Airtest 3 分钟教会你选择合适的图像识别算法
注:我们的 Airtest 官方公众号(AirtestProject)会持续更新大家对于 Airtest 感兴趣的问题,欢迎有需要的同学关注并查看我们更多的内容。
如想向我们反馈关于 AirtestProject 想了解的问题,欢迎到公众号后台留言

1 个图像识别的例子
我们先从 1 个最简单的touch(Template())的语句来看看,Airtest 在进行图片识别的过程中,会用到什么识别算法:
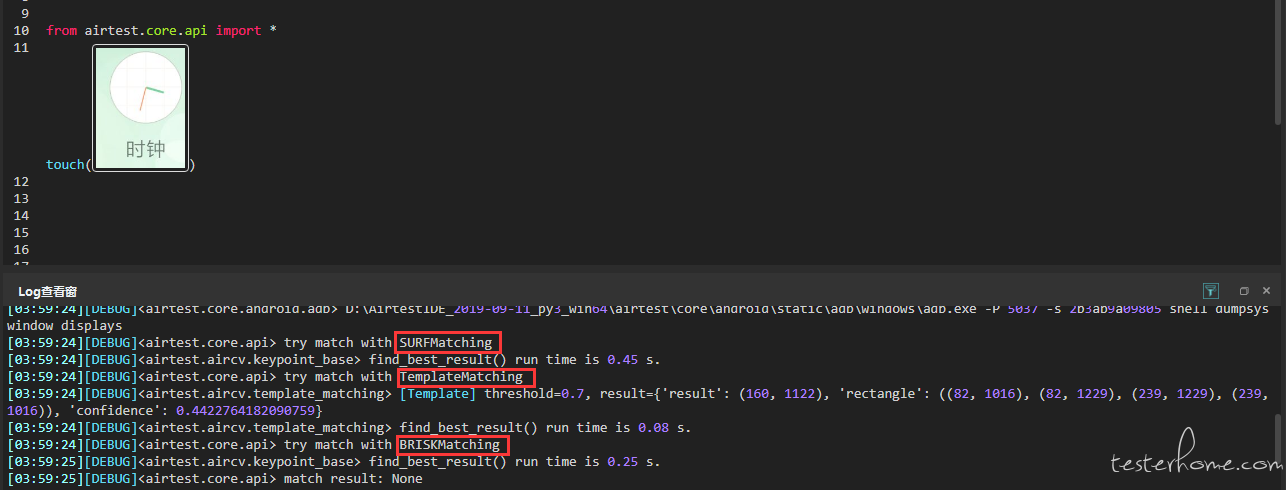
上图我们截取了执行 touch 语句的部分日志(截图不存在于当前设备画面中),可以看到,在识别图像的过程中,Airtest 尝试用了SURFMatching、TemplateMatching和BRISKMatching这几个算法去查找,并且还分别告诉了我们这几个算法的执行结果是什么。
值得注意的是,在TemplateMatching算法的执行结果里面,有一个'confidence': 0.4422764182090759,这个其实就是算法的可信度。
之前在 “截图识别成功率太低,究竟搞如何补救” 这篇推文中,我们介绍过如何合理调整阙值来提高图片识别成功率 ,那个阈值实际上是算法执行成功之后的可信度阈值(默认为 0.7),如果算法识别的可信度(也就是confidence)超过了我们设置的阈值,就会认为识别成功,否则认为失败。
Airtest 图像识别算法介绍
在 airtest 框架中集成了不同种类的图像识别算法。 其中包括模板匹配(也就是上文的TemplateMatching)、以及基于特征点的图像识别方法(包含了上文的SURFMatching和BRISKMatching)。这两种识别方法的特点和区别如下:
模板匹配
- 无法跨分辨率识别
- 一定有相对最佳的匹配结果
- 方法名:
"tpl"##### 特征点匹配 - 跨分辨率识别
- 不一定有匹配结果
- 方法名列表:
["kaze", "brisk", "akaze", "orb", "sift", "surf", "brief"]
在这里我们还需要解释一下:
1.无法跨分辨率识别,意思是一旦换一台不同分辨率的设备就可能识别失败;
