一 编码关系
计算机中所有数据的存储和运算都以二进制表示。字符,如大小写字母、数字、符号,在计算机中存储也要使用二进制,具体用哪些二进制数字表示哪个字符,我们需要事先约定,于是形成了所谓的编码。为了方便互相通信,相关组织会制定一些统一的编码,于是出现 ASCII 编码、GB2312 等。
Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。历史上存在 2 个独立的组织,制定了 2 种通用编码标准,分别是 UCS 和 Unicode,前者有 UCS-2、UCS-4,两者后来互相兼容。
虽 unicode 能统一不同国家的字符,解决乱码问题,但若内容全是英文 unicode 比 ASCII 需要多一倍的存储空间,同时如果传输需要多一倍的传输。当传输文件比较小的时候,内存资源和网络带宽尚能承受,当文件传输达到上 TB 的时候,如果 “硬” 传,则需要消耗的资源就不可小觑了。为了解决这个问题,一种可变长的编码 “utf-8” 应运而生,把英文变成 1 个字节,汉字 3 个字节,特别生僻的变成 4-6 个字节,如果传输大量的英文,utf8 的作用就很明显。
计算机系统通用的字符编码工作方式,即在计算机内存中,统一使用 Unicode,当需要保存到硬盘或传输时,就转换为 UTF-8,关系如图:
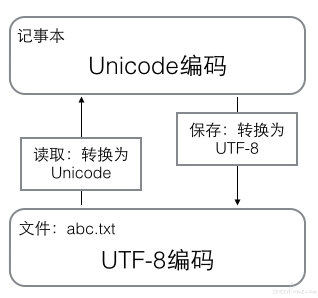
二、编码规则
ASCII:
编码规则:
1.使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符
2.标准 ASCII 码也叫基础 ASCII 码,使用 7 位二进制数(剩下的 1 位二进制为 0)来表示所有的大小写字母、数字、标点符号,以及在美式英语中使用的特殊控制字符,最高位用作奇偶校验位
3.后 128 个称为扩展 ASCII 码
出现问题:
1.不同国家使用扩展 ASCII 码来表示本地的语言,导致多语言的冲突
2.汉字多达 10 万左右,ASCII 码位数不够,出现多种编码标准,如 GB2312、GBK、GB18030
UCS-4:
编码规则:
1.用 4 个字节编码。根据最高位为 0 的最高字节分成 27=128 个组(group)。每个 group 再根据次高字节分为 256 个平面(plane)。每个平面根据第 3 个字节分为 256 行(row),每行有 256 个码(cell)。group0 的平面 0 被称作 BMP(Basic Multilingual Plane)。每个平面有 216=65536 个码位
其他相关:
1.如果 UCS-4 的前两个字节为全零,那么将 UCS-4 的 BMP 去掉前面的两个零字节就得到了 UCS-2
2.Unicode,计划使用了 17 个平面,一共有 17×65536=1114112 个码位
Unicode:
编码规则:
1.分为 17 组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有 65536 个码位,共 1114112 个。目前只用了少数平面。
2.UTF-8、UTF-16、UTF-32 都是将数字转换到程序数据的编码方案
UTF-8:
编码规则:
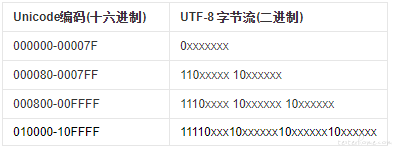
注:UTF-8 是 Unicode 的实现方式之一,以字节为单位对 Unicode 进行编码
引用网址:
https://baike.baidu.com/item/ASCII/309296?fr=aladdin
https://baike.baidu.com/item/Unicode/750500?fr=aladdin
https://blog.csdn.net/jsfzdd/article/details/98879985
https://www.jianshu.com/p/2a8fad876120