前年的时候我们组的超哥曾经在 MTSC 大会上分享过我们做持续集成的经验, 我也曾经写过一个帖子介绍了我们大规模持续集成策略的内容:https://testerhome.com/topics/15058。
但是之前我们讲了策略,但没有告诉大家我们具体的实现, 所以这一次我会展开更多的实现细节, 针对这些技术我会写一些教程出来帮助大家理解如何来实现。 同时我是一个开源技术选型的拥护者,在项目中能用开源技术就绝对不自己造轮子。所以这个系列的特点也是技术选型都是开源项目,有耐心肯努力的同学一定可以复制到自己的项目中来。
其实我是一个理论知识匮乏的人,我到现在都没读完那本大名鼎鼎的《持续交付》, 当然这里我也不在这里跟大家说扯持续交付这个概念了, 因为对于我们这种 TO B 公司来说这是完全没有的事(3 个月发一个版本,这还持续交付个蛋~~)。所以对于持续集成的理解,我只有自己实践出来的经验而已。
先来说持续, 这两个字代表了不间断的对系统进行测试。 宗旨是研发同学每一次的代码提交都会经过相应的测试来验证。 做道尽早测试,尽早发现问题,尽早解决问题。 所以一般都会通过 jenkins 这种 CI 工具做触发式的 pipeline。 比如在 gitlab 上定义好 webhook,每当有 push event 或者 merge request event 的时候就会触发 pipeline 开始测试。 测试过程有单元测试也有集成测试。 这样我们可以就会对研发每一次提交的代码都有一定的信心, 如果提交的代码中有 bug 也能及早发现。
集成两个字非常重要同时也容易被忽略。 经验证明我们非常多的 bug 是发生在部署阶段以及模块与模块之间的交互上,也就是可能我们每一个模块跑的 UT 可能都没有任何问题,但是一旦产品部署起来,模块之间开始交互的时候,bug 就源源不断的出现了。尤其是在微服务架构下,几十上百的模块在系统中交互,那么集成测试的重要性就不言而喻了。 而在我们实践持续集成的时候也曾经针对集成测试发生过分歧。 众所周知 UT 运行速度很快,每当有代码提交时触发 UT 是没有任何争议的。 