2.一定有相对最佳的匹配结果,即是不管怎么说也会给你找一个结果出来,虽然可能差别很大。比如上文例子中,我们使用了当前设备不存在的截图让程序去查找,屏幕上根本没有结果,TemplateMatching算法也找出了一个可信度为 0.4 的结果。
算法小结
- 模板匹配算法的优点是速度很快,如果分辨率不会改变的话,不妨选择它作为首选算法
- 在分辨率可能会发生改变的情况下,我们会用特征点匹配的办法来找图,这样跨平台的适应能力会更高,脚本容易适配不同型号的手机
特征点匹配各算法的性能对比
针对单张图片,不同方法的性能对比
method_list = ["kaze", "brisk", "akaze", "orb", "sift", "surf", "brief"]
# 针对一张图片,绘制该张图片的CPU和内存使用情况.截屏[2907, 1403] 截图[1079, 804]
search_file, screen_file = "sample\\high_dpi\\tpl1551940579340.png", "sample\\high_dpi\\tpl1551944272194.png"
dir_path, file_name = "result", "high_dpi.json"
test_and_profile_and_plot(search_file, screen_file, dir_path, file_name, method_list)
注:测试代码详见 airtest 源码目录下的 airtest/benchmark/benchmark.py
-
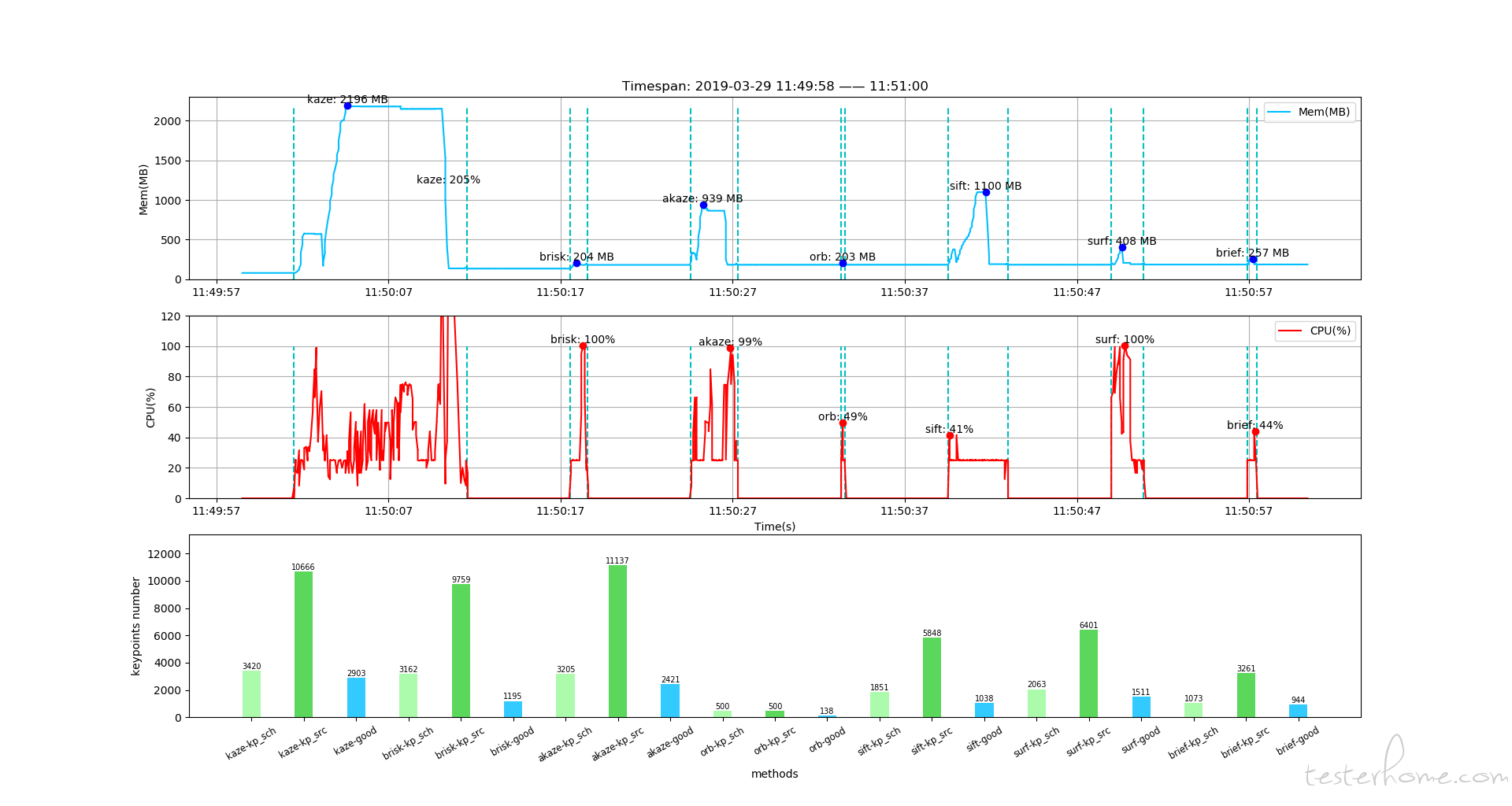
性能解析:
- 内存:
- 最上方图为内存曲线
- 内存占用:kaze > sift > akaze > surf > brief > brisk > orb
- CPU:
- 中间图为 CPU 曲线
- CPU 占用:kaze > surf > akaze > brisk > sift > brief > orb
- 时间:
- 横轴为时间轴,且程序运行日志中有 run tume 输出
- 运行时长:kaze > sift > akaze > surf > brisk > brief > orb
- 特征点对数量:
- 最下方图为特征点数量图
