研发效能 度量平台开发实践
背景
度量的根本目的是为了管理的需要,没有对软件过程的可见度就无法管理,而没有对见到的事物有适当的度量或适当的准则去判断、评估和决策,也无法进行优秀的管理。
而度量,是对软件开发项目、过程及其产品进行数据定义、收集以及分析的持续性定量化过程。而这个过程是多样性的,不同的业务关系的度量指标可能并不相同。这就导致一个/若干个固定的图表无法满足所有人。
在本度量平台开发之前,也已经有了一些度量平台/模块,但几乎都是一张有若干固定逻辑的图表页面,用户只能查看默认的几张图表,无法自由进行度量。因此,急需设计一个具有通用性、方便配置和方便拓展的度量平台来完成度量任务。
也出于这个原因,本文着重介绍的是工具端度量平台如何做到支持用户方便的自定义指标、修改指标计算逻辑上。不具体讨论某类指标该如何定义、计算的相关内容。
数据与图表的关系
既然要开发一个可以有用户自主配置的度量平台,首先就先要弄清楚数据度量的共性。
从 excel 说起
举例来说,如下一个基础数据,图 1:
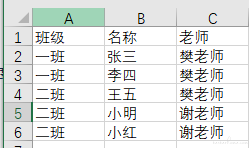
如果需要统计一班和二班的人数,则通过计算可以得到下方图 2,然后基于这个数据可以利用 excel 插入图表的功能得到图 3 或者图 4
图 2:

图 3:
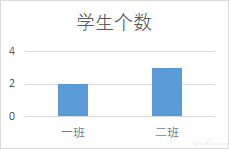
图 4:
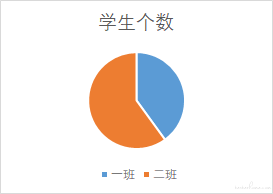
这个一个最简单的统计。如果映射到数据库中,原数据在表 table_student 中,需要获取到图 2 的数据,只需要执行 SELECT 班级,COUNT(*) AS 学生个数 FROM table_student GROUP BY 班级 即可得到数据。
而如果现在需要统计每个老师在每个班级中带的学生个数,则可以通过 SELECT 班级,老师,COUNT(*) AS 学生个数 FROM table_student GROUP BY 班级,老师 得到图 5 的数据。
然后我们可以重新排版一下这份数据,得到图 6 的样子(数据本质没有变化)。然后即可用 excel 插入图表的功能得到图 7。
图 5:
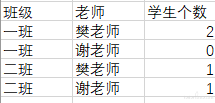
图 6:

图 7:
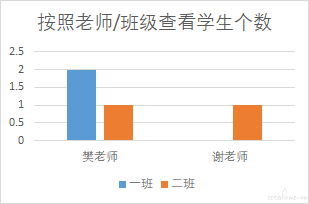
以上就是最核心的基础数据=>图形的变化过程了。一般的二维柱状图/折线图支持 2 个维度例如班级和老师(三维的柱状图可以支持到 3 个维度,方法同理,但这里不展开了。一般二维图就够用了)
抽象成数据规范
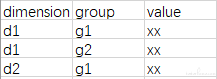
通过上方的例子可以看出来,只要有一份数据是图 8 这样的格式,就一定可以转换成一份二维表格或者一张柱状图/折线图,而其中缺少 dimension 或者 group 时,其实就是一份一维表格,可以转换成柱状图/折线图/饼图
图 8:
因此可以规范所有准备出图的数据格式如下。只要后端能得到这样的数据,那么前端就一定可以将其展现成一张图表
[
{
dimension : xx,
group : xx,
value : xx
}
...
]
后端数据查询器
接着上文的思想,后端的主要目标就是生成出图的数据,那么数据源头在哪里?该如何从全量数据中查询出本次统计需要的数据?
