接口测试 python+requests 实现接口自动化 [更新 提交源码至 GitHub]
python+requests 实现接口自动化
1. 前言
今年 2 月调去支持项目接口测试,测试过程中使用过 postman、jmeter 工具,基本能满足使用,但是部分情况下使用较为麻烦。
比如:部分字段存在唯一性校验或字段间有业务性校验,每次请求均需手工修改部分报文内容,使用工具难以满足实际使用。
因此,萌生了使用 python 去实现接口自动化的想法。之前未接触过接口测试,但有一点编程基础,经过 2 个多月的磕磕碰碰,不断完善,经历 2 次重构之后,最后基本达成了目标。
2020年12月16日更新说明:
抽空梳理了一下程序,将业务相关部分删除,留下较通用部分,已上传至 GitHub,有兴趣的朋友可以到 GitHub 上查看。
GitHub 地址:https://github.com/wangyunsz/APIS_AutoTest
2. 技术栈
- python 语言
- requests 库
- unittest 单元测试框架
- HTMLTestReportCN、BeautifulReport 测试报告
3. 实现的功能概述
- 支持 post、get 等请求类型,xml、json 格式的报文
- 支持使用 excel 编写测试用例,测试用例支持涉及多接口的场景用例;支持按脚本的形式编写测试用例
- 支持测试结果保存至数据库,支持生成 html 报告,支持将生成的测试结果导出到 excel 文件
- 支持邮件发送测试结果
- 支持多线程并发执行测试用例
4. 框架及项目结构
APIS_AutoTest
api: 主程序目录
comm:公共函数,包括:接口请求基类、请求及相应数据操作基类等
intf_handle:接口操作层,包含:接口初始化、断言等
business:业务实现部分
utils:工具类,包括:读取文件、发送邮件、excel 操作、数据库操作、日期时间格式化等
config:配置文件目录,包含 yaml 配置文件、以及路径配置
data:测试数据目录,用于存放测试数据
temp:临时文件目录,用于存放临时文件
result:结果目录
report:测试报告目录,用于存放生成的 html 报告
details:测试结果详情目录,用于存放生成的测试用例执行结果 excel 文件
log:日志文件目录
test:测试用例、测试集相关目录,启动 test_suite 执行用例文件存放在此
test_case:测试用例存放路径
test_suite:测试模块集,按模块组装用例
5. 测试用例执行流程
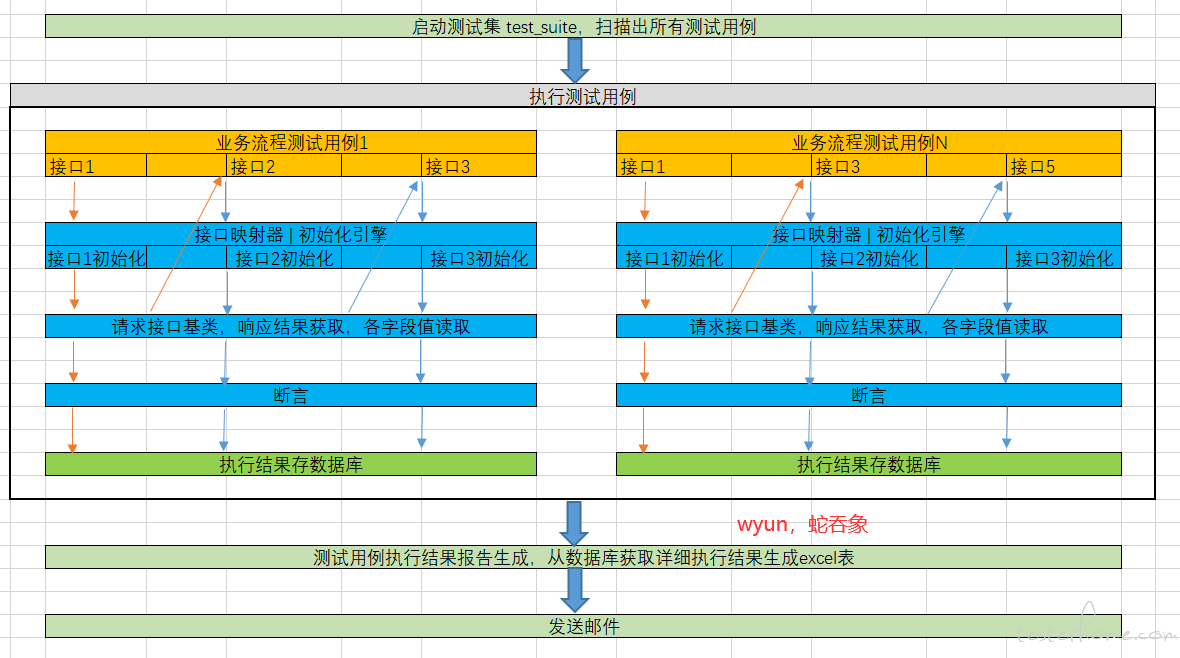
以脚本形式编写的测试用例执行流程图:
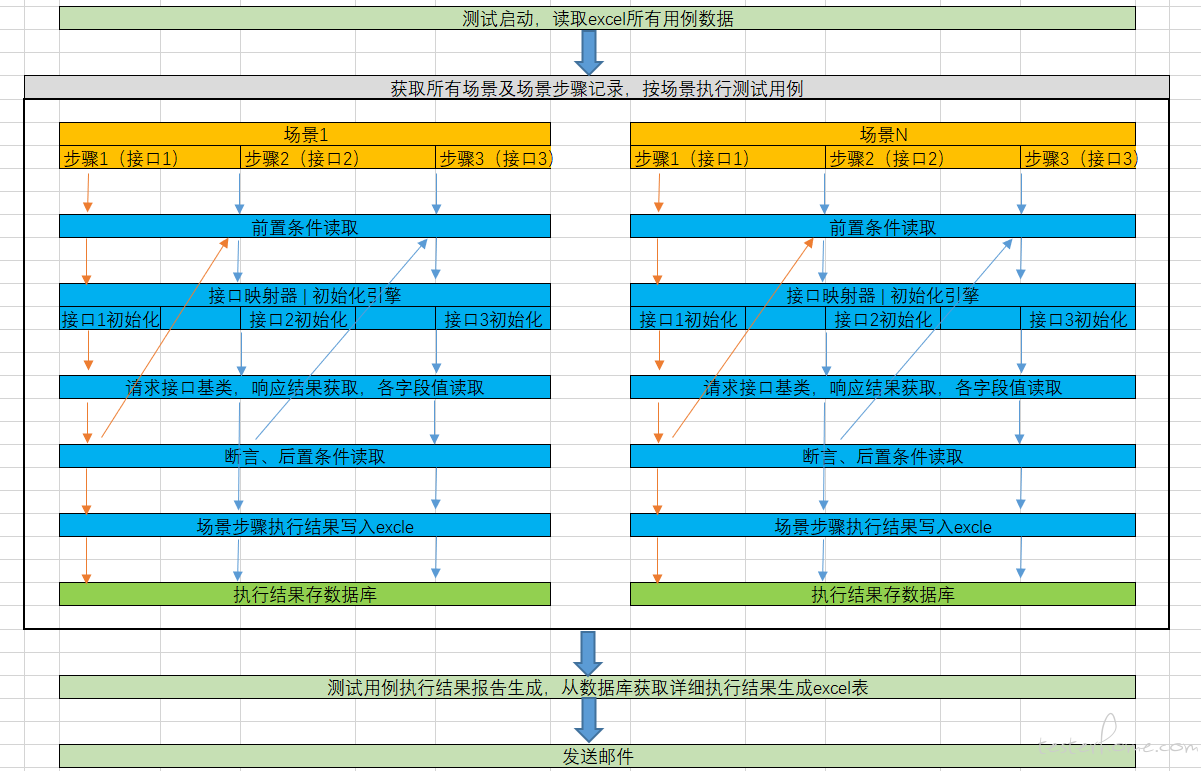
以 excel 形式编写的测试用例执行流程图:
6. 核心方法设计
-
接口请求基类
RequestBase(request_type, url, header, body, data_type=None)
功能描述:
根据传入的请求类型,请求地址,请求头,请求体,发送接口请求,获得响应头,响应体
- request_type: 请求类型,只能是'GET', 'POST', 'HEAD', 'OPTIONS', 'PUT', 'DELETE', 'TRACE', 'CONNECT'中的一个,无大小写要求
- url: 请求地址,完整的接口地址
- head: 请求头
- body:请求体,xml 格式请求体为字符串;json 格式请求体需传入 json 格式
- data_type: 数据类型,未使用字段,备用。可为:xml、json
支持方法
__send_request()
发送请求,类私有方法,初始化时调用,调用方法返回:响应对象
get_respond()
获取响应对象,调用方法返回:响应对象
get_respond_head()
获取响应头,调用方法返回:响应头
get_respond_body()
获取响应体,调用方法返回:响应体
-
请求或响应数据操作基类【该方法已重构,详见最后章节】
RequestRespondHandle(data_type, body, fields, value_dict=None)
功能描述:
根据传入的 xml、json 格式请求体或响应体,读取字段的值或更新字段的值
参数描述:
- data_type: 数据类型,当前仅支持 xml、json,不区分大小写
- body: 请求体或响应体,json 格式请求体支持传入字典、json 格式数据(自动转换为字典)
