通过抓包得到的如图 1
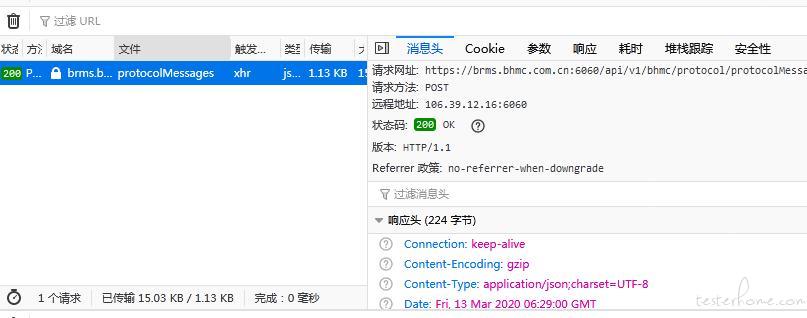
,在抓包栏中直接双击这个文件,可以在浏览器中打开一个窗口并显示图二(网页内的内容是目标数据)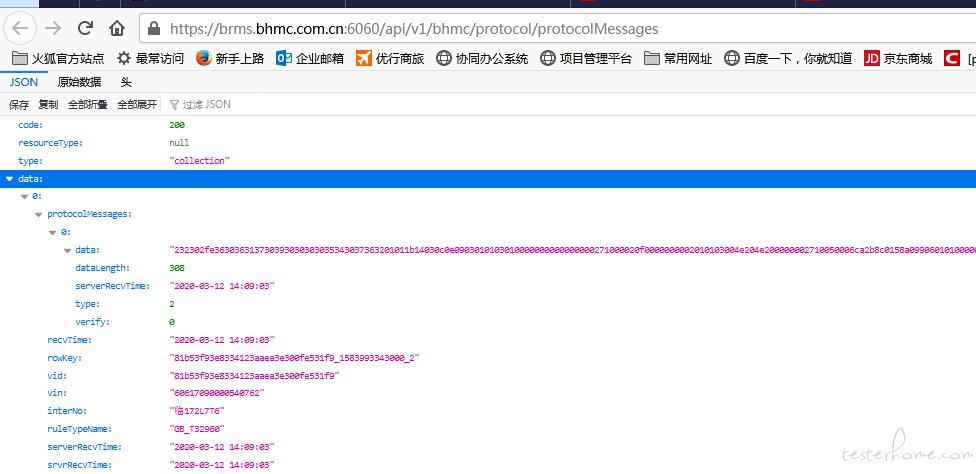
,如果单独的将图一中的请求网址 输入网页得到的是图三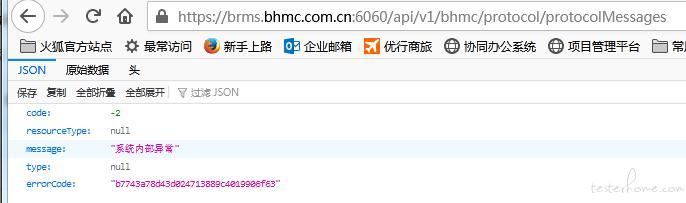
使用代码获取的结果 和图三一致,如下图
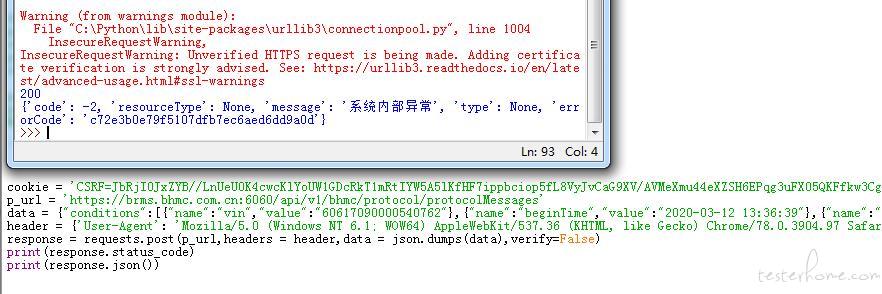
求助:这种情况通过 requests 是否能获取(selenium content = driver.page_source 可以获取,但是不打算使用这种方式)下图中的内容

PS:
1、代码中的 header 还有 cookie 都是从抓包内容中复制出来,data 是复制的抓包中的有效载荷内容
2、背景:网页账户密码登录,未登出,所以脚本中 只写获取部分,此时的 cookie 未失效