测试覆盖率 从 jacoco 报告数据分析,python 脚本实现增量覆盖率统计
jacoco 的增量覆盖率报告实现的逻辑和一些个人想法。
jacoco 报告分析
从 jacococli.jar 的使用方法可以看到,导出的文件格式有 csv,xml,html 等多种格式。
进行尝试后,可以看到 xml 是数据信息较全的一种类型。

下面对 xml 的报告构成过一个分析:
1、counter 标签
<counter type="INSTRUCTION" missed="4171" covered="3280"/>
<counter type="BRANCH" missed="231" covered="64"/>
<counter type="LINE" missed="1154" covered="1009"/>
<counter type="COMPLEXITY" missed="586" covered="483"/>
<counter type="METHOD" missed="432" covered="478"/>
<counter type="CLASS" missed="31" covered="51"/>
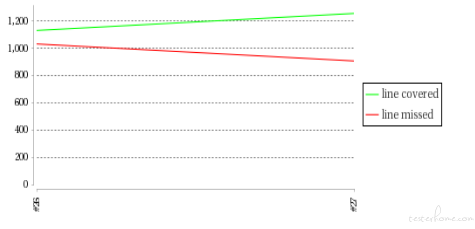
记录了行覆盖率、 类覆盖率、 分支覆盖率、 方法覆盖率、指令覆盖、 圈复杂度的具体覆盖和未覆盖数。其中,LINE 行覆盖率与 jacoco 的整体覆盖率波形图中的数据是一致的。
2、package 标签
<package name="com/XXXXXXXXXX">
<class name="com/XXXXXXXXXXXXXXXX" sourcefilename="XXXXX.java">
<method name="onBeforeSave" desc="(Lorg/xXX;)V" line="34">
<counter type="INSTRUCTION" missed="0" covered="17"/>
<counter type="BRANCH" missed="1" covered="1"/>
<counter type="LINE" missed="0" covered="5"/>
<counter type="COMPLEXITY" missed="1" covered="1"/>
<counter type="METHOD" missed="0" covered="1"/>
</method>
<counter type="INSTRUCTION" missed="0" covered="118"/>
<counter type="BRANCH" missed="1" covered="5"/>
<counter type="LINE" missed="0" covered="25"/>
<counter type="COMPLEXITY" missed="1" covered="6"/>
<counter type="METHOD" missed="0" covered="4"/>
<counter type="CLASS" missed="0" covered="1"/>
</class>
<sourcefile name="XXXXXXXXX.java">
<line nr="27" mi="0" ci="3" mb="0" cb="0"/>
<line nr="34" mi="0" ci="4" mb="0" cb="0"/>
...
<counter type="INSTRUCTION" missed="0" covered="118"/>
<counter type="BRANCH" missed="1" covered="5"/>
<counter type="LINE" missed="0" covered="25"/>
<counter type="COMPLEXITY" missed="1" covered="6"/>
<counter type="METHOD" missed="0" covered="4"/>
<counter type="CLASS" missed="0" covered="1"/>
</sourcefile>
<counter type="INSTRUCTION" missed="0" covered="118"/>
<counter type="BRANCH" missed="1" covered="5"/>
<counter type="LINE" missed="0" covered="25"/>
<counter type="COMPLEXITY" missed="1" covered="6"/>
<counter type="METHOD" missed="0" covered="4"/>
<counter type="CLASS" missed="0" covered="1"/>
</package>
包含主要信息:类、行覆盖信息、包内行覆盖率统计数据。
sourcefile 中就是源码中某一行的执行情况,与最终 jacoco html 的页面样式对应关系如下


处理 jacoco 的 xml 报告原始数据,生成增量报告
搞清楚 xml 报告和 html 报告中的逻辑关系后,就可以着手开始对 xml 中的数据进行处理定制自己的类型报告了。
由于前端开发能力有限,打算直接修改 jacoco 的原始报告的展示逻辑,达到展示增量报告的目的。
处理逻辑
处理的基本步骤说明
三个数据采集:代码差异、覆盖率 exec 文件、代码文件(src 目录、class 目录)
整体处理步骤:
1、将代码差异与代码源文件进行比对,生成标记出代码新增的 java 文件
2、通过 jacococli 的 report 方法将 exec 文件转成 xml 数据格式
3、分析覆盖率报告 xml 文件,①计算各类覆盖率;②生成带有覆盖率信息、新增代码标识的仿 jacoco html 报告的网页
实现说明
1、标记代码差异
在 jenkins 中增加 shell 指令执行 git diff。
根据研发人员对代码上线的管理方式,挑选合适的比对对象。例如,主干上线,分支开发的,可以每次使用勾选的分支与上一次上线分支进行比对;如果是小项目直接主干开发的,可以选择增加 git 参数,revision 来标识比对的基准历史版本。
git diff "origin/prod" ${branch} ./src/main/java > /gitdifffile/${JOB_NAME}.txt
git diff ${old_version} ${GIT_COMMIT} ./src/main/java > /gitdifffile/${JOB_NAME}.txt
根据获取到的代码差异信息,与 src 目录下的原始文件比对,标记出代码差异。
细节:
- 空行、符号的过滤;“import XXX”,“log” 等不重要内容差异的过滤;
- 新增代码、删除代码仍使用 git 比对结果的方式进行标记,“+” 标识新增,“-” 标识删减
- 可根据需要过滤部分文件的差异。
基本上就是 python 的文本比对,文本读取和写入。
2、覆盖率数据 exec 文件的保存
由于实际使用的场景,希望获取的信息区间为某次迭代周期内。
增加启停脚本入参 isnewstory,
- isnewstory=true 属于新迭代的情况下:服务停止前不进行 dump 操作,且删除保留的历史 exec 文件。
- isnewstory=False 非新迭代,每次项目停止的时候,进行 dump 保存执行数据。确保是完整的版本测试执行覆盖率数据
3、报告的展示
报告分为覆盖率数据报告和详细代码标识两类,通过 python 的 flask 框架,全端仍使用 jacoco 的前端(前端不好,不想改了)
覆盖率数据报告页面
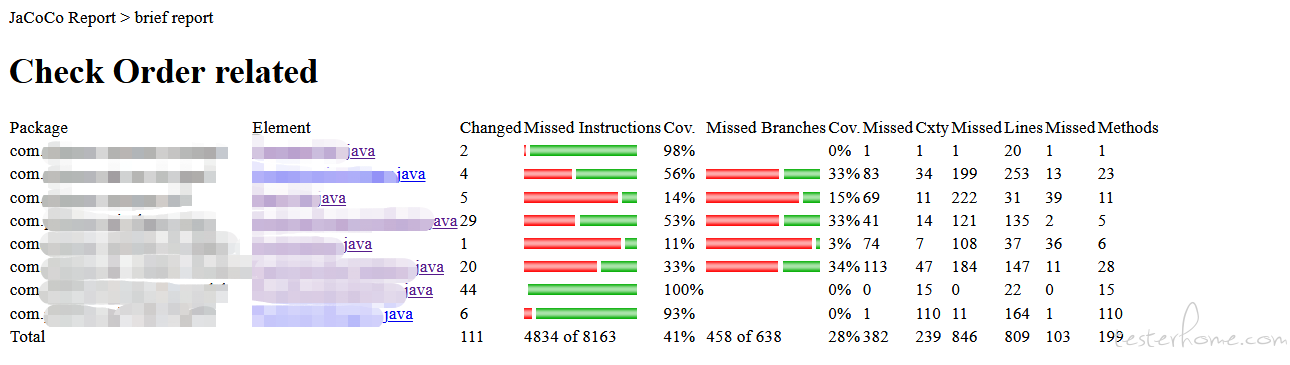
大概说下流程
- 刷新 brief report 页面时,通过 os.popen(jacococli.jar 的命令),实时获取最新覆盖率数据 (dump),并将多个 exec 合成一个 (merge),生成最新的 jacoco xml 报告 (report)
- 根据 gitdiff 找到与上线版本不同的代码,查找这部分代码对应的覆盖率数据,过滤掉不需要的。python 读写文件,解析 xml,并计算
详细代码标识页面

- 每次在 jenkins 构建过程中,即调用脚本将 gitdiff 的数据转为含有代码增删标识的 java 文件
- 调用详细代码标识页面时,获取对应的 java 文件,并实时分析 jacoco xml 报告的对应内容,添加与 jacoco 原始页面一样的样式标识。
总结
当前的问题
1、为了提供更全面的代码上下文进行参考,并未细化到具体方法。如果覆盖率数据要提供更高效准确的覆盖率判断标准,则必须再细化和深入,实现难度比较大。
2、实际统计的数据与测试的覆盖仍存在一定的差异。例如完全覆盖也不能说明测试的全面。如果是漏了一种业务场景,那覆盖率 100% 也没有意义。
未覆盖到怎么办
根据从这套工具开始使用,到现在,几乎每次在上线前都会遇到新增代码标识为红色,或者分支没有覆盖到的情况,除非是那种非常非常小的改动。
未覆盖到有一些情况就比较无奈
1、部分异常捕获的代码段
try {
.......
}catch (Exception e) {
log.error("save to cache error", e.getMessage());
}
异常捕获后并无其它处理逻辑,仅仅只是打印问题。
如果是普通的场景还比较好涉及测试用例,但很简单的功能中,这个部分从接口、前端操作触发的数据流向触发不到的。确认这样的情况,通常就会放弃这条未覆盖。
2、修复 bug,例如仅仅判断的边界值进行了修改等,则回归范围并不覆盖完整逻辑的,也不会为了达到 100% 的覆盖率而执行完整用例。
3、很多业务渐渐使用频率已经几乎为 0 ,历史代码还留着不删(怕出问题)的。这种最坑。
个人想法
覆盖率数据个人觉得更大的意义在于评估提测与实际代码更改的信息是否相符,另外在确认业务场景和处理逻辑后,通过覆盖率结果来进行查漏补缺。在某些简单的场景下,可以当做是一个白盒测试的途径。