专栏文章 用强化学习实现测试机器人的探讨
测试同学第一次看到某个产品,在不了解产品逻辑的前提下就能进行简单的测试,并且发现大量 bug。这是大家司空见惯,但是让自动化代码望尘莫及的高度。
那么我们能否创造出一个等价的测试机器人呢?
现在可以给出的答案是:
1.利用自动化编程几乎无法实现(原因很简单:程序创造的规则空间很难解释复杂的产品空间,即使产品之间存在大量相似之处)
2.初级的测试同学是高智能体,具备看的能力:文字识别、颜色识别、控件识别等;行为能力:点击、输入、拖拽、滑动等;推理能力:展现是否符合预期;决策能力:是否提 bug。任何一种能力都是很难利用人工智能实现的。
但是我们仍然期望使用机器人实现其中部分能力,先从 UI 遍历开始吧。
UI 遍历是各类客户端软件的强需求,它的目的往往不是发现逻辑 bug,而是在产品迭代中,解放测试资源,扩大测试边界,弥补测试遗漏。
与基于树遍历的 UI 遍历算法相比,我们期望脱离开遍历算法的制约,真正的以覆盖更多产品功能为目标进行探索。
下面我们进入本文的主题:如何用机器学习算法实现客户端产品的 UI 遍历功能?
说到机器学习,第一个想到的肯定是监督学习,如果我们收集到大量产品,在产品上标注控件(比如按钮、输入框、滑动按钮等),那么我们可以利用神经网络对于软件图片,这种非结构化数据的强大处理能力,训练模型。随着数据量的增加,模型能力不断加强。
但是数据成本对于一般的测试团队来说已经是无法逾越的鸿沟。
我们可以将目光移动到强化学习上,这个生机勃勃,令人瞩目的领域。
大家知道强化学习更多是从 Alpha GO 的围棋,自动驾驶,星际争霸、Dota 游戏等事件中了解到的。强化学习其实有很悠久的历史,早在 20 世纪 50 年代的控制理论中就产生了 MDP(马尔可夫决策过程),以及 Bellman 公式,这是强化学习的基础理论。
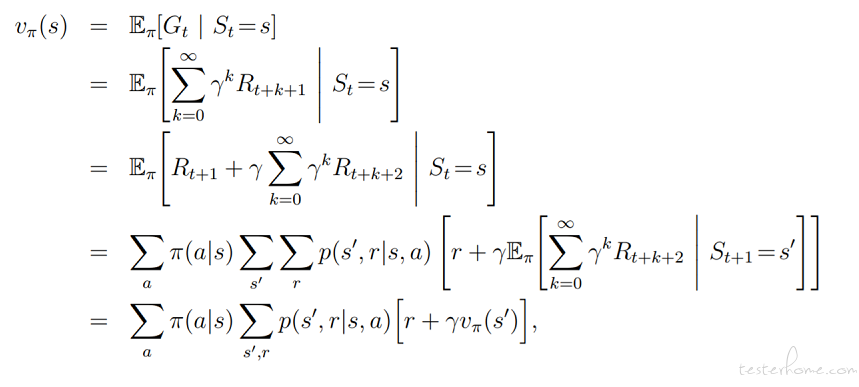
伴随深度神经网络对于非结构化数据的强大处理能力,我们可以把产品界面图片输入到神经网络中,提取细节特征。
下面我们定义 MDP 中的四要素:S(状态),A(动作),R(奖励),T(转移概率)。
1.S 可以认为是软件界面图片
2.A 可以先控制下范围,比如只考虑点击操作。软件界面经过网格划分(网格最小单元是 1 个像素),可以定义离散的操作集合:点击坐标(x,y)
3.R 有几种标量可以参考:图片差异、系统资源变化(CPU,内存,磁盘 IO,网络 IO 等),以及其他数据
4.T 由于软件界面转移几乎都是确定概率,所以可以理解是 P(S‘|S,A) = 1
软件界面图片 S 进行特征提取常用的方法:
1.如果 RGB 图片,转成灰度图,直接使用图片像素值,统一不同图片大小的特征向量长度
