该文原创为新潮质量保障技术团队中的 “上进的中年软件测试从业者”,用于技术交流分享
开篇
上一篇测试平台-RPC 服务调用优化有提到过开发过程中的 TODO 标识,用现在较流行的一种说法就是技术债,欠的债迟早都要还的,只是时间问题。昨天看到一种说法说好人都不长寿,原因在于好人承受了太多的不公平,在心理上难免会有压抑。个人觉得有些片面,或者说只能代表相对善良、平凡且不善言辞的一类人,而如鲁智深般随潮圆寂而终得善终的人,可能就是另外一类超凡脱俗的存在。
之前有介绍过测试平台的服务拆过程测试平台之服务拆分,虽然过程还算顺利,方案也比较贴合当前的使用场景。但是后续的使用过程中还是填了一些坑:
- 如容器化部署过程中的的文件处理。
- 如服务间调用过程中的 Response 解析。
- 如提高 RPC 服务的可用性。
- 减少服务间的依赖性等。
最开始遇到的那些坑,已经通过各种方案解决了。如文件处理可以采用传输的方式解决、服务间的调用解析可以用序列化的方式处理、RPC 服务的可用性可以通过非长连接的方式解决等。但是对于 Response 解析过程没有做过多调研,只是解决了问题。
背景
前几天又遇到一例新坑,严格意义上讲不算是新坑,因为它隶属于 Response 解析部分,更算是一例技术债务。大概的问题是,从 RPC 服务端返回的字典数据在进行 pandas 处理时异常的慢。
本来想通过 RPC 服务调用公共服务提供的 HTTP 请求,并返回响应数据,然后进行数据的整合处理。我们都知道,接口返回的数据一般格式如下:
{"msg": "OK", "code": 200, data: [{"name": "zhangsan", "account": 97}, {"name": "lisi", "account": 68}]}
通用的说法就是一个 json 的数据格式,在 python 里面这就是一个 dict 类型的数据,data 字段的值为列表,列表的每个元素可能列表、字典或者各种混合的嵌套类型。
我们这次案例就是最普通的场景,data 的值为列表套字典的方式,返回的数据大概有几千条。然后再用 pandas 进行 groupby, 结果发现用时居然是 27 秒。如果通过接口实时查询并处理返回给前端,时间上面是不允许了。
调研
最开始在调查方向是在 pandas 的 Dataframe 处理数据慢上面,还尝试通过各种途径对数据进行预处理,包括二维数组的旋转,数据聚合的方式,结果除了知道更多的数据处理途径,并没有解决实质的问题。最后请教了一位专家,然后发现同样的数据在他的电脑上面居然是秒级的处理结果。然后就发现了,最初的调查方向上面是错误的,pandas 作为相对成型的数据处理模块,不应该有这样的性能问题。最终发现问题是出现在 RPC 服务端 Response 结果的处理上面(也就是之前没有搞清楚技术债)。
我们首先对返回的数据进行类型解析:
[<netref class 'rpyc.core.netref.builtins.dict'>, <netref class 'rpyc.core.netref.builtins.dict'>, <netref class 'rpyc.core.netref.builtins.dict'>, <netref class 'rpyc.core.netref.builtins.dict'>, <netref class 'rpyc.core.netref.builtins.dict'>]
这里我们就会发现,列表里面的每个元素都是一个的对象,这里我们大胆的猜测一下,在 Pandas 进行数据聚合的时候,实际上针对每个元素都与 RPC 服务端都进行了交互,这应该就是通信的时间成本所在了。
解决
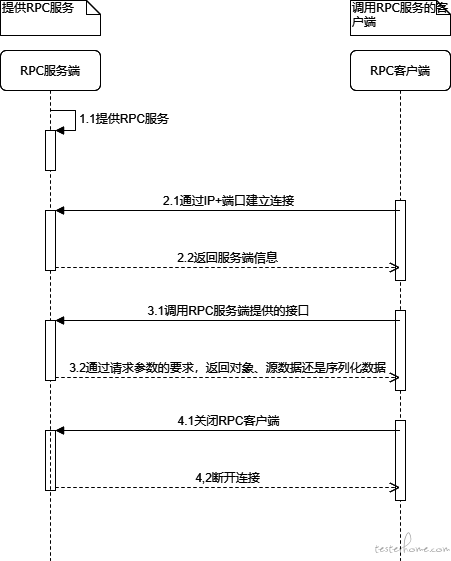
问题找到了,那解决起来就容易了,因为之前就已经遇到了 Response 解析的问题,可以在返回结果之前,先在 RPC 服务端对数据进行序列化处理(序列化的过程实际上就是二进制的过程,这里我们给自己再留一个技术债,调研序列化的实现过程),然后再 RPC 客户端进行反序列化处理即可还原数据。大概的流程如下:
结语
由于篇幅原因,今天我只讲到处理过程。下一期(这周内)我们将介绍数据在 RPC 传输过程中的限制、box 理论、以及为什么 byte 类型会直接返回给客户端。另外会介绍一款源码追踪的神器 trace,能够更便于追究真相的同学探究实现原理,让自己不做一个小白。
还是那句话,探究的路上注定孤独,愿与你结伴同行!