- fields: 字段名称,支持多字段传入,支持数据类型:字符串、元组、列表。多字段传入形式,字符串:多个字段名称之间逗号隔开,如:'a1,b2';元组、列表正常传入即可。json 格式:需写入完整节点路径,如:body.base.name,对应 list 类型的需传入索引位置,如:body.baselist[0].name
- value_dict: 字段值字典,以字段名称及字段值键值对的方式存储数据,读取字段值时,一般不需传入,也支持传入(用于读取 excel 形式流程前后传值);更新字段值时,需传入,且字典中的 key 值需要与 fields 中的字段名对应。
支持方法:
get_fields_value()
获取字段值,调用方法即可获取到 xml 或 json 格式的请求体或响应体对应的字段值,并返回:字段值字典
update_fields_value()
更新字段值,调用方法即可更新请求体中对应的字段值,返回更新后的请求体。
Json 格式请求体返回格式为字典。
不足与改进【已重构,不足之处已完善】:
xml 格式,读取或更新字段时,若存在多个相同名称字段,默认只选第一个;
json 格式,读取嵌套列表的时候,未支持按列表读取,当前需精确位置单个读取或更新;
-
请求体初始化 - 接口映射类
RequestMsgInitMapper(data_type, intf_code, request_body, **kwargs)
功能描述:
根据传入的接口编号,映射到对应的接口请求报文的初始化方法,进行接口初始化
参数描述:
- data_type: 数据类型,执行 xml、json,不区分大小写
- intf_code: 接口编号,每个接口都要一个接口编号,根据接口编号可以唯一确定一个接口
- request_body: 请求体,json 格式请求体支持传入字典、json 格式数据
- **kwargs: 可变关键字参数,每个接口初始化时,参数数量均不一致,所有需要使用可变参数,需要以 a=value 这种方式传入。部分字段(如 id)可在方法内设置生成方法,一般可变参数设置都是用于前后接口字段传值。
支持方法:
start_Intf_init_mapper()
启动 接口初始化映射,该方法通过判断传入数据类型、接口编号,执行对应的接口初始化方法。
调用方法后,进行对应接口的初始化,并返回初始化后的请求体。
Json 格式的数据,返回 json 格式的请求体(不管传入的是字典格式、还是 json 格式)。
适用场景说明:
接口映射类主要是针对不同接口初始化字段涉及复杂业务判断,需按接口单独编写的场景。
如果一个接口初始化涉及的字段均不涉及业务相关的复杂判断处理,可以直接统一使用通用接口初始化方法进行初始化。
通用接口初始化方法
intf_base_init(data_type, request_body, **kwargs)
功能描述:
根据可变关键字参数传入的键值对,进行接口报文初始化,返回初始化后的请求体
参数描述:
- data_type: 数据类型,执行 xml、json,不区分大小写
- request_body: 请求体,json 格式请求体支持传入字典、json 格式数据
- **kwargs:可变关键字参数,每个接口初始化时,参数数量均不一致,所有需要进行初始化的字段,均需以键值对的方式传入。
适用场景说明:
接口初始化字段不涉及复杂逻辑判断,直接传值后更新即可;该方式也适用于接口请求头的初始化。
7. 数据操作类
数据操作主要是数据读取、写入,主要分为如下几类:
- 读取 txt、json 等文件内容(整个读取)、写入内容到文件
- 读取 yaml 文件内容
- 读取 excel 表格内容、导出 excel 表格、读取 excel 并作为模板
- 操作数据库表中的数据(增删改查)
读取 txt/json 文件内容,写入内容到文件
FileHandle(file_name, file_path)
功能描述:
读取文件所有内容
参数描述:
- file_name:读取/写入文件名称,包含后缀,支持 txt,json 等
- file_path:读取/写入文件所在的目录
支持方法:
read_file_content()
读取文件内容,并以字符串返回
write_to_file(content)
将内容写入文件
读取 yaml 文件内容
ReadYaml(file_path)
功能描述:
读取 yaml 文件内,支持按名称读取
参数描述:
- file_path:读取文件的完整路径
支持方法:
get_yaml()