数据同步与多数据源
度量平台在一个地方,但是数据可能散落在各个系统中,这该如何统一?度量平台针对数据类型的不同,使用了不同的策略。
| 方案 | 优点 | 缺点 |
|---|---|---|
| 通过数据同步将其他平台的数据持久化到本地 | 同步的过程可以同时进行数据清洗,只留下最关键的数据内容,使用专为统计而设计的数据结构。对于数据量极大的系统、例如代码扫描系统,每天的数据可以有几千条,而通过数据清洗和重构数据结构后,每天只需要存 300 多条数据,这样可以极大的提升统计效率。 | 开发,维护成本高。而且同步不能做到实时同步的话还会有数据延迟。 |
| 通过多数据源直连其他平台数据库 | 成本低,不需要设计数据结果以及开发同步代码。完成好多数据源框架后,只需要配置数据库连接信息即可。数据实时性好。 | 由于表设计是由数据提供方决定的,可能会出现不适合统计的表设计,与统计无关的数据多,查询起来反应慢。也在一定程度上限制了能够统计的指标逻辑。 |
数据查询核心
有了数据源,接下来便是按照用户的需求,通过简单的配置来查询数据库中的各类数据,有点类似 Navicat 的筛选功能。
在开头其实已经有点到一下,从全部数据中查询出特定统计的数据,可以使用如此的 SQL 模板:SELECT d1 AS dimension,g1 AS group,v1 AS value FROM some-table WHERE some-condition GROUP BY d1,g1。
在这个 SQL 中,整个用户自定义的核心就收敛到了 d1/g1/v1/some-condition/some-table 的取值了。他们分别对应着需要根据什么维度,什么分组,什么指标,什么过滤条件,数量来源什么表。
举个栗子:已知线上故障数存在 bug_online 这种表中,拥有字段 issue_key、project(敏捷组)、business(业务线)、status(当前状态)、create_time(创建时间)。
现在我们需要一个图表来展现全屋定制业务线下各个敏捷组在2020年4月1号到2020年4月7号中新增的各个故障当前的状态分布情况(各有多少个)
因为数据存在 bug_online 中,所以 some-table 为 bug_online
因为查询的是线上故障的个数,所以 v1 对应的是故障的个数,可以使用 COUNT(*)。