但是集成测试 (比如接口测试) 的运行速度让人担忧,如果研发频繁提交代码的话运行效率是一个问题。 但是集成阶段非常重要,我们的最终决定通过增加并发执行策略以及只跑 smoke 级别的简单测试来解这个问题。 甚至我们建议即便不跑集成测试,也要把子系统部署起来验证是可以运行的。我们的经验是如果不做这些可能最终提测的时候模块连部署都部署不起来。 所以最终我们的策略是。
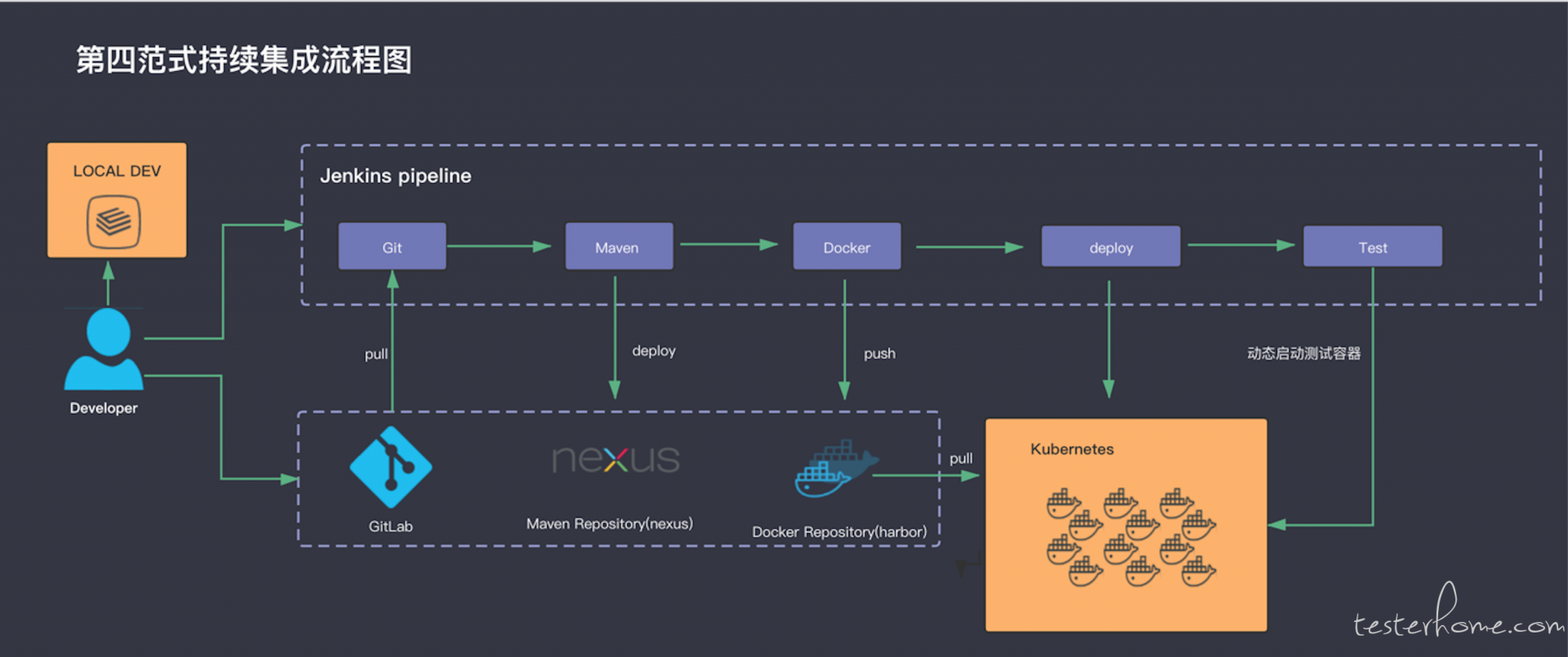
首先从全局角度考虑,我们需要这样一个流程。
从单个模块考虑,持续集成的流程是 -- 研发 push 代码开始触发 pipeline-> UT -> 打包,制作并推送镜像 -> 部署 -> 各种测试 -> 发送 report。 我们来看这里面涉及到的技术选型。
现在的 QA 面对的是大量的业务模块 (微服务的副作用),越来越长的持续集成流水线。 假设一个持续集成流水线平均要 5 个 job 来维护,就算只有 10 个模块那也有 50 个 job。 大量 job 的维护成本越来越高,这些通过 UI 配置的 job 从流水线的可视化,配置的复用等方面都相当的差。 所以当你面对一个拥有几十上百个服务组成的大型系统,还用以前的方式组织持续集成的流水线是几乎不可能的。想象一下维护几百上千的 jenkins job,而且由于配置复用做的很差,研发和部署稍微修改一下就要更新几十个 job 的恐怖场景吧。 所以选择 jenkins 2.0 提供的 pipeline 几乎是必然的。
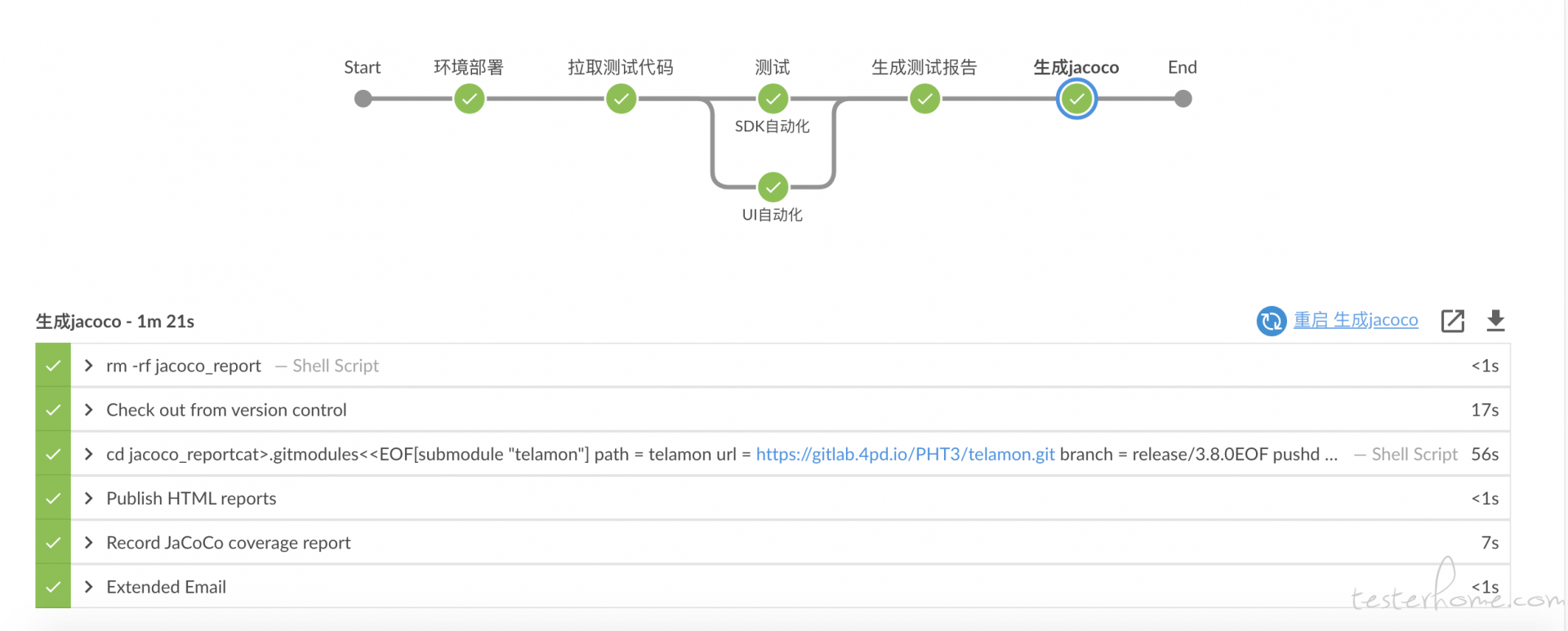
上面是我们一个模块做的集成测试的 pipeline。 在这个视图上点击 pipeline 中的每一个节点都能查看详细的运行状态和运行日志,可视化方便已经做的相当不错。 而 pipeline as code 的理念让我们把流水线的配置从 UI 上解放出来变成了用 groovy 脚本来配置的方式, 这个方式让我们可以一目了然的在一个脚本里看到整个 pipeline 的全貌。 并且 jenkins 提供全局共享库的方式让我们把公共的逻辑做成共享库分享给所有 pipeline 使用,种种设计解决了我们的维护噩梦。