2.特征点提取,例如 SIFT 等方法,相比 1 进行了特征缩减
3.卷积神经网络,进行特征提取
动作 A 可以进行网格划分,根据计算复杂度,控制网格单元的大小。
奖励 R 是值得探讨的领域,R 需要与强化学习的目标统一:
1.界面变化,例如 PSNR 值等容易受到界面自身就是变化的影响
2.性能参数变化,有些论文里使用该数值的绝对值来作为奖励,但是该奖励真实目标,只是间接反应
3.代码覆盖度数据,我们推荐这种数据,奖励与目标相统一
4.如果是以发现 bug 为目的,可以结合 ANR、crash、预置期望点等方式(ANR 和 crash 由于发生頻率低,会遇到稀疏反馈问题,导致收
敛慢)
Agent 就是我们的自动化决策系统,action 是 A,Environment 是软件界面,符合强化学习的交互过程。
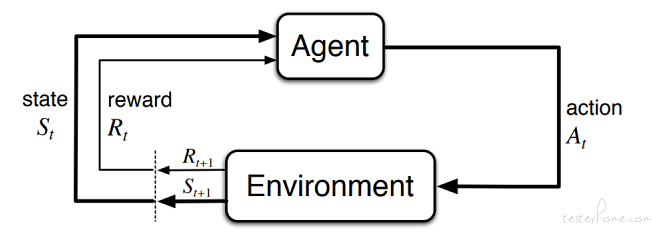
建议使用深度神经网络处理图片和动作,形成动作价值函数 Q,将代码覆盖度增加值当做 R,为了保持试探,策略采用ε-贪心策略。
简单的框架:
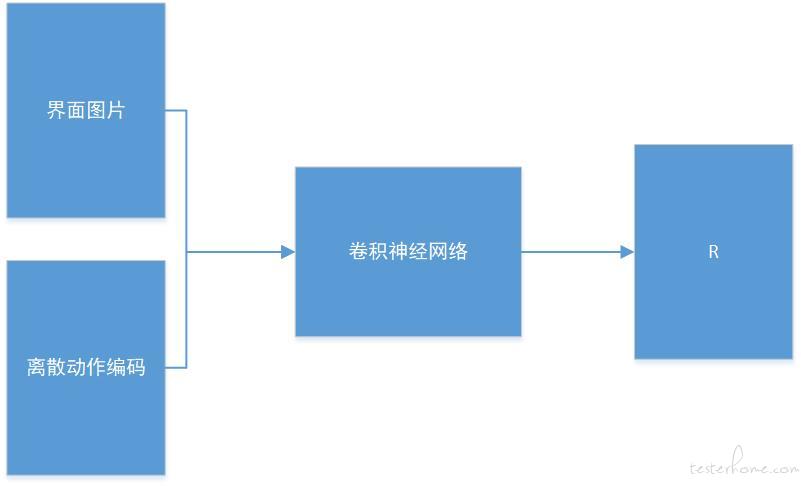
界面图片与离散动作编码可以是同维向量,在通道上进行叠加。经过卷积神经网络,输出预测的标量 R。
强化学习算法分为三类:
| 算法名称 | 模型 | 自举 |
|---|---|---|
| 蒙特卡洛 | 无 | 无 |
| 时序差分 | 无 | 有 |
| 动态规划 | 有 | 有 |
动态价值函数
三类方法均基于动作价值函数 Q,求解出动态价值函数,可能是表格型,也可能是函数型。本文列举的深度神经网络属于函数型,迭代求解神经网路参数 w。
由于收敛速度和计算复杂度等限制因素,通常我们选择使用时序差分以及变形方法,例如 n 步时序差分,或者结合资格迹的后向视图算法。
单步 Sarsa(λ) 方法:
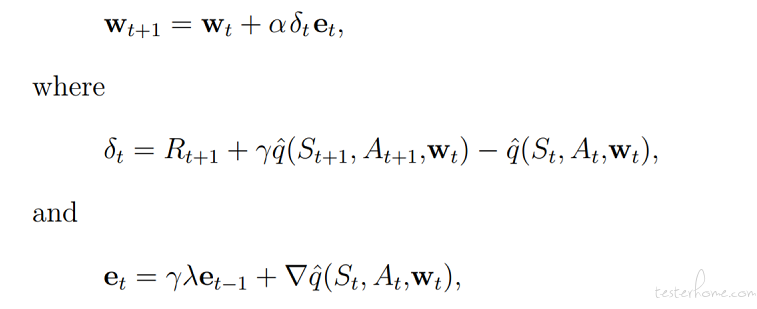
上式结合了资格迹,不断更新神经网络中的 w 参数,进行训练。
策略梯度函数
另一类方法是建立策略函数,动作价值函数作为求解策略函数的基准,也可以成为评价函数。例如 行动器 - 评判器 方法。
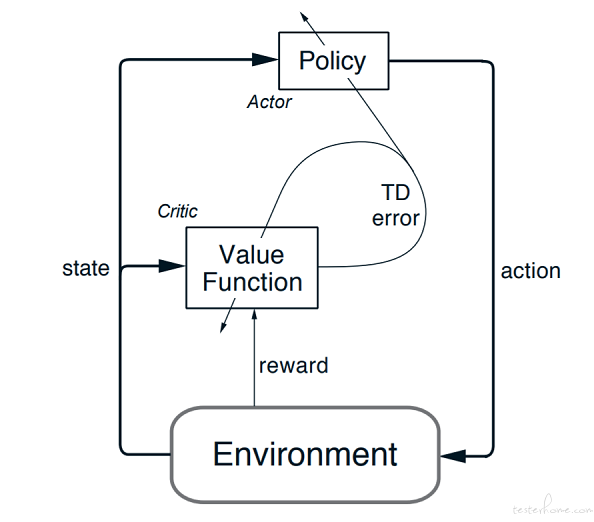
关于收敛性的争论:
有人会提到强化学习无法收敛的问题,本文建议采用 on-policy 方法,虽然是 TD 的半梯度方法,理论上仍可以收敛到蒙特卡洛方法收敛值的一定倍值上限内。
如何加快模型训练?
强化学习需要大量的交互数据才能收敛,因此往往在目标任务的模拟环境中进行训练,为了加快收敛速度,我们可以使用多个环境并发进行交互。
展望:
本文只是就强化学习解决 UI 遍历单一问题的讨论,与测试机器人相距甚远,但是开始就意味着可能成功,欢迎留言讨论。