新手区 听说 Go 协程很厉害,灌水写了一个压测小程序;路过的客官帮忙指点一下哈
写的时候,用了 2 种方式;并且都测试了一下
预设值
type IterationConfig struct {
DurationTime int //迭代 持续时间:单位min
QPS int //QPS:单位 Query/s
Concurrency int //并发数
ThinkTime int //思考时间,迭代间隔时间:单位s
}
非协程 方式,4 个都需要设置;可设置多次;存于 Map 中进行便利
协程 方式,不用设置并发数;
非协程的方式
PS.省去了一些不必要的代码
思路:
假设 1s 内 10 个请求,那每一个请求的间隔多少 ms
间隔时间:(1s =1000ms)/QPS实现 100 个并发 达到(qps=500/s)
代码中变量意义说明:
times :(DurationTime) / (ThinkTime+1) 结果向上取整(这 1s 在请求)
thinkTimeThrottle : time.Tick 限制器,简单理解就是 sleep 掉设置的(思考时间);才继续往下执行(这里设置迭代间隔)
throttle:sleep 掉 同一批次 1s 内的请求 间隔时间
for i := 0; i < times; i++ {
t.Log(1,time.Now())
for j := 0; j < concurrency; j++ {
requestCount++
//do request
t.Log(2,time.Now())
<-throttle
}
<-thinkTimeThrottle
t.Log(3,time.Now())
}
测试:
预设参数:
iter := IterationConfig{
DurationTime: 1
QPS: 10,
Concurrency: 10,
ThinkTime: 20,
}
一句话描述: 10 个请求(达到 10QPS),每批次间隔 20s 持续 1 分钟
测试结果:
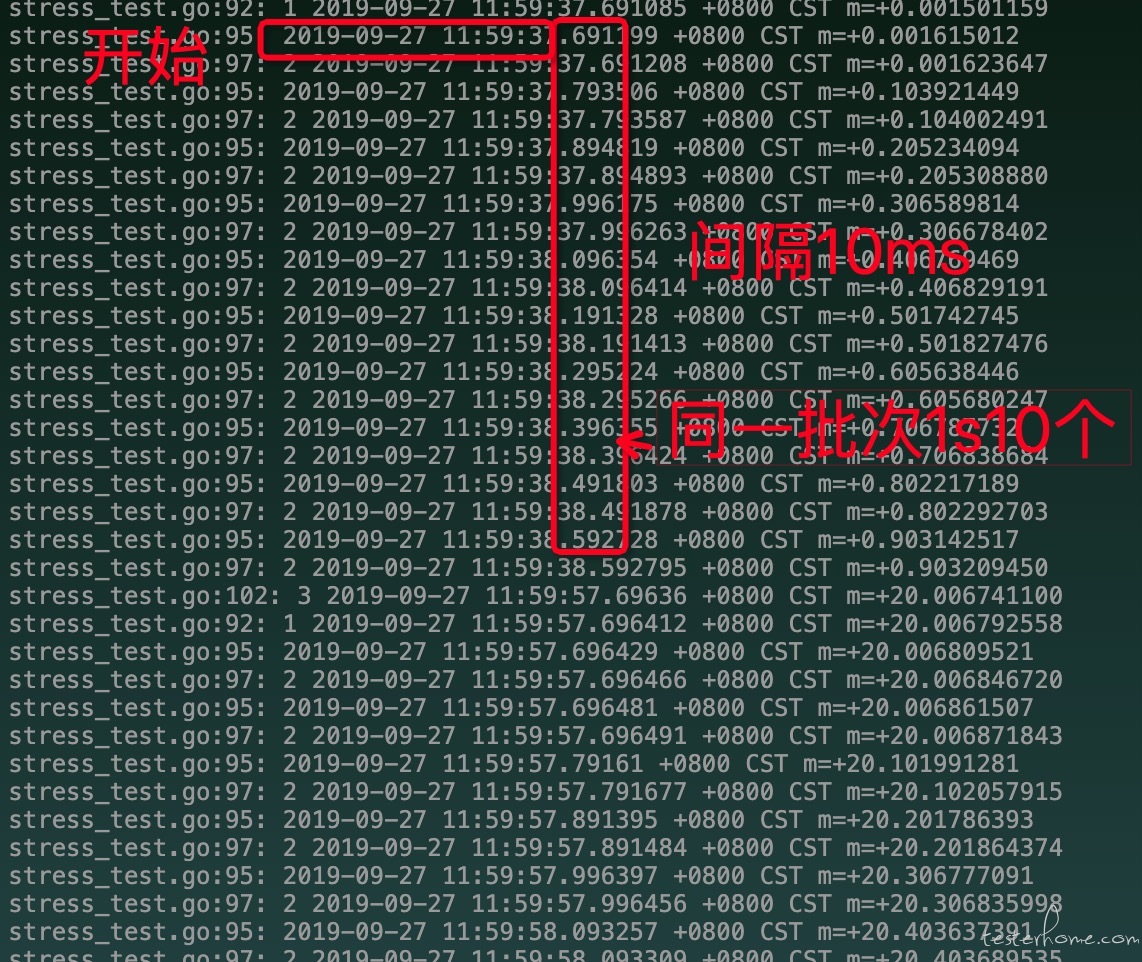
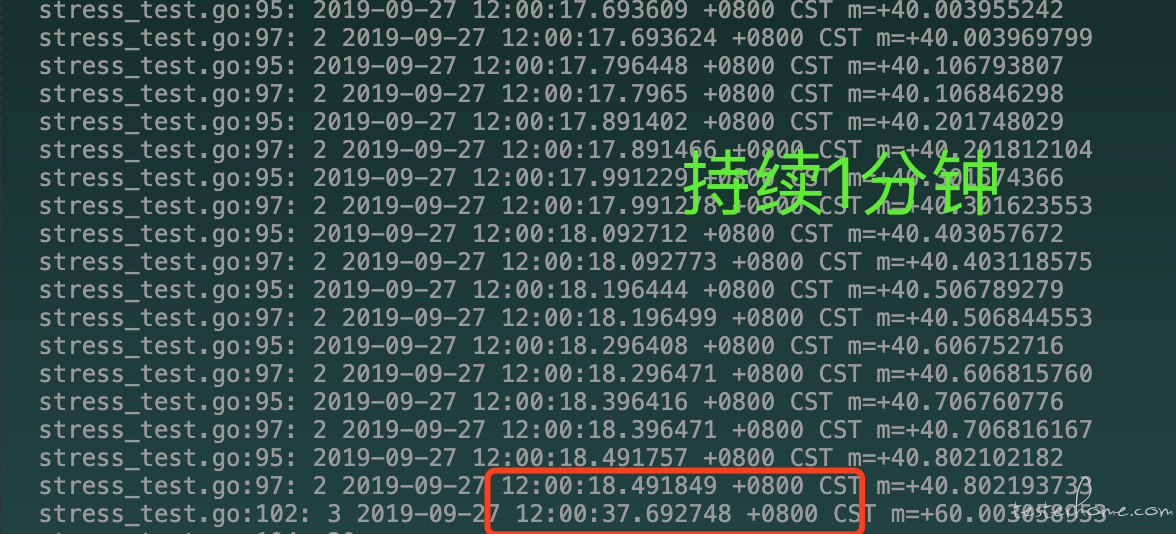
优点:可以实现,指定数量的请求,完成指定的 qps 请求,
缺点: 虽然没有测试,但是单线程 1s 内完成的数量猜测可能会有限(所以控制的 qps)受限
协程的方式
思路:
- 协程,需要多少 qps 开多少协程?