到了这个时代我很难想象维护一个上百个模块的系统的时候,不使用容器编排技术将会是多么痛苦的事情。 2 年前我写《k8s 下的大规模持续集成与环境治理》的时候就提过,在一个大型系统中,持续集成最大的技术难题就是环境治理。 上百个模块每日不停的构建,集成,测试。 需要的是数十台机器的支持, 这里面资源的调度,环境的依赖,自动化为运维的要求等等都是非常恐怖的。 如果没有 k8s 这种容器编排框架来解决这些问题这个活简直没法干,那得需要铺多少人力来人肉维护。 在 17 年我们团队在测试环境中率先引用 k8s 的时候,我只用了一半的精力就维护了 60~70 套左右的环境。 当然当时产品还没有微服务架构, 所以总共部署的模块也就 600 个左右。 但半个人力维护这个数量级的测试环境,可见这套技术栈为我们提高了多少效率。
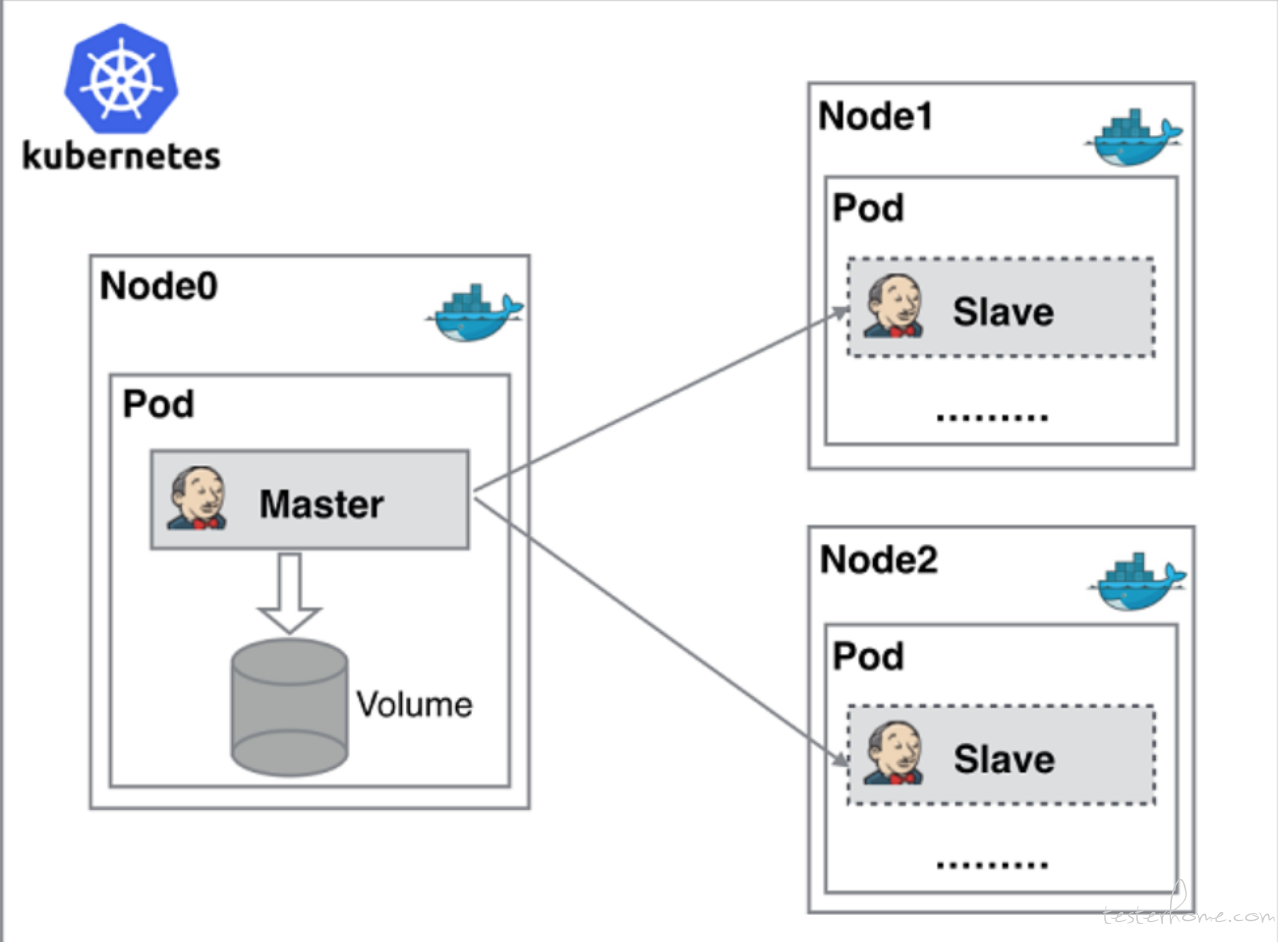
而抛开测试环境的治理, jenkins 与 k8s 的集成也同样为我们带来了额外的收获。 相比于把 jenkins master 节点部署在 k8s 中,利用 k8s 的高可用能力的实践, 我其实更喜欢的是 jenkins pipeline 对 k8s 的支持。 我们可以在 jenkins pipeline 中使用非常简单的指令就可以让 jenkins 动态的调用 k8s 接口创建 pod 并作为 jenkins 的 slave 运行流水线的能力。 这解决了我们对于负载均衡的痛点。 当有大量的构建任务的时候,你会发现单台机器的性能已经跟不上了, 再引入 k8s 之前,我们总会在编辑上遇到单台机器的性能瓶颈 -- 大量的编译 job 打满了 CPU,构建效率变的很差。 所以我们一定希望架构是可以横向扩展的,通过加机器来解决性能问题。 而 jenkins 与 k8s 集成后, 很好的解决了我们这个问题。