- kp_sch 为小图的特征点数量
- kp_src 为大图的特征点数量
- good 为匹配成功的特征点对数量
- 点对数量:kaze > akaze > surf > brisk > sift > brief > orb
##### 针对多张图片的不同方法的性能对比
method_list = ["kaze", "brisk", "akaze", "orb", "sift", "surf", "brief"] # 测试多张图片,写入性能测试数据 test_and_profile_all_images(method_list) # 对比绘制多张图片的结果 plot_profiled_all_images_table(method_list)
- 内存:
-
性能解析:
- 最大内存:
- 最上方图为内存曲线,横轴为不同的图片名
- 最大内存:kaze > sift > akaze > surf > brief > brisk > orb
- 最大 CPU:
- 中间图为 CPU 曲线
- 最大 CPU:kaze > surf > akaze > brisk > sift > brief > orb
- 识别效果:
- sift > surf > kaze > akaze > brisk > brief > orb
##### 特征点匹配算法小结
针对单张图片:
kave 识别的效果最好,但同时占用内存和 CPU 也最多;
相对来说 surf 和 brisk 的效果不错,且占用内存和 CPU 也处于中等水平;
orb 虽然占用内存和 CPU 最低,但是它的效果也最差;
- sift > surf > kaze > akaze > brisk > brief > orb
##### 特征点匹配算法小结
针对单张图片:
- 最大内存:
所以做单图识别的时候,如果对识别精确度要求很高,且不在乎对内存和 CPU 的使用率时,可以选择 kave;如果对精确度要求没那么高时,选择像 surf 和 brisk 这些算法,就不会占用过多的内存和 CPU。
针对多张图片:
sift 的识别效果最好,它占用的 CPU 也比较少,但占用内存较多;
surf 的识别效果也很好,它占用的内存也比较少,但占用的 CPU 很高;
akave 和 brisk 的效果还行,且占用内存和 CPU 也不是很多;
