理由
在日常接口测试,或压力测试工作中,有很多时候需要造数据,而且大部分时候是没有真实数据;那时只能使劲浑身解数 “巧妇难为无米之炊” 了;为了应对这类的突发情况,自己写了一个勉强还算是能用的程序来满足未来的需要;这里分享到社区,各位大大,欢迎指点
设计及实现
1.复制 接口同名 json 格式的接口示例数据,创建同名 csv 文件
第一步 :DataInfo类初始化方法,参数 (1.接口名称、2.存储接口 json 示例文件路径 、3.放置数据的 CSV 文件路径)
第二部: dataInfo.write_param_header_and_type() 根据 json 文件创建 csv 文件,创建 csv 固定格式 表头及类型
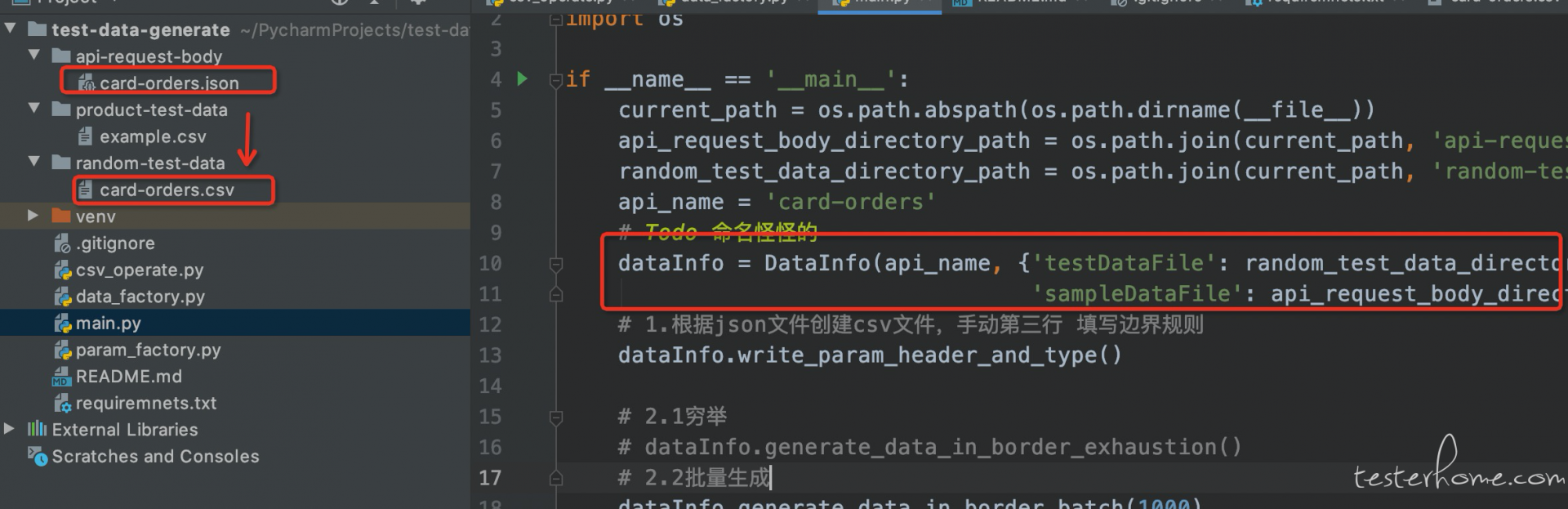
CSV 文件结构:
第一行原始字段: 读取示例 json 文件, 数据 field 转换为 csv 文件的
第二行字段类型: 读取示例 json 文件, 识别 fieldType int 和 str
第三行字段边界条件: 手动填写每个字段的 业务边界

2. 手动填写字段边界条件规则:
支持类型: 日期(年 - 月-日) ; 日期(年 - 月-日时:分:秒); 数值 ; 字符串
边界条件支持: < ; > ; <= ; >= ; 有限状态或值 ; 唯一(不允许重复)
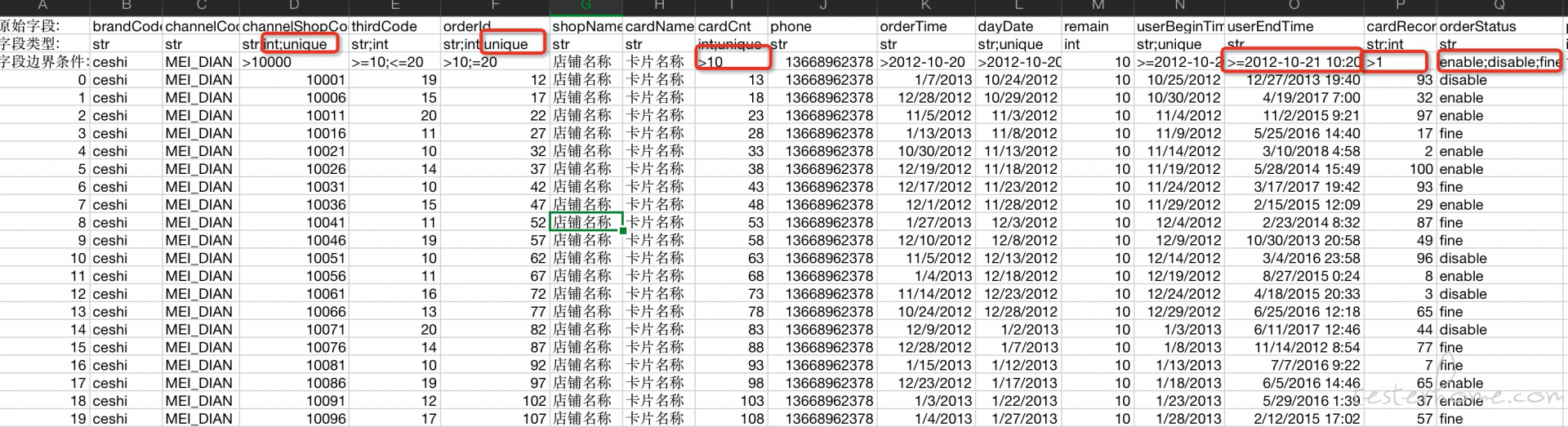
说到这里可能有点蒙了:下面说明一下这里面边界描述的规则:
1) 字符 长度边界 的描述
例如:一串中文 数据,限制在 最大长度 100,最小长度 1 写为:(目前中文暂时没支持,是随机的大写字母)
<100; >1如包含则 <=100; >=1
还可以写为 <100;99.9
( Ps. 这表示小于 100 ,包含 99.9, 因为是边界取值是随机的,不一定包含 99.9,如果你需要强调这个值可以上面这样写)
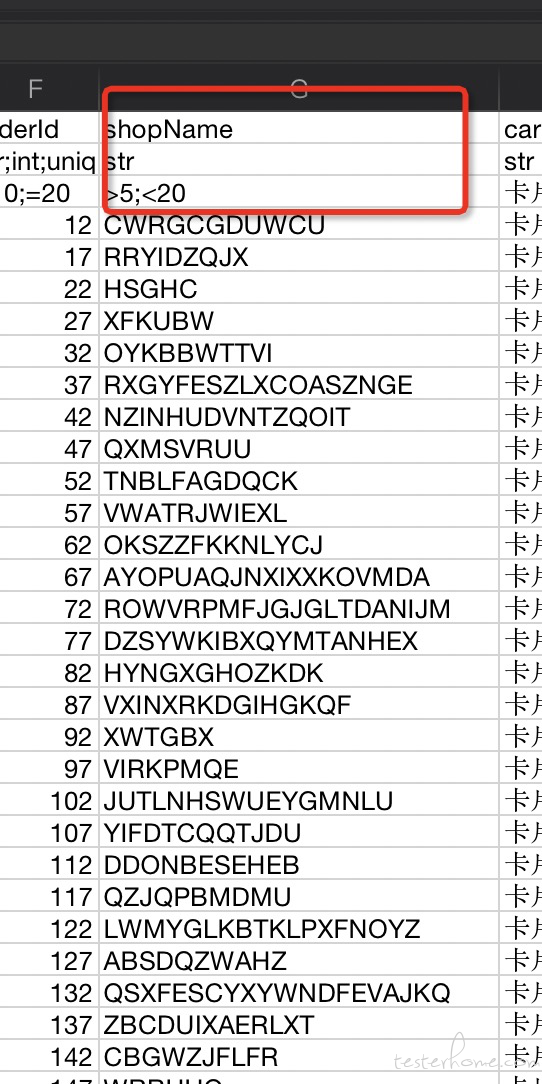
2) 字符串 有限状态 描述
例如:某某状态,如订单状态 只可能是; 进行中 或 已结束 写为:
processing;end

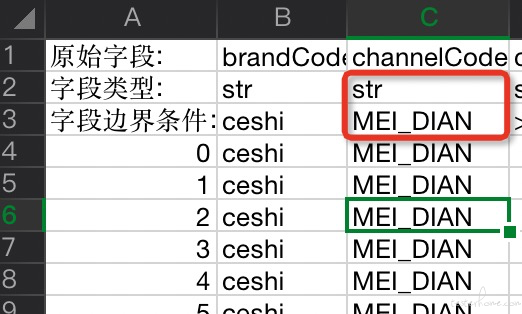
再细分还包含 日期 和 内部是数值 的字符串
先说一下 日期格式 分为 Y-m-d 和 Y-m-d H:M:S 2 种格式(目前只弄了这两种,这里其实是可以改的,非常简单,改改 datefmt 就可以了)
3) 日期 范围 描述支持有 大于;小于;大于等于;小于等于 多条件以分号分割
例如:
晚于 2012-10-20 12:20:12 早于 2019-10-20 12:20:12 写为:
>2012-10-20 12:20:12;<2019-10-20 12:20:12
或单独的
2019-10-20 前写为:
<2019-10-20
晚于 2012-10-20,早于 2019-10-20 写为:
>2012-10-20;<2019-10-20
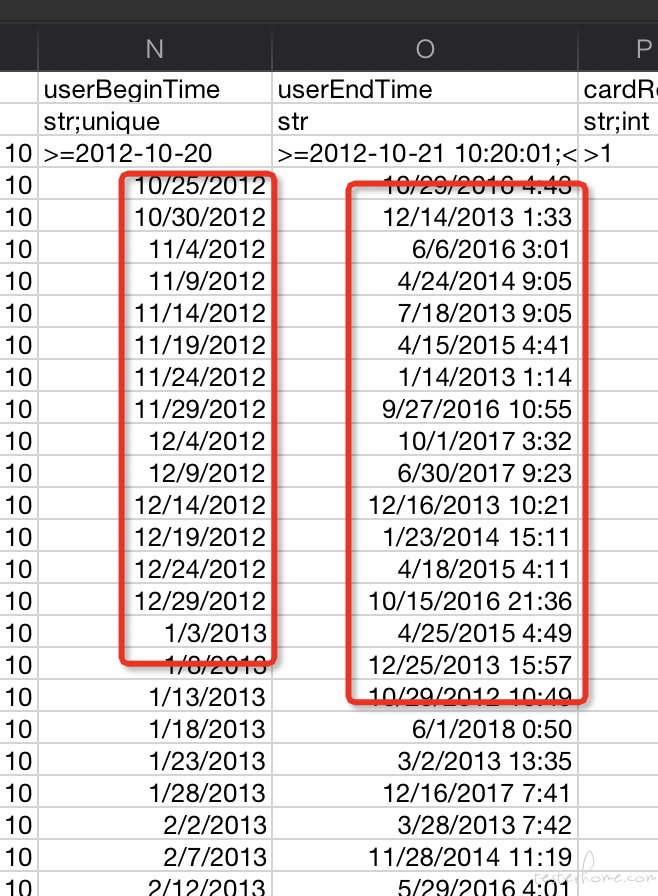
4) 1 个或多个日期,以分号分割
例如:只有2012-10-20 12:20:12 ;2019-10-20 12:20:12这个 2 个值,以分号分割
5) 字符串中的内部数值类型
也就是"1" ,带英文引号的这种 ,直接在第二行 字段 类型 str 后加入int特性说明,以分号分割

6) 字符串中的数值没有重复的,唯一(目前实现是通过自增)
类型这一格后面加入unique 特性说明,以分号分割
下面的日期没有重复的
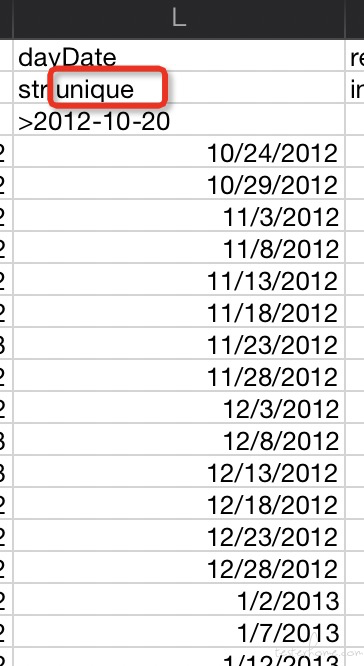
7) 剩下的还有 int 值的范围、 唯一及有限状态和值,都可以参考字符串
数据生成
聊到这里填写完边界规则,就可以生成数据了,这里生成数据有 2 种方式
1.根据取值的范围,该随机的随机,批量生成多组数据
这批数据主要是大批量数据的生成,做一些有需要的测试
2.根据 取值范围,再依据测试用例的设计方法取,等价类边界值划分
1)小于 大于,
如果是 str 长度 max-1 、min+1 、再随机 一个中间长度 3 个正确可能取值
如果是 int 值 max-1、 min+1、 再随机一个中间值 3 个正确可能取值
2)小于等于 大于等于
str 长度 min、max 、再随机 一个中间长度 3 个正确可能取值
int 值 min、 max、 再随机一个中间值 3 个正确可能取值
3)单个 小于、大于、 或等于条件
2 个正确的可能取值
4)有限状态,可能取值数量 有限状态的个数
简单说是将 边界的值 按 一些规则生成 几个预期值,再进行穷举组合(这里没有支持唯一,感觉应该可以做的,但目前还没想清楚..)
这批数据是为了验证接口的正常 边界,主要是 功能测试
批量数据
dataInfo.generate_data_in_border_batch(1000) 传递参数(1.总数量)
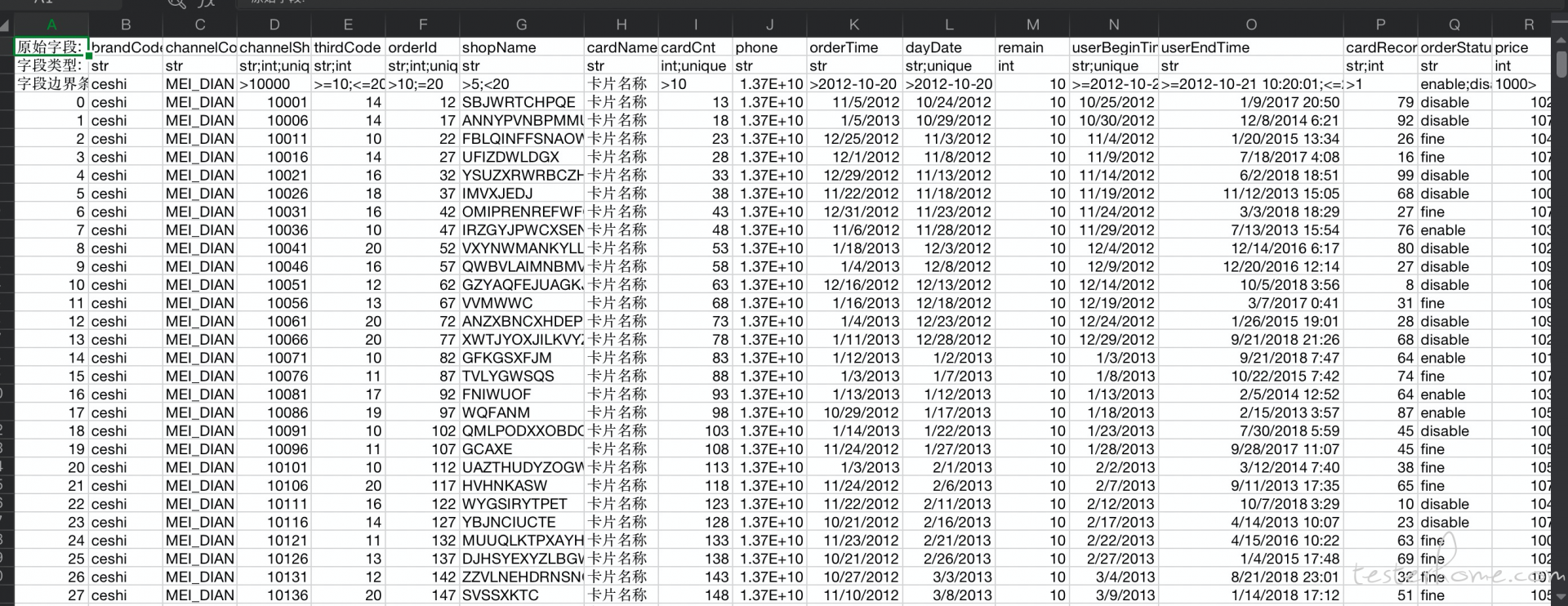
取值穷举
dataInfo.generate_data_in_border_exhaustion()
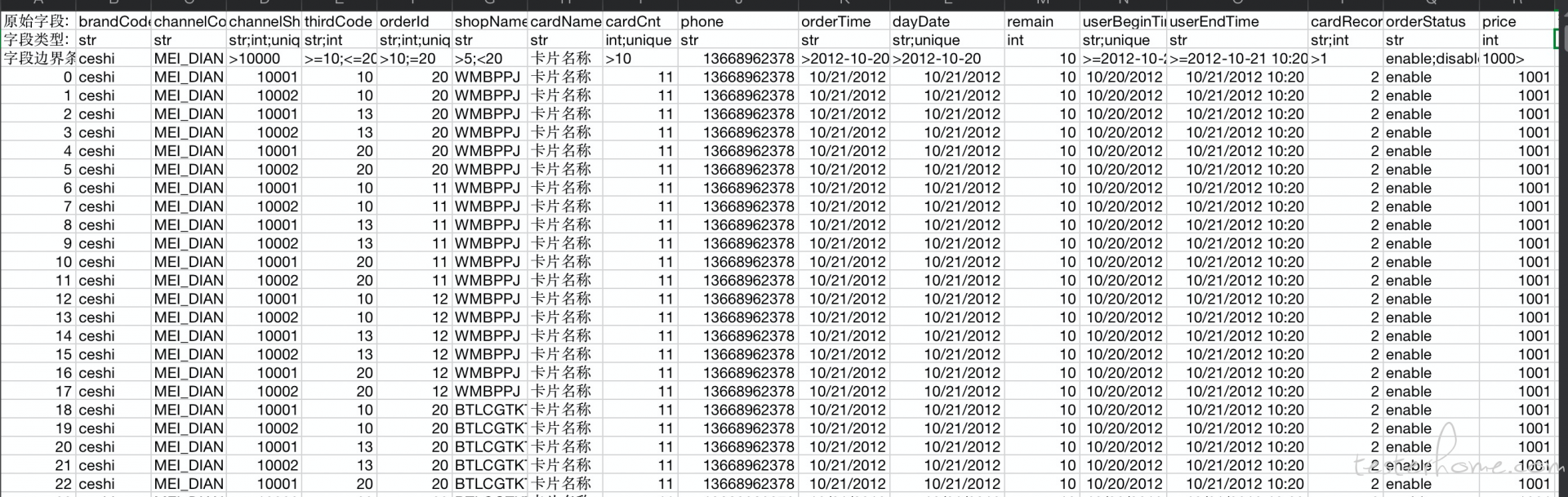