读取 yaml 文件所有内容,并以字典格式返回
get_value(level_name)
读取 yaml 文件字段的值,并返回
level_name: 节点字段名称,如涉及多节点需传入对应路径,如:db.host
读取 excel 表格内容、导出 excel 表格、读取 excel 并作为模板
ExcelHandle()
功能描述:
读取 excel 表格内容、将数据导出到 excle 表格中
支持方法:
read_excel_data(excel_path, sheet_name=None)
读取 excel 表格内容,并以列表嵌套列表的方式返回
excel_path: 读取 excel 文件的完整路径
sheet_name: 读取 excel 的页签名称,默认读取第一个页签
export_to_excel(data, head, file_name, time_flag=None)
将数据导出到 excle 表格中
data: 需要导出到 excel 的内容,元组嵌套元组(对应数据库中查询返回的结果)
head: excel 表头,列表、元组嵌套元组(数据库中查询表头、描述,支持多表头)
file_name: excel 文件名称,包含后缀.xlsx,excel 导出路径系统默认
time_flag: 时间戳标记,可传入用例执行的报告号,使其对应
copy_excel_template(template_path, sheet_name=None)
复制 excel 表格模板,返回 workbook, workssheet
template_path: 模板文件完整路径
sheet_name: 模板文件页签名称,默认第一个页签
操作数据库数据
功能描述:
- 表数据读取:根据情况读取所需数据,返回数据格式元组嵌套元组。
- 插入/更新表数据:根据实际内容,写入数据到对应的表中
备注:
数据库部分封装为数据库操作类
8. 部分关键代码
接口请求基类
# create by: wyun
# create at: 2020/4/19 9:30
import json
import requests
class RequestBase:
def __init__(self, request_type, request_url, request_body, request_headers, intf_type=None):
"""
请求接口公共类
:param request_type: 请求类型:post, get
:param request_url: 请求url地址
:param request_headers: 请求头
:param request_body: 请求体(xml类型传入字符串格式,json类型数据必须传入json格式,不能传入字典)
:param intf_type: 接口类型:webservice, api,分别对应接口数据格式:xml, json
"""
self.request_type = request_type
self.request_url = request_url
self.request_body = request_body
self.request_headers = request_headers
self.intf_type = intf_type
self.res = self.__send_request()
# 发送请求
def __send_request(self):
if not isinstance(self.request_type, str):
print('请求类型格式错误。')
return None
if self.request_type.upper() not in ['GET', 'POST', 'HEAD', 'OPTIONS', 'PUT', 'DELETE', 'TRACE', 'CONNECT']:
print('请求类型不存在。')
return None
return requests.request(method=self.request_type, url=self.request_url, data=self.request_body.encode('utf-8'),
headers=self.request_headers)
# 获取响应
def get_respond(self):
return self.res
# 获取响应头
def get_respond_head(self):
return self.res.headers
# 获取响应体
def get_respond_body(self):