因为需要为各敏捷组进行统计,并且要看状态分布情况。所以 d1=project ,g1=status(这里两者也可以反过来 d1=status,g1=project)
而数据过滤条件中,一个是在2020年4月1号到2020年4月7号创建的需求,一个是统计全屋定制业务组下的,所以 some-condition= business='全屋定制' AND create_time >= '2020-04-01' AND create_time <= '2020-04-07'
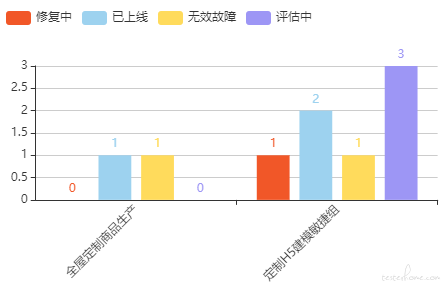
综上所述,得到 SQL 的结果:SELECT project AS dimension,status AS group,COUNT(*) AS value FROM bug_online WHERE business='全屋定制' AND create_time >= '2020-04-01' AND create_time <= '2020-04-07' GROUP BY project, status
执行 SQL 得到数据:
图 9:

图形化后->
前端图形渲染器
既然后端已经连接到了数据源,又支持了可拓展的数据查询。剩下的就是前端的交互和出图了
插件选择
使用的是 echart 来画各种图形,好处在于 echart 的配置参数都在 option 中,使用起来比较方便,只需要更改 option 的值即可更改图形,与 react 的数据=>页面的思想很类型。并且也因此可以很方便的拓展图形配置更改(例如开发者模式)
图表渲染基本流程
前端每个图表的基础渲染方法核心如下,首先需要调用后端数据查询器获取相应的数据,由于数据库中存的绝大多数都是 id,int 这类的数据,所以针对得到的数据还需要进行重命名操作,使得数据变成可读中文。接下来便是构造 echart 的 option
可预览的实时调试
图表的新增/编辑页是最关键的一个页面,也是整个度量平台的精华所在。它将度量平台和普通的数据大盘中区分了出来。
在这个页面可以通过动态的更改各类条件(d1/g1/v1/some-condition)实时查看图表的变化。这样就能够允许用户从大到小,逐步定位问题。
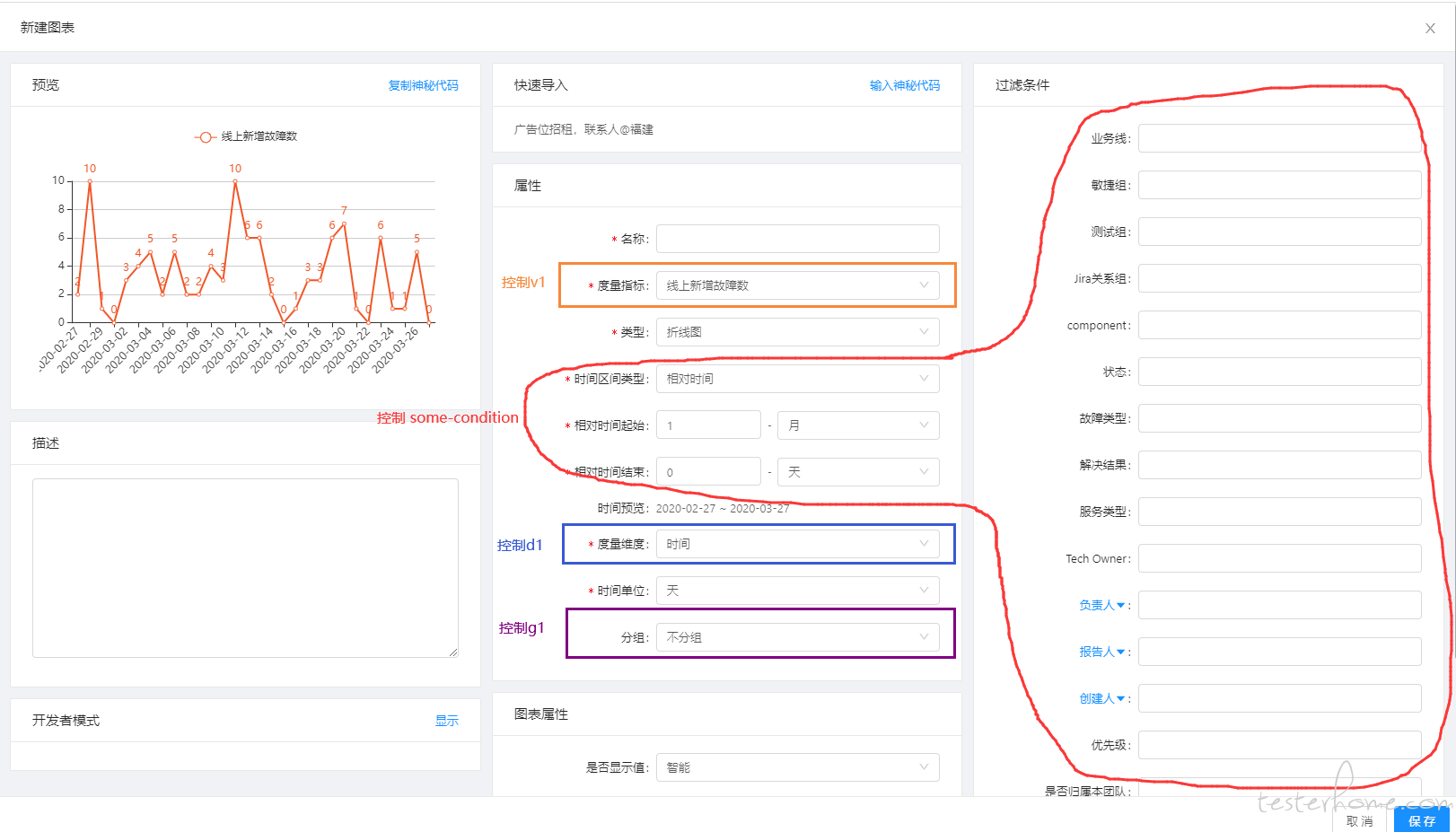
