通用技术 图数据库综述与 Nebula 在图数据库设计的实践
Nebula Graph:一个开源的分布式图数据库。作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,还能够实现服务高可用且保障数据安全性。
第三期 nMeetup( nMeetup 全称:Nebula Graph Meetup,为由开源的分布式图数据库 Nebula Graph 发起的面向图数据库爱好者的线下沙龙) 活动于2019年8月3日在上海陆家嘴的汇丰银行大楼举办,我司 CEO -- Sherman 在活动中发表《 Nebula Graph Internals 》主题演讲 。本篇文章是根据此次演讲所整理出的技术干货,全文阅读需要 30 分钟,我们一起打开图数据库的知识大门吧~

大家好,非常感谢大家今天能够来我们这个线下沙龙,天气很热,刚又下了暴雨,说明大家对图数据库的热情要比夏天温度要高。今天我们准备了几个 topic,一个就是介绍一下我们产品——Nebula 的一些设计思路,今天不讲介绍性东西,主要讲 Nebula 内部的思考——为什么会去做 Nebula,怎么样去做,以及为什么会采取这样的设计思路。

这个就是 Nebula。先从 overview 介绍图数据库到底是个什么东西,然后讲我们对图数据库的一些思考。最后具体介绍两个模块, Nebula 的 Query Service 和 Storage Service。后面两部分会稍微偏技术一些,在这个过程当中如果大家遇到什么问题,欢迎随时提出。
图数据库是什么