if self.res.content:
return self.res.text
请求或响应数据操作基类
# create by: wyun
# create at: 2020/4/19 12:58
import json
import re
"""
对请求体或响应体进行处理:
1. 支持读取请求体或响应体中字段的值
2. 支持更新请求体中字段的值
"""
# 递归调用,更新json中的字段值
def update_json_step(node, json_str, value, i=0):
# 当前节点索引(负向)
node_index = -len(node) + i
# 如果包含[n]形式,说明节点为列表,需处理
if '[' in node[node_index] and ']' in node[node_index]:
list_node, list_index = node[node_index].split('[')
index = list_index.split(']')[0]
if index is None or index == '':
print('参数传入错误,请指定列表[%s]索引' % list_node)
else:
index = int(index)
return update_json_step(node, json_str[list_node][index], value, i + 1)
# 判断如果当前节点为最后一个节点,则更新value值
if node_index == -1:
json_str[node[-1]] = value
return json_str
return update_json_step(node, json_str[node[node_index]], value, i + 1)
class DataHandle:
def __init__(self, data_type, data_msg, fields, value_dict=None):
"""
处理请求体或响应体数据,读取或更新字段值
:param data_type: 数据类型:xml,json
:param data_msg: 请求体或响应体
:param fields: 字段值,支持多字读方式,字段间逗号隔开;或传入列表、元组
json格式:需写入完整节点路径,如:body.base.name,对应list类型的需传入索引位置,如:body.baselist[0].name
:param value_dict: 以字典键值对保存字段值
"""
self.data_type = data_type
self.data = data_msg
# fields支持str,list方式,str自动转换为list
if isinstance(fields, str):
self.fields = fields
self.fields_list = []
if ',' in fields:
self.fields_list = fields.strip().split(',')
else:
self.fields_list.append(fields.strip())
elif isinstance(fields, list):
self.fields_list = fields
else:
self.fields_list = list(fields)
# 初始化字典值
if value_dict is None:
self.value_dict = dict()
else:
self.value_dict = value_dict
def get_fields_value(self):
"""
获取字段值
1. 支持获取多个字段值,输入字符串或列表, 元组
"""
step_dict = self.value_dict
# 字段列表循环获取
for p in self.fields_list:
if p == '':
continue
# 处理xml格式报文
if self.data_type.upper() == 'XML':
pattern = '<' + p + '>.*</' + p + '>'
search_result = re.search(pattern, self.data)
if search_result is not None:
# 包括标签和值都匹配上
field_and_value = search_result.group()
# 去除标签获取字段值,并存入字典
step_dict[p] = (field_and_value.split('</')[0]).split('>')[-1]