在我们团队里,其实不要求测试框架的统一的, 甚至连使用的语言也没有硬性的要求的。 大家都是喜欢用 java 就用 java,喜欢用 python 就用 python。 但是我们的 report 格式却是高度统一, 不管是用 java 的还是用 python 的,使用的都是 allure 框架来生成 report。 这样方便在 pipeline 中集成所有测试类型的测试报告。 比如一开始的 pipeline 的那个图里,我们是并发的执行了 sdk 的测试和 UI 自动化测试的。 SDK 是 python 语言的 sdk 所以必须使用 python 进行测试,而 UI 自动化选择的是 java 技术栈。 正因为这两个自动化测试项目使用的都是 allure 框架来生成 report。 在 pipeline 中,整个所有测试类型的 report 到一个视图中是比较重要的。 所以在这样的前提下,我们选择的测试框架是。 java: testng+allure(UI 自动化为 selendie,API 自动化为 rest-assured)。 python:pytest + allure
辅助测试的工具很多,这里列举几个常用的。
以上都是开源项目, 使用起来并不难。 但是在 pipeline 中自动化的使用它们是一个难点, 尤其是在容器化环境中。
第二篇: jenkins pipeline https://testerhome.com/articles/22240
第三篇:jenkins pipeline 与 k8s 集成 https://testerhome.com/articles/22280
第四篇:jenkins 与 k8s 集成的通信原理与配置记录 https://testerhome.com/articles/22302
第五篇:多分支 pipeline 与可视化 https://testerhome.com/articles/22489
开篇概述就讲这么多吧, 我不是一个特别能说概念的人, 所以接下来的文章会围绕着上面说的这些技术的使用展开~
