AI测试 也许这有你想知道的人工智能 (AI) 测试 -- 第二篇 (修改版)
概述
回过头看觉得之前写的 “也许这有你想知道的人工智能 (AI) 测试 -- 第二篇” 内容有点少,这是 补充版本
说明:内容都为自己学习,以及项目思考而来,个人认知有限,所说内容不保证专业性及全部正确性。如果有造成误导,还请谅解。欢迎交流。
个人原创,请勿未经同意,复制粘贴。
测试执行
如果执行测试?
可以准备好测试数据,然后批量运行数据后,人工来对比测试结果和预期结果。再计算评价指标。
最好就是测试脚本实现了批量运行、测试结果保存、测试结果和预期结果的比对,并计算评价指标,输出评价指标等功能。这样对于测试执行就是点一下运行就可以了。
当然还可以加上一些其他方便的内容。比如执行完成发送钉钉消息,因为批量执行可能要一段时间 。执行完成把评价指标出图出来,更直观显示。贴到测试报告中也好看。
也可以开发一个平台,记录测试结果,并展示评价指标。这样项目组人员或其他人员可以随时在平台上了解算法测试结果。
当然上述是比较理想的情况,实际测试,可能有些功能通过代码比较难实现或者实现成本高。还是会有些人工的操作。
测试工具
会用到什么测试工具吗
pycharm python excel
测试用例
人工智能 (AI) 测试 或者说是 算法测试,个人认为主要做的有三件事。
- 收集测试数据 思考需要什么要的测试数据,测试数据的标注
- 跑测试数据 编写测试脚本批量运行
- 查看数据结果 统计正确和错误的个数,查看错误的数据中是否有共同特征等
而编写测试用例,主要是围绕数据来进行。为更好的设计测试用例,首先需要了解一些项目的情况。这些东西如果在《需求文档》中就有描述是最好的。如果没有需要找算法工程师沟通了解。
测试用例的思考点
- 项目落地实际使用场景,根据场景思考真实的数据情况,倒推进行测试数据收集
- 模型的训练数据有多少,训练数据的分布情况,训练数据的标注是否准确
- 算法的实现方式
- 选择模型评价指标
- 评价指标的上线要求
- 项目的流程,数据流
- 模型的输入和输出
- 算法外的业务逻辑
测试结果
测试人员做测试工作,其实大部分测试的核心内容就是:测试结果和预期结果对比。
如 APP 的账号登录注册功能,写测试用例也是操作步骤,预期结果,实际结果等。
只有预先知道这样的操作,产生的预期结果是啥,才能知道这是不是 Bug。
AI(人工智能)测试也是一样。不同的是不像 APP,一条用例执行结果和预期不一致就会记录为一个 Bug。算法测试不太关注单个结果的一致性,关注整体。有点类似于计算得出整个测试用例的通过率。
不管是自然语音处理语音语义识别还是计算机视觉的图像处理,都需要有一些标注数据,也就是知道预期结果。才能开展做测试。推荐系统有些不一样,你不会知道具体会推荐出哪一条,可能只会知道大概类别范围,所以无法给出标注,预期结果。(这块以后有时间再写)
AI(人工智能)测试是计算测试集运行的测试结果和测试集的标注结果,得出评价指标来衡量算法的泛化能力。
算法运行得到算法结果之后,就需要做结果数据分析了。曾经我公司和某公司使用,提供了 http 接口给对方调用算法,对方调用来测试算法。后来把测试结果发给我们看时,发现对方测试人员,简单的把 正确数 除以 总数,得到准确率。并没有关注数据结果。
有以下问题:
1,测试数据不规范,全都是单一化、类似的数据,数据分布不合理。
2,测试数据总量不足。不过这没办法,只有这么多。
3,有的结果返回两类,假设一类为正样本,另一类为负样本,测试结果中负样本一个都未被计入到正确数,即对的都是正样本 ,此时负样本缺失的情况,最终准确率结果已经不具备参考价值。
4,部分数据标注不准确,认知有些差异。
重点需要关注预期结果和实际结果不一致的数据,是怎么样的。再次检查标注是否错误。查看错误的数据的分布,是否有共同的特征。如果有的话,数据允许的情况下,可以再找些这样的数据单独来进行验证,是否带有此特征的数据都会识别错误。
测试问题
测试过程会遇到什么问题
实际项目中不仅是有算法相关代码还会有工程代码。如模型加载,入参的处理,异常判断,数据库相关,日志相关等等。所以项目测试,还会有工程代码功能的测试。
举例一些常见的:
1,有的依赖包在不同环境版本不一致,导致结果不一样。
2,科学计算错误
3,工程代码问题
4,模型效果差
科学计算即数值计算,是指应用计算机处理科学研究和工程技术中所遇到的数学计算问题。比如图像处理、机器学习、深度学习等很多领域都会用到科学计算。有很多语言和库都提供了科学计算工具。这其中,Numpy 以其简洁易用的语法和强大的性能成为佼佼者,并以此为基础形成了庞大的技术栈(下图所示)。
一张图片输入,卷积神经网络顺序通常为:输入 - 卷积层 - 池化层 - 全连接层 - 输出。深度学习预测的过程就有大量的数值计算。可能就会碰到一些边界数值情况,导致计算出错。

我看不懂公式,贴过来提升下层次。也方便别人理解下真是大量复杂的数值计算。
自动化测试
可以自动化测试吗
开发语言是 python,需要商用给到外部调用,都用封装好为 http 调用。如百度开放平台。
所以自动化测试,就是接口自动化。
测试报告
测试结果最终通过测试报告展现,一份详见的测试报告,可以让别人清晰的了解测试什么,怎么测试的,测试结果是怎么样。
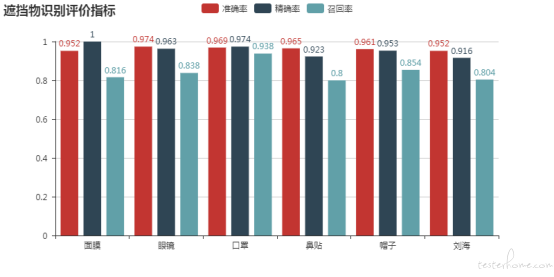
最后附一个用 pyecharts 画的图。