可自定义的排版
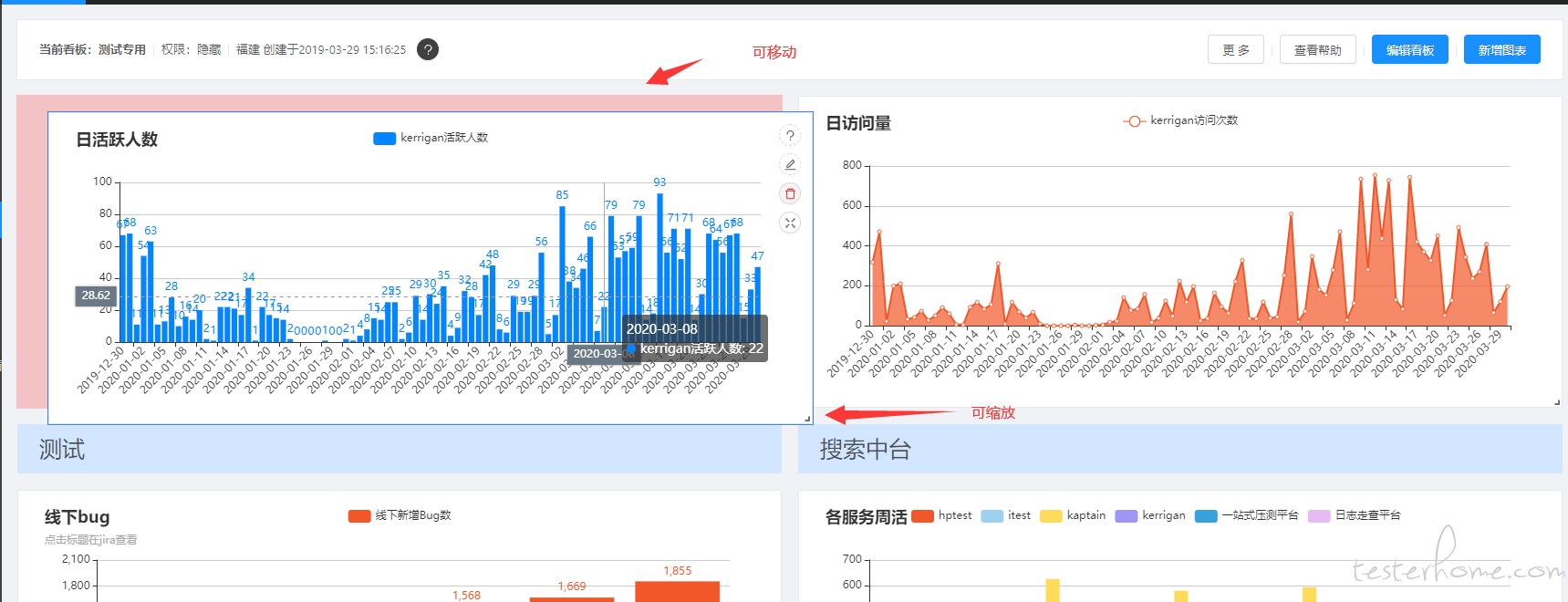
图表既然是用户自己定义出来的,看板又是由多个图表组成的。排版功能自然不可少,为了方便用户,每个图表都可以在看板中拖拽和缩放,以便满足用户自身习惯。这里用的是 react-grid-layout 插件
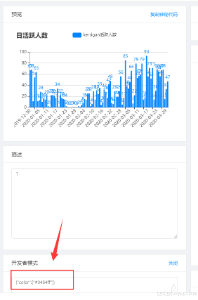
开发者模式
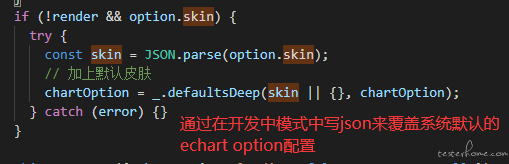
由于前端图形化插件使用的是 echart,并且 echart 的配置参数都在 option 中,因此借助 echart 强大的可配置项和功能,可以通过在线修改 option(json 格式字符串)来覆盖默认图形配置,从而达到个性化图表的功能。
并且允许在其中添加度量平台特质的一些功能配置,来实现一些不太通用的特殊需求,这样可以避免占用页面重要的公共资源,以及让其他不需要定制的用户看到而不知所以然。使用开发者模式设置图表的颜色:
通用与定制
使用通用规范降低指标的开发成本
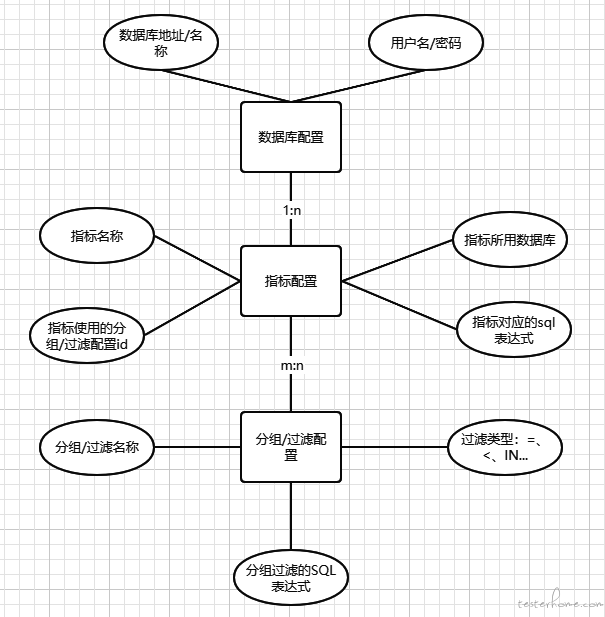
上文中的后端数据查询器和前端图形渲染器规范了绝大部分度量的规范,可以满足 80% 的度量需求。中间将各类变量抽取出来放在数据库进行配置,针对新指标,只需要在数据库中新增几条记录即可。
数据库设计基础 ER 图如下(只展示了一些重要属性)。同样前端也以此有一套默认的渲染方法,如此一来,新指标的接入成本就下降到了分钟级。
还是以线上故障数指标为例
- 数据库配置表新建一条记录,录入地址、名称、用户名和密码——假设本条 id=1
- 指标配置表新建一条记录,录入指标名称=线上故障数、使用数据库 id=1,指标表达式=COUNT(*),使用过滤配置 id=1
- 新建若干条过滤配置:business/project/status。。。等
保留定制特殊要求的拓展接口
虽然 80% 的指标已经可以满足了。但剩下的 20% 也通用重要。一些特殊的图表,或者逻辑是上述逻辑无法满足的。
例如有些指标可能需要添加权限控制,并且涉密指标的鉴权方式可能不尽相同。
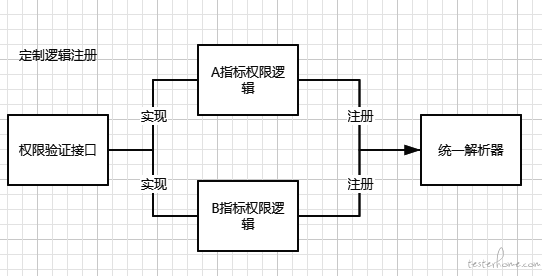
这里使用到了类似策略模式 + 观察者模式两者设计模式的结合,下面以定制权限为例。
根据需要定义权限校验策略接口,然后为每个需要定制的指标实现相关策略接口,并且在 bean 初始化时注册到统一的数据查询器中(这里和观察者模式中的注册观察者类似)。
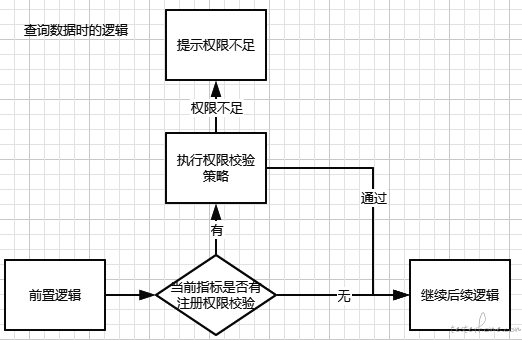
然后在数据查询器的逻辑中插入 if-else 来判断是否需要权限校验,如果需要就进入改指标定制的权限校验策略。
注册逻辑:
执行逻辑:
大致代码
@Service
public class ChartService {
/**
* 用来保存指标定制的权限处理器
*/
private final ConcurrentHashMap<String, CustomAdmin> customAdmins = new ConcurrentHashMap<>();
/**
* 定制的权限处理器使用该方法完成注册
*
* @param key
* @param o
*/
public synchronized void addCustomAdmin(final String key, final CustomAdmin o) {
if (o == null)
throw new NullPointerException();
customAdmins.put(key, o);
}
/**
* 检查权限
*
* @param chart
*/
public void checkChartAuth(final Chart chart) {
final CustomAdmin customAdmin = customAdmins.get(chart.getTarget());
List<String> admin;
// 如果有定制化权限处理器就使用定制化的,否则用默认的权限处理
if (customAdmin == null) {
final AdminConfig adminConfig = adminConfigMapper.findByTarget(chart.getTarget());
// 如果不是加密指标直接返回
if (adminConfig == null) {
return;
}
adminConfig.transformVO();
admin = adminConfig.getNameList();
} else {
admin = customAdmin.listAdmin(chart);
}
final String currentUser = Utils.currentUserName();
if (admin == null) {
throw new PassException("对不起,您没有权限调试该指标!");
}
if (admin.contains(currentUser)) {
return;
}
throw new PassException("对不起,您没有权限查看该数据!");
}
...
}
@Service
public class ContractAuth implements CustomAdmin {
@Autowired
private ChartService chartService;
@Autowired
private AdminConfigMapper adminConfigMapper;
/**
* 向图表解析器注册,标明续约报表xxx指标的鉴权方式需要用这里定制的方法
*/
@PostConstruct
private void init() {
chartService.addCustomAdmin("续约报表xxx指标", this);
}
@Override
public List<String> listAdmin(final Chart chart) {
// TODO 自己定制的admin获取逻辑
return admin;
}
}
通过这类的逻辑,可以在整个数据查询器中穿插很多可定制的策略。除了为每个策略写一个接口,其实也可以直接写一个全的接口,然后通过 default 方法定义默认的接口实现。这样可以减少注册的开销。
前端的方式也比较类似,可以为每个指标定制图表渲染器。通过自定义图表渲染器甚至可以摆脱后端的数据查询器,改为特制的数据来源(比如敏捷组迭代甘特图)。
整体流程示意图
说完了前端和后端,结合起来回顾一下度量平台的整体流程
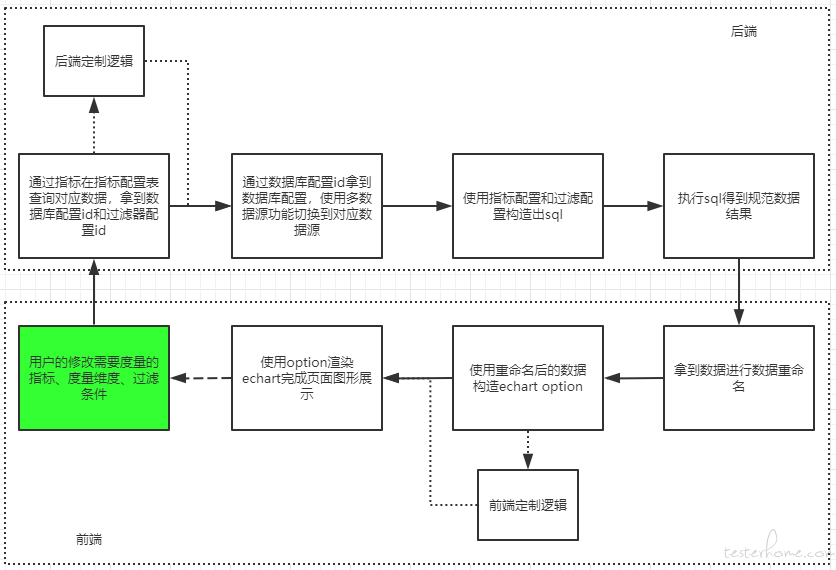
实现和推广中遇到的问题
如何防止 SQL 注入
从上述思想中也不难看出构造 sql 是在所难免的,那么随之而来的一个问题就是如何才能避免 sql 的注入?