代码中变量意义说明:
times :(DurationTime) / (ThinkTime+1) 结果向上取整(这 1s 在请求)
thinkTimeThrottle : time.Tick 限制器,简单理解就是 sleep 掉设置的(思考时间);才继续往下执行(这里设置迭代间隔)
for i := 0; i < times; i++ {
t.Log(time.Now())
for j := 0; j < item["QPS"].(int); j++ {
go func() {
t.Log(1, time.Now())
defer func() { // 延迟函数,在当前这个func执行 到return前执行
mut.Unlock() //defer 函数中锁释放
}()
//do request
// doRequest()
mut.Lock()
count++
retChan <- count
}()
}
<-ThinkTimeThrottle //思考时间限流器
t.Log(2, time.Now())
}
测试:
预设参数:
对比参数少了 Concurrency(并发数)
iter := IterationConfig{
DurationTime: 1
QPS: 10,
ThinkTime: 20,
}
一句话描述: 10 个请求(达到 10QPS),每批次间隔 20s 持续 1 分钟
测试结果:
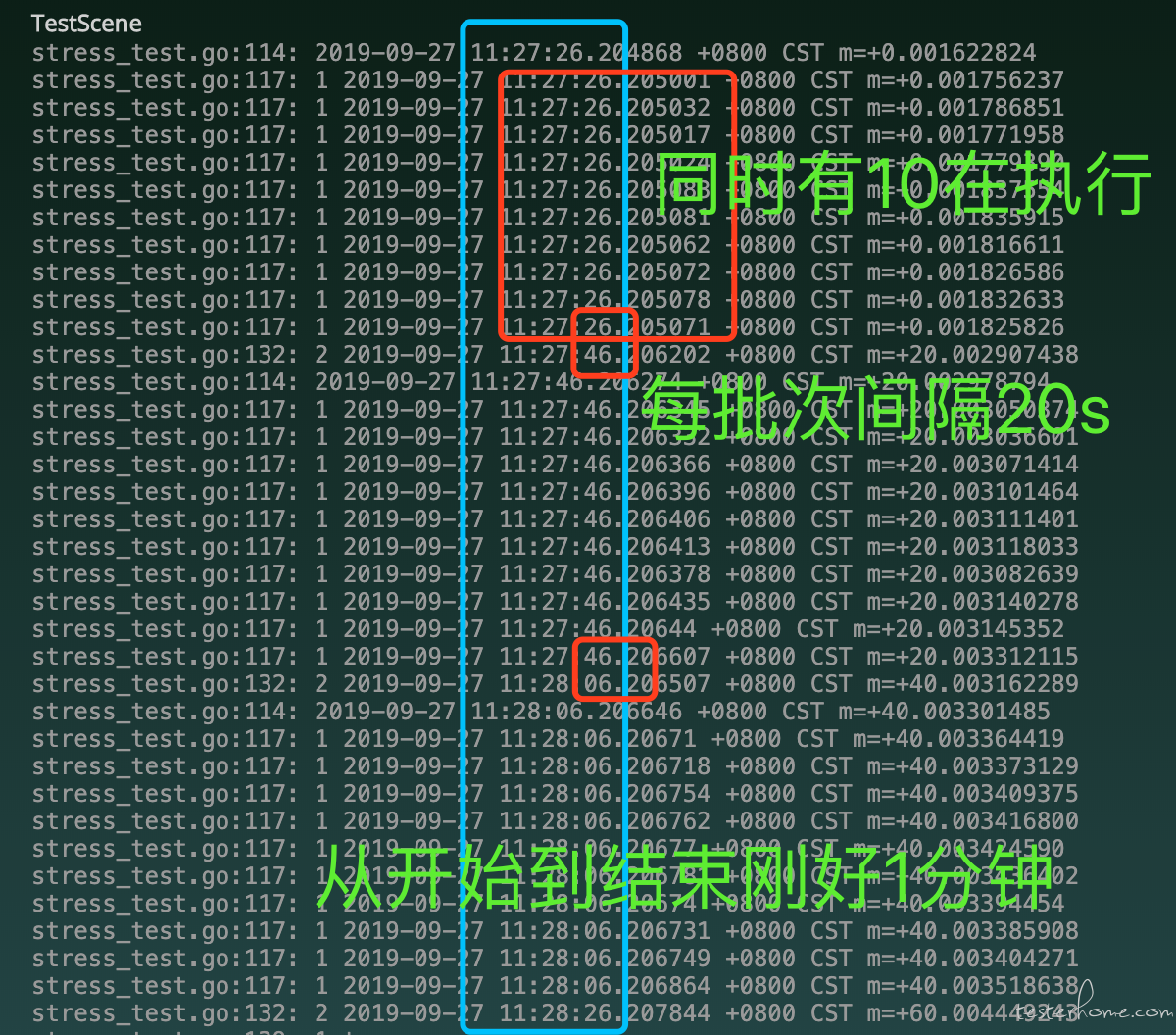
优点:应该可以利用协程实现大的 qps 请求
缺点: 由于了解协程机制还是太浅,所有这个缺点还待后面的使用中进行总结
总结
2 种方式感觉都有优缺点~看场景吧;功能还未完善~目前只拿到了每个请求的相应时间;
总的平均响应时间还没做处理 ,及图标啥的都没搞📈;继续努力