else:
# print('参数[%s]提取失败,无匹配值。' % p)
pass
# 处理json格式报文
elif self.data_type.upper() == 'JSON':
# 获取层级(使用.隔开)
node = p.split('.')
# json转换字典
if isinstance(self.data, dict):
temp = self.data
else:
temp = json.loads(self.data)
# 逐层读取数据
for per_node in node:
if '[' in per_node and ']' in per_node:
per_node, index_str = per_node.split('[')
index = int(index_str.split(']')[0])
temp = temp.get(per_node)[index]
if temp is None:
break
else:
temp = temp.get(per_node)
if temp is None:
break
# 讲读取的结果写入字典
step_dict[p] = temp
# 非 xml,json的数据格式,报错退出
else:
print('ERROR: 不支持此数据类型[%s]' % self.data_type)
break
return step_dict
def update_fields_value(self):
"""
更新字段值
支持更新单个字段值,多个字段值(字段名 字符串或列表、元组,字段值 字典)
"""
req_body = self.data
# 字段列表循环更新
for p in self.fields_list:
# 入参类型判断
if isinstance(self.value_dict, dict):
# 参数在字典中不存在,则跳过
if p not in self.value_dict.keys():
print('ERROR: 字典中不存在参数[%s]。' % p)
continue
# 获取字典中参数的值
value = self.value_dict[p]
elif isinstance(self.value_dict, str):
value = self.value_dict
else:
print('函数入参[%s]类型不支持,请传入字符串或字典。' % self.value_dict)
break
# 更新数据类型为 xml 的参数值
if self.data_type.upper() == 'XML':
# 优先寻找是否存在指定更新参数,若有,则按指定参数更新
if '${' + p + '}' in req_body:
req_body = req_body.replace('${' + p + '}', value)
# 其次寻找标签参数值,若有,则按标签更新值
else:
# 检查标签是否存在,若存在
if '<' + p + '>' in req_body and '</' + p + '>' in req_body:
# 正则匹配
pattern = '<' + p + '>.*</' + p + '>'
new_field_and_value = '<' + p + '>' + str(value) + '</' + p + '>'
search_result = re.search(pattern, req_body)
# 若正则匹配结果存在,则进行字段值更新
if search_result is not None:
old_field_and_value = search_result.group()
req_body = req_body.replace(old_field_and_value, new_field_and_value)
else:
print('参数[%s]匹配标签失败,请检查报文中标签格式。' % p)
else:
# print('参数[%s]匹配标签失败,无此标签。' % p)
continue
# 更新数据类型为 xml 的参数值
elif self.data_type.upper() == 'JSON':
# json转换字典
if isinstance(self.data, dict):
req_body = self.data
else:
req_body = json.loads(self.data)
# 获取层级
node = p.split('.')
# 调用递归函数更新字段值
update_json_step(node, req_body, value)
# 非 xml,json的数据格式,报错退出
else:
print('ERROR: 不支持此数据类型[%s]' % self.data_type)
break
return req_body
接口初始化通用类
# create by: wyun
# create at: 2020/4/23 22:42
from api.comm.data_handle import DataHandle
def intf_base_init(data_type, request_body, **kwargs):
"""
接口初始化通用类
:param data_type: 数据类型,如:xml,json
:param request_body: 请求体
:param kwargs: 可变关键字参数
:return: 请求体
"""
return DataHandle(data_type, request_body, kwargs.keys(), kwargs).update_fields_value()
【重构之请求体或响应体操作基类】
# create by: wyun
# create at: 2020/5/13 11:48
import json
import re
""""
对请求响应处理功能优化
支持功能:
1. 读取报文中字段的值
1.1 读取xml格式报文字段的值: 使用的是正则匹配的方式实现,根据字段标签读取值,可能存在多个值,则返回值为列表;
1.2 读取json格式报文字段的值: 使用节点路径的方式实现,根据节点路径可能存在列表,值可能存在多个,按不同路径及值存为字典;
2. 更新字段值
2.1 更新xml格式报文字段值: 支持按标签(即字段名)更新,同时支持指定位置更新(标记:${字段名});
支持更新单个值,多个值,当存在多个匹配时,只支持更新第一个值或更新所有的值。
2.2 更新json格式报文字段值: 仅支持按指定精确路径更新单个值。
"""
def xml_get_field_value(body, field, value_dict=None):
"""
获取xml报文中的字段值,若存在多个则为列表
:param body: 请求体或响应体
:param field: 字段名
:param value_dict: 字段值字典
:return: value_dict: 值字典,field单个匹配,值为字符串;多个匹配 ,值为列表
"""
# 忽略大小写
pattern = re.compile('<' + field + '>(.*)</' + field + '>', re.I)
result_list = pattern.findall(body)
if not result_list:
print('参数[%s]提取失败,无匹配值。' % field)
elif len(result_list) == 1:
value_dict[field] = result_list[0]
else:
value_dict[field] = result_list
return value_dict
def xml_update_field_value(body, field, value_dict):
"""
更新xml报文中的字段值,若同字段名称更新多个值,则传入字典中的值为列表或元组等序列
:param body: 目标xml,请求体
:param field: 字段名
:param value_dict: 字段值,字符串或列表,元组类型
:return:
"""
value = value_dict
# 正则匹配规则
pattern = re.compile('<' + field + '>.*</' + field + '>', re.I)
# 1. 值为字符串,更新参数值
if isinstance(value, str):
# 只替换第一个
new_value = '<' + field + '>' + value + '</' + field + '>'
body = re.sub(pattern, new_value, body, count=1)
return body
# 2. 值为列表或元组等序列
# 匹配搜索所有满足项
findall = pattern.findall(body)
if len(findall) != len(value):
print('传入的参数[%s],值长度与实际长度[%s]不匹配。' % (value, len(findall)))
return None
for n, o in zip(value, findall):
old_value = o
new_value = '<' + field + '>' + n + '</' + field + '>'
body = body.replace(old_value, new_value, 1)
return body
def json_get_field_value(data_dict, field, value_dict=None):
"""
获取节点所有记录
:param data_dict: json请求体或响应体,字典格式
:param field: 节点路径
:param value_dict: 值字典
:return: value_dict: 当field路径未完全指定时,返回2重嵌套字典
"""
if value_dict is None:
value_dict = dict()
node = field
# 字典初始化,该字典用于存放细分节点(下一个节点遍历前一个节点并组合)
# 示例:{
# 'a': ['a'],
# 'b': ['a.b[0]'],
# 'c': ['a.b[0].c[0]', 'a.b[0].c[1]',
# 'a.b[0].c[2]', 'a.b[0].c[3]',
# 'a.b[0].c[4]'],
# 'd': []
# }
node_key = dict(zip(node, [[] for x in node]))
# 字典初始化,该字典用于存放各节点数据,和上面类似
node_key_data = dict(zip(node, [[] for x in node]))
try:
# 第一重循环,按节点路径遍历
for n in range(len(node)):
# 获取前一节点的节点路径组合,以及节点值组合
if n == 0:
if node[0] not in data_dict:
break
# 存放至字典对应的节点中
node_key[node[0]].append(node[n])
node_key_data[node[0]].append(data_dict[node[0]])
continue
# 前一个节点的数据、以及组合个数
back_data = node_key_data[node[n-1]]
back_no = len(node_key[node[n-1]])
# 第二重循环,根据前一个节点的组合数量,遍历每一个节点路径
for v in range(back_no):
# 若当前节点,在对应的节点路径数据中不存在
# 有可能是指定列表索引位置的方式,包含[]
if node[n] not in back_data[v]:
if '[' in node[n] and ']' in node[n]:
node_key[node[n]].append(node_key[node[n - 1]][v] + '.' + node[n])
this_node, this_node_index_str = node[n].split('[')
try:
this_node_index = int(this_node_index_str.split(']')[0])
except:
print('参数节点[%s]索引值不存在。' % node[n])
this_node_index = None
node_key_data[node[n]].append(back_data[v][this_node][this_node_index])
continue
else:
continue
# 当前路径,当前节点的数据
cur_node_data = back_data[v][node[n]]
# 判断如果是字典,说明不用细分,直接获取对应的节点名称以及节点数据值即可
if isinstance(cur_node_data, dict):
node_key[node[n]].append(node_key[node[n - 1]][v] + '.' + node[n])
node_key_data[node[n]].append(cur_node_data)
continue
# 如果非字典,则可能为列表,或达到最后一层节点的数据了
# 处理最后一层节点
if n == len(node) - 1:
node_key[node[n]].append(node_key[node[n - 1]][v] + '.' + node[n])
node_key_data[node[n]].append(cur_node_data)
continue
# 前面的情况都不是,那么只剩下最后一种,该节点对应数据为列表形式了
# 获取列表长度
cur_node_len = len(cur_node_data)
# 第三重循环,根据列表数量,分别需要组合前面的节点路径,再获取对应的节点名以及节点数据
for vn in range(cur_node_len):
node_key[node[n]].append(node_key[node[n - 1]][v] + '.' + node[n] + '[' + str(vn) + ']')
node_key_data[node[n]].append(cur_node_data[vn])
# print(node_key)
# print(node_key_data)
except:
pass
# 判断如果节点没有嵌套列表这种,就不用多层返回了
if node_key[node[-1]]:
# 内层key和外层key相等
if '.'.join(field) == node_key[node[-1]][0]:
value_dict['.'.join(field)] = node_key_data[node[-1]][0]
# 嵌套2层字典的场景
else:
value_dict['.'.join(field)] = dict(zip(node_key[node[-1]], node_key_data[node[-1]]))
else:
value_dict['.'.join(field)] = None
return value_dict
def is_exist_node(node, json_str, i=0):
"""
判断节点路径是否存在
:param node: 字段节点路径, 列表类型
:param json_str: json报文
:param i: 计数标志
:return: True or False
"""
# 当前节点索引(负向)
node_index = -len(node) + i
if node[node_index] not in json_str:
# 如果包含[n]形式,说明节点为列表,需处理
if '[' in node[node_index] and ']' in node[node_index]:
list_node, list_index = node[node_index].split('[')
index = list_index.split(']')[0]
if index is None or index == '':
print('ERROR: [%s]参数传入错误,请指定列表[%s]索引.' % (node, list_node))
return False
else:
index = int(index)
return is_exist_node(node, json_str[list_node][index], i + 1)
else:
print('[%s]字段节点[%s]不存在.' % (node, node[node_index]))
return False
# 判断如果当前节点为最后一个节点,则返回True
if node_index == -1:
return True
return is_exist_node(node, json_str[node[node_index]], i + 1)
# 递归调用,更新json中的字段值
def update_json_step(node, json_str, value, i=0):
# 当前节点索引(负向)
node_index = -len(node) + i
if node[node_index] not in json_str:
# 如果包含[n]形式,说明节点为列表,需处理
if '[' in node[node_index] and ']' in node[node_index]:
list_node, list_index = node[node_index].split('[')
index = list_index.split(']')[0]