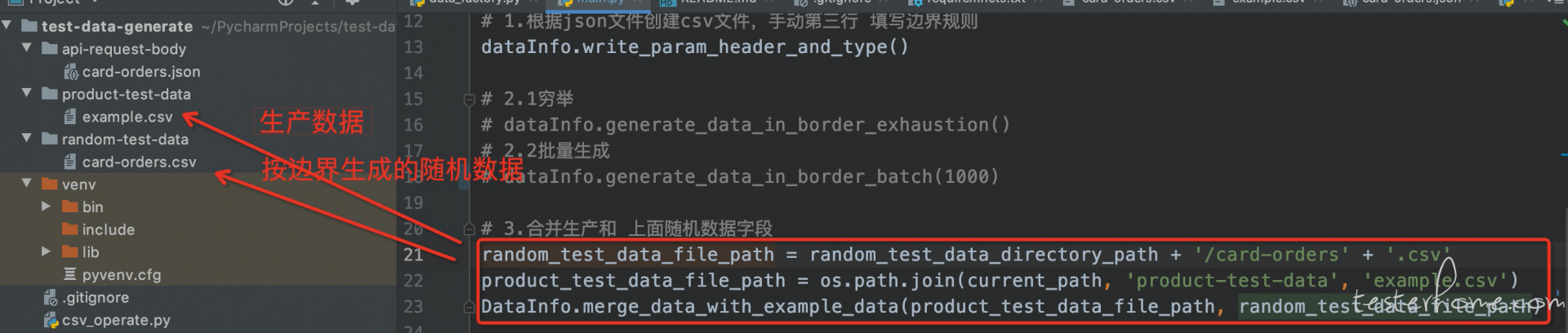
上面的截图,是程序运行后的,可以观察一下大概就能发现里面的区别了
- 利用 pands 支持 部分字段是生产数据.csv 文件 与 边界规则随机生成的批量数据的 数据合并(优先级是:生产覆盖随机生成的)
为了满足,已有的生产数据 与 规则生成数据的混合
其实还有异常数据的生成,也就是不在规则内的类型异常 和 业务异常数据(后续有时间再做)
OK,项目源代码如下,有需要的可以试试
工具源代码地址