虽然作为一个面向内部用户的内网系统,SQL 注入的风险是比较小的,但是出于对技术的负责,我们还是需要尽可能的避免 SQL 的风险
为此,度量平台通过了以下三个方式来限制了 SQL 注入的风险
- 数据库权限限制,针对数据源来自多数据源的相关指标,可以通过配置这些度量专用账号的数据库权限来限制 sql 注入风险。例如只有数据库中某些表读的权限
- 通过人为预制的方式来避免了 sql 注入。所谓预制,指的就是上文 SQL 中的 d1/g1/v1/some-condition 这些变量。是只能在某些特定的值中选取的。例如配置了学生表中只能根据班级和老师进行分组/过滤,那么即便通过 api 直接传入了按照姓名分组/过滤,也会抛出异常或者直接忽略。
- 某些完全不受控的地方,例如 some-condition 中允许过滤项的具体过滤值,这类通过最简单的关键字正则匹配的方式来避免 SQL 注入
指标计算逻辑定义
虽然本文一开头提了不讨论指标的详细逻辑,但是在数据度量中指标计算逻辑是非常非常重要的,因此这里专门讲一下。
虽然度量平台也有一定收集数据、清洗数据的能力。但其最主要功能是方便数据可视化的工具。它只是如何构建指标体系的呈现载体,指标体系的确立实际上是使用度量平台的用户决定的。
爱因斯坦说过,度量平台科学是一种强有力的工具,怎样用它,究竟是给人带来幸福还是带来灾难,全取决于人自己,而不取决于工具。
度量平台允许用户快速的接入指标,但指标本身是否合理,是否有价值还是需要人来判断,这不是一个度量平台开发者就能决定的。度量体系的建立是需要整个体系中的每一个人都参与进来,思考分析指标的业务价值、在实践中确定指标可反馈执行,最终大家都认同的一个过程。
所以在一开始推动度量平台的过程中,指标是怎么计算出来的,是否合理成了被反馈的最多的问题。收集每一个人的反馈,聆听每个组的需求,推动用户参与到度量体系的建设中来,思考指标逻辑,统一各组规范,最终达成内部统一也成了平台开发外的一项重要工作。
平台推广收益
由于度量平台的可配置性,各个组不再限制与所有人都看同一个页面同一张图。每个组都可以根据各自自身的特点和关注点来配置自己的看板。甚至每一个用户都可以配置一张专属于自己的看板。
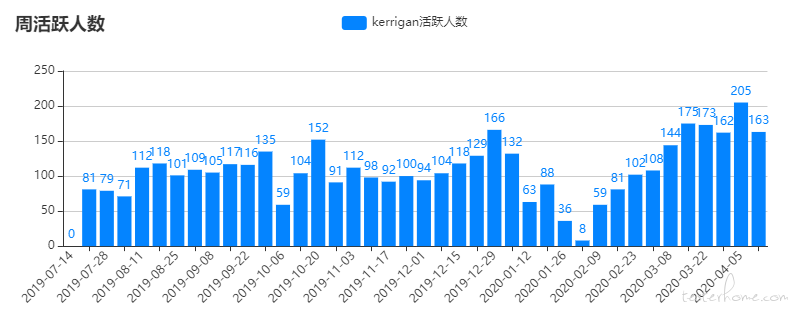
截止到 2020/04/13,度量平台已经创建了 471 个看板,6413 张图表。而接入的各种指标数也已经达到了一百多个。若没有可配置易拓展的度量平台,开发这么多看板和指标将会是巨大的工作量。
下方截图是用度量平台统计的度量平台的周活人数,可以看出周活人数已经稳定到了 100 以上,而疫情后随着复工率稳步提升,最高已经突破了 200。很多组也都养成了数据驱动的管理习惯。
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。
如果您有兴趣了解我们的职位和团队情况,请参考最新职位招聘,并联系 caibao@qunhemail.com。感谢您的阅读!