if index is None or index == '':
print('ERROR: 参数传入错误,请指定列表[%s]索引.' % list_node)
else:
index = int(index)
return update_json_step(node, json_str[list_node][index], value, i + 1)
# 判断如果当前节点为最后一个节点,则更新value值
if node_index == -1:
json_str[node[-1]] = value
return json_str
return update_json_step(node, json_str[node[node_index]], value, i + 1)
class ReqResHandle:
def __init__(self, data_type, data_msg, fields, value_dict=None):
"""
处理请求体或响应体数据,读取或更新字段值
:param data_type: 数据类型:xml,json
:param data_msg: 请求体或响应体
:param fields: 字段值,支持多字读方式,字段间逗号隔开;或传入列表、元组
json格式:节点路径,支持指定列表索引位置的方式(如:a.b[1].c[2].d),也支持按节点提取所有(如:a.b.c.d)
:param value_dict: 以字典键值对保存字段值(注:当单个字段对应多个值时,xml以列表方式返回,json则返回多重嵌套字典)
"""
self.data_type = data_type
self.data = data_msg
# fields支持str,list方式,str自动转换为list
if isinstance(fields, str):
self.fields = fields
self.fields_list = []
if ',' in fields:
self.fields_list = fields.strip().split(',')
else:
self.fields_list.append(fields.strip())
elif isinstance(fields, list):
self.fields_list = fields
else:
self.fields_list = list(fields)
# 初始化字典值
if value_dict is None:
self.value_dict = dict()
else:
self.value_dict = value_dict
def get_fields_value(self):
"""
获取字段值
1. 支持获取多个字段值,输入字符串或列表, 元组
"""
step_dict = self.value_dict
# 字段列表循环获取
for p in self.fields_list:
if p == '':
continue
# 处理xml格式报文
if self.data_type.upper() == 'XML':
step_dict = xml_get_field_value(self.data, p, step_dict)
# 处理json格式报文
elif self.data_type.upper() == 'JSON':
# 获取层级(使用.隔开)
node = p.split('.')
# json转换字典
if isinstance(self.data, dict):
temp = self.data
else:
temp = json.loads(self.data)
step_dict = json_get_field_value(temp, node, step_dict)
# 非 xml,json的数据格式,报错退出
else:
print('ERROR: 不支持此数据类型[%s]' % self.data_type)
break
return step_dict
def update_fields_value(self):
"""
更新字段值
支持更新单个字段值,多个字段值(字段名 字符串或列表、元组,字段值 字典)
"""
req_body = self.data
# 字段列表循环更新
for p in self.fields_list:
# 入参类型判断
if isinstance(self.value_dict, dict):
# 参数在字典中不存在,则跳过
if p not in self.value_dict.keys():
print('ERROR: 字典中不存在参数[%s]。' % p)
continue
# 获取字典中参数的值
value = self.value_dict[p]
elif isinstance(self.value_dict, str):
value = self.value_dict
else:
print('函数入参[%s]类型不支持,请传入字符串或字典。' % self.value_dict)
break
# 更新数据类型为 xml 的参数值
if self.data_type.upper() == 'XML':
req_body = xml_update_field_value(req_body, p, value)
# 更新数据类型为 json 的参数值
elif self.data_type.upper() == 'JSON':
# json转换字典
if not isinstance(req_body, dict):
req_body = json.loads(req_body)
# 获取层级
node = p.split('.')
# 判断值是否为字典(因为提取字段值时,会有2重字典的场景,所以适配了这种情况)
if isinstance(value, dict):
for k in value.keys():
k_node = k.split('.')
if not is_exist_node(k_node, req_body):
continue
update_json_step(k_node, req_body, value[k])
else:
if not is_exist_node(node, req_body):
continue
# 调用递归函数更新字段值
update_json_step(node, req_body, value)
# 非 xml,json的数据格式,报错退出
else:
print('ERROR: 不支持此数据类型[%s]' % self.data_type)
break
return req_body