orb 依旧是占用 CPU 和内存最少,但效果最差的那一个;
所以做多图识别,对精确度要求高且不在意内存占用率的,可以选择 sift;而对精确度要求高且在意内存占用率的,可以选择 surf;对于精确度要求不是很高的,选用 akave 和 brisk 不会占用过多的内存和 CPU。
拓展
对性能对比感兴趣的同学可以到我们开源项目 airtest 文件夹里的 benchmark 目录下,用benchmark.py跑一下自己的例子来看看。
Airtest 脚本图像匹配算法的设定方式:
Airtest 默认设置的算法是CVSTRATEGY = ["surf", "tpl", "brisk"],每次查找图片的时候,airtest 就会按照这个设置好的算法顺序去执行,直到找出一个符合设定阈值的识别结果,或者是一直循环查找,直到超时。
当我们执行了 1 条 touch 语句(截图不存在于当前设备画面中),查找图片时执行算法的日志如下:
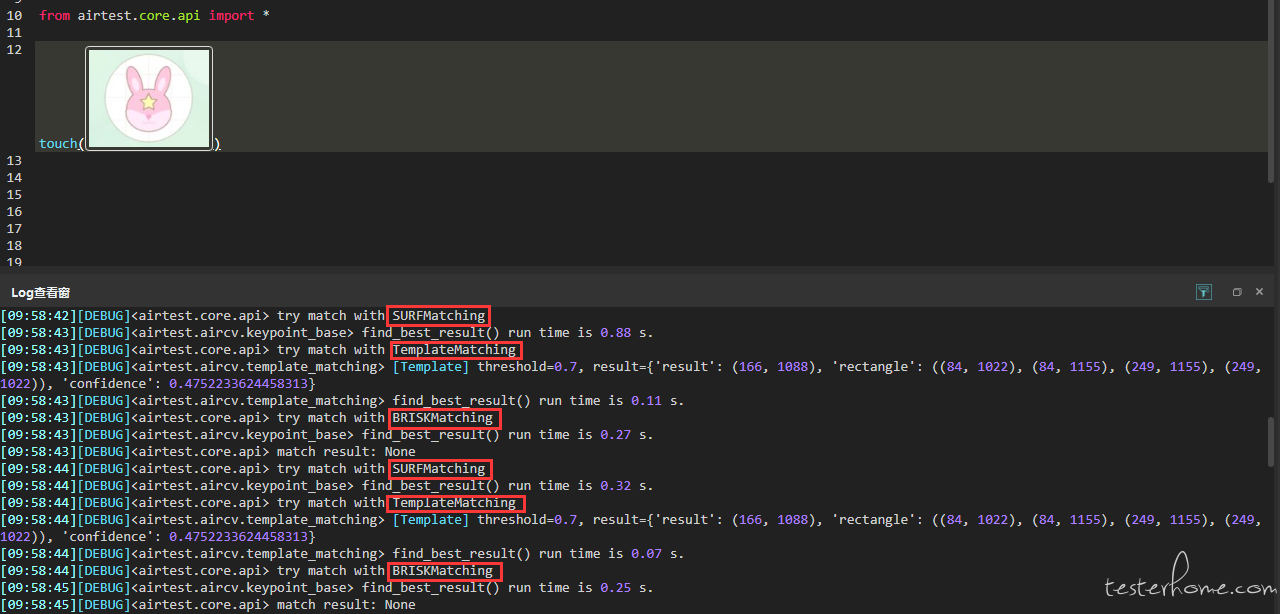
可以看到,airtest 按照默认设置的算法顺序去执行,从surf到tpl再到brisk,且因为当前设备不存在该截图,它就一直循环查找,直到超时。
而当要找的截图存在于当前设备画面时,日志记录如下:
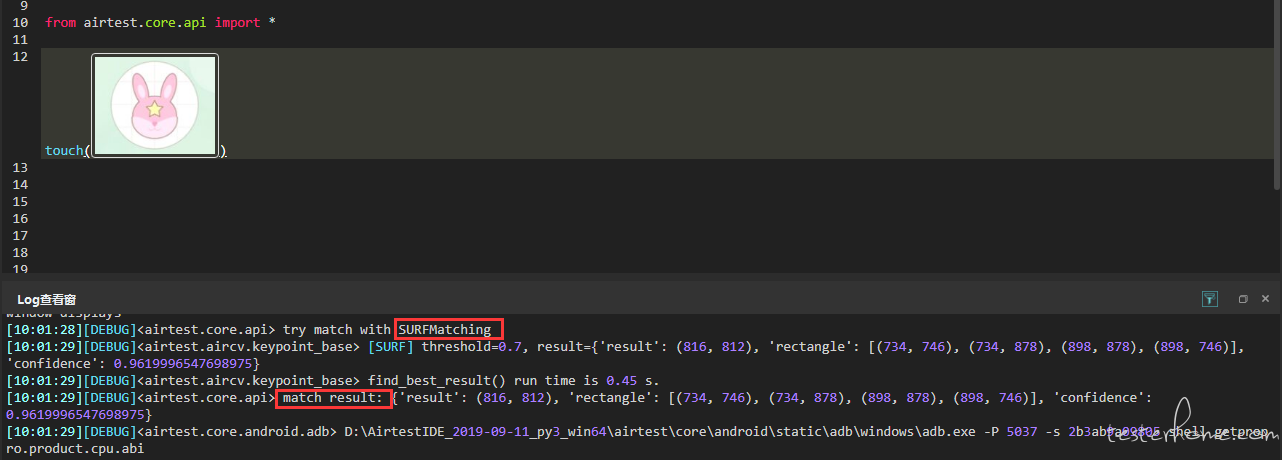
airtest 按照默认的算法顺序,先执行了surf,然后成功匹配了一个符合设定阙值的结果,程序就认为识别成功了。
那么,当我们想要改变这个算法顺序或者自定义我们想要使用的图像识别算法时该如何做呢?举个例子:
如果我们使用的都是同样分辨率的设备,并且想要匹配速度快一些,我们可以将tpl调整到最前面。设置如下:
from airtest.core.settings import Settings as ST
ST.CVSTRATEGY = ["tpl", "sift","brisk"]
最后,如果大家对 Airtest 有疑问、BUG、建议,请到https://github.com/AirtestProject/AirtestIDE/issues 发布 issue,我们会有专人解答。同时,我们还提供了官方 QQ 群给大家沟通交流,目前 1 群已满,欢迎大家加入 2 群:
