠性 ### 演练时间 2019-4-9 7:30 - 10:30
演练环境
环境
10.1.**.***(master),10.1.**.***,10.1.**.***
集群架构(内外网相同)
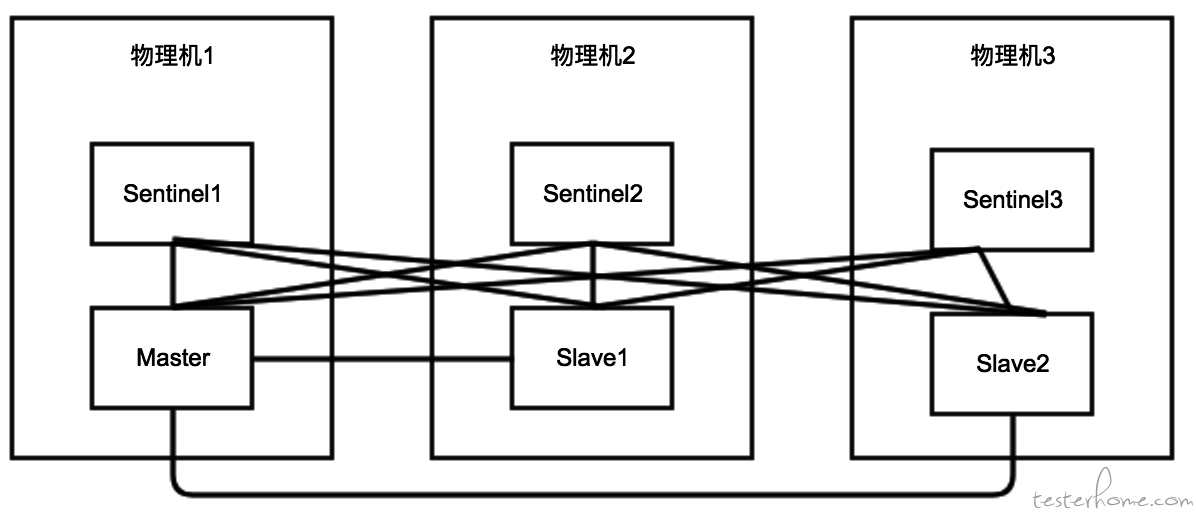
前置准备
- 新 redis 集群搭建
- 老 redis 数据迁移
- 观察 redis 监控项
- 设置告警项
演练步骤
集群验证
- 操作 1:关闭所有 sentinel
- 预期 1:服务表现正常
- 实际 1:服务表现正常
- 操作 2:启动所有 sentinel
- 预期 2:服务表现正常
- 实际 2:服务表现正常
- 操作 3:sentinel1 关闭,服务重启
- 预期 3:服务表现正常
- 实际 3:服务正常重启
- 操作 4:sentinel 全部关闭,服务重启
- 预期 4:服务启动失败
- 实际 4:服务启动失败
主从切换
- 操作 3:关闭 master,查看哨兵监控状态
- 预期 3:服务持续报错 5s
- 备注 3:大约经过 5s 时间,哨兵探测到故障,主从切换成功 1s,查看主从状态,查看持久化状态
- 实际 3:收到告警


- 操作 4:重新启动刚才被关闭的 redis
- 预期 4:服务表现正常,主从状态不变,redis 完成数据同步
- 备注 4:重启操作曾导致主从关系变化沈浪
- 实际 4:服务表现正常,redis 完成数据同步


服务器宕机
- 操作 1:master 物理机宕机
- 预期 1:服务表现正常,主从切换成功前,确认切换成功前业务表现?
- 备注 1:哨兵探测到故障,主从切换成功,查看主从状态,查看持久化状态
- 实际 1:服务表现正常,主从切换成功
- 操作 2:物理机 2 宕机
- 预期 2:服务表现正常,没有影响
- 实际 2:服务表现正常,没有影响
- 操作 3:物理机 2 重启
- 预期 3:服务表现正常,主从关系不变,redis 完成数据同步
- 实际 3:服务表现正常,主从关系不变,redis 完成数据同步
网络异常
- 操作 1:master 拒绝连接
- 预期 1:服务表现正常
- 备注 1:主从切换成功,查看主从状态,查看持久化状态
- 实际 1:主从切换成功
- 操作 2:slave 网络异常丢包,丢包率 70%
- 预期 2:服务有部分请求失败
- 实际 2:服务有部分请求失败,主从切换 (2 台 slave sentinel 才发生,1 台 slave sentinel 不发生切换)
内存异常
- 操作 1:内存设置 max memeroy 为 200M,超过设置的 max memory
- 预期 1:服务表现正常,根据 LRU 算法,删除最近最少使用的健
- 结果 1:redis 满了以后还能写入,最先写入的 test0 已经被删除

- 操作 2:redis 实例的剩余内存小于 max memory
- 预期 2:服务表现正常,根据 LRU 算法,删除最近最少使用的健
- 实际 2: 服务表现正常,实例进程挂了,发生主从切换
磁盘异常
- 操作 1:验证 master 磁盘,默认关闭 aof
- 结果 1:查看 appendonly,关闭 aof
- 操作 2:默认开启 slave aof,模拟磁盘满了
- 预期 2:业务表现正常
- 备注 2:slave aof 文件不再更新,slave 主从同步正常
- 实际 2:slave aof 文件不再更新
- 操作 3:master 磁盘 io 高
- 预期 3:业务表现正常
- 结果 3:业务表现正常
aof 文件操作
- 操作 1:slave 异常关闭
- 预期 1:根据 aof 文件和 rdb 恢复数据,数据没有丢失,会丢失 slave 上最后一秒的数据
cpu 异常
- 操作 1:cpu 满载
- 预期 1:rt 延长、qps 等问题,监控告警
- 实际 1:服务处理能力下降



相关命令
绝大部分场景通过阿里的混沌工具 chaosblade 来完成,即以 ./blade 开头的命令。
- 进程正常关闭
redis-cli -p 6380 -a password shutdown redis-server
redis-cli -p 26380 shutdown redis-sentinel
- 模拟进程异常宕机
ps -ef|grep redis && kill -9 PID
- 模拟网络异常(需优化)
- 模拟丢包
tc qdisc add dev eth0 root netem loss 10%
./blade create network loss --device eth0 --exclude-port 22 --percent 15%
- 延时
tc qdisc change dev eth0 root netem delay 100ms reorder 25% 50%
./blade create network delay --device eth0 --time 3000 --exclude-port 6380 --offset 100
- 磁盘异常
- 磁盘满
./blade create disk fill --size 100000 – 单位MB
dd if=/dev/zero of=/tmp/fiel bs=1 count=0 seek=200G
dd if=/dev/zero of=/tmp/file bs=10G count=10
disk io 高
./blade create disk burn
- CPU -满载
./blade create cpu fullload
应急预案
- 1 主 2 备
Action
- redis 告警时间调整,现在是持续 10min 钟告警
- slave 告警如何设置,告警需要添加 redis 实例的主从 role ,现在主从切换的时候,slave 状态无法监控
- rt 监控进度 木兰
- 主备切换告警未生效(新 Redis 迁移后未迁移告警)
- 内存 rops 和监控指标对不上,需要排查
备注
- slave 机器目前仅做备份使用,读写均从 master
- 服务表现正常,泛指可接受的一部分时间不可访问,大约小于 1 分钟
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。
如果您有兴趣了解我们的职位和团队情况,请参考最新职位招聘,并联系 caibao@qunhemail.com。感谢您的阅读!
「原创声明:保留所有权利,禁止转载」