图领域的 OLAP & OLTP 场景
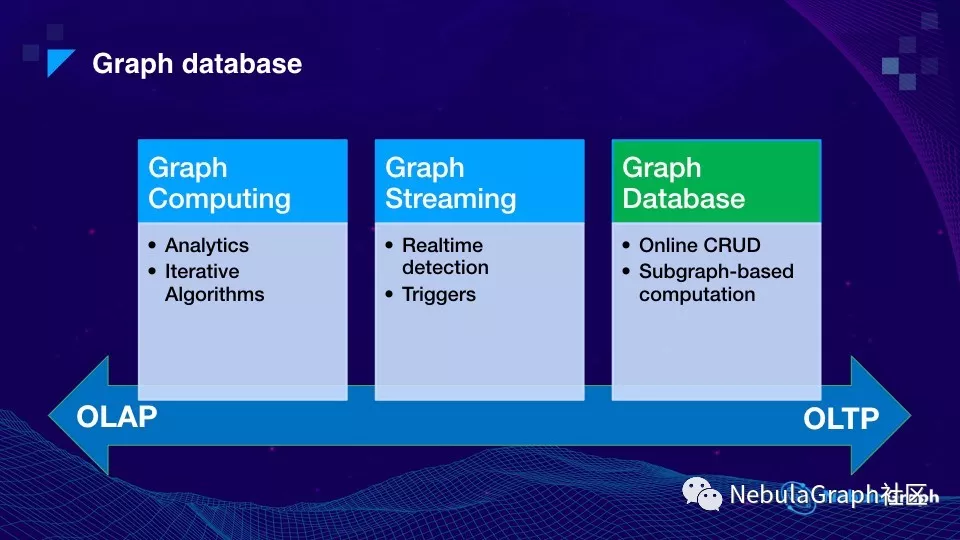
对于图计算或者图数据库本身我们是这么理解的,它跟传统数据库很类似,也分为 OLAP 和 OLTP 两个方向。
上图中下面这根轴表示数据对查询时效性的要求,OLAP 更偏向于做离线分析,OLTP 更偏向于线上处理。我们认为图领域也可以这么划分。
首先在 OLAP 这个领域,我们称为图计算框架,这些图计算框架的主要目的,是做分析。基于图的结构的分析——这里图代指一个关系网络。整体上这个分析比较类似于传统数据库的 OLAP。但一个主要特点就是基于图结构的迭代算法,这个在传统数据库上是没有的。最典型的算法是谷歌 PageRank,通过一些不断的迭代计算,来算网页的相关度,还有非常常见的 LPA 算法,使用的也非常多。
如果我们继续沿着这个线向右边延伸,可以看到一个叫做 Graph Stream 的领域,这个领域相当于图的基础计算跟流式计算相结合的产物。大家知道关系网络并不是单单一个静态结构,而是会在业务中不断地发生变化:可能是图的结构,或者图上的属性发生变化,当图结构和属性发生变化时,我们希望去做一些计算,这里的计算可能是一种触发的计算或判断——例如在变化过程当中是不是动态地在图上形成一个闭环,或者动态地判断图上是否形成一个隔离子图等等。Trigger(触发)的话,一般是通过事件来驱动这类计算。对时效性的响应当然是越高越好,但往往响应时间一般是在秒级左右。
那么再往轴上右边这个方向看,是线上的在线响应的系统。大家知道这类系统的特点是对延时要求非常高。可以想象如果在线上做交易的时候,在这个交易瞬间,需要到图上去拿一些信息,当然不希望要花费秒级。一般响应时间都是在十几、二十毫秒这样一个范围。可以看到最右边的场景和要求跟左边的是完全不一样的,是一种典型的 OLTP 场景。在这种场景里面,通常是对子图的计算或者遍历——这个和左边对全图做计算是完全不一样的:比如说从几个点出发,得到周边 3、4 度的邻居构成一个子图,再基于这个子图进行计算,根据计算的结果再继续做一些图遍历。所以我们把这种场景称为图数据库。我们现在主要研发内容主要面向 OLTP 这类场景。所以说今天的一些想法和讲的内容,都是跟这块相关。
图数据库及其他数据库的关注度增长趋势
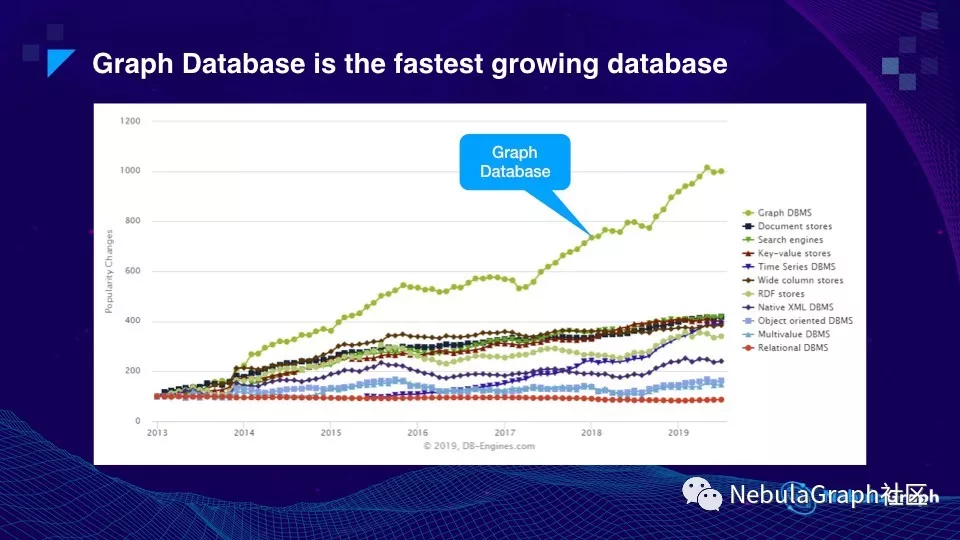
这张图是从 DB-Engines.com 上截下来的,反应了从 2013 年到 2019 年 7 月,所有类型数据库的趋势。这个趋势是怎么计算出来的?DB-Engines 通过到各大网站上去爬取内容,查看所有用户,包括开发人员和业务人员的情况下统计某类数据库被提及的次数将其转化为分数,分数越高,表示这种类型的数据库的关注度越高。所以说这是一个关注度的趋势。
最底下这条红线是关系型数据库,在关系型数据库之上有各类数据库,比如 Key-Value 型、文档型、RDF 等。最上面的绿线就是图数据库。
可以看到在过去六年多的时间里,图数据库的整个趋势,或者说它的影响力大概增长了十倍。
图数据存储计算什么数据
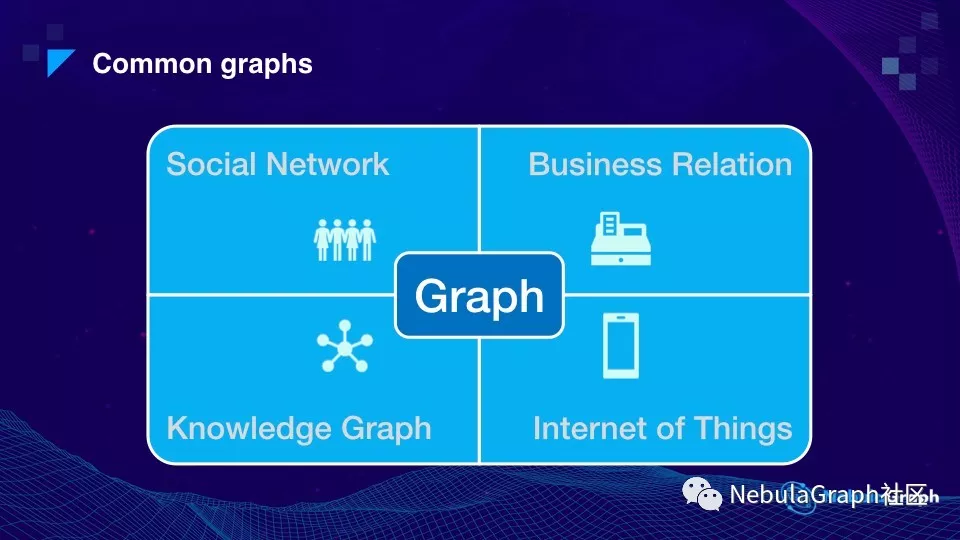
今天我们谈数据库肯定离不开数据,因为数据库只是一个载体,一个存储和计算的载体,它里面的数据到底是什么呢?就是我们平时说的图。这里列出了几个目前为止比较常见的多对多的关系数据。
图数据的常见多对多关系数据库场景
第一个 Social Network(社交网路),比如说微信或者 Facebook 好友关系等等。这个网络有几十亿个用户,几千亿到几万亿的连接关系。第二个 Business Relation,商业的关系,常见的有两种网络:
- 金融与资金关系网络:一种比如说在支付网络里面,账户和账户之间的支付关系或者转账关系,这个是比较典型的金融与资金关系网络;
- 公司关系:在 business 里面,比如说公司控股关系,法人关系等等,它也是一个非常庞大的网络。基于工商总局数据,有许多公司耕耘在这一领域。这个网络的节点规模也有亿到十亿的级别,大概几百亿条边,如果算上交易转账数据那就非常庞大了。
第三个是知识图谱,也是最近比较热的一个领域。在各个垂直领域会有不同的知识点,且知识点之间有相关性。部分垂直领域知识的网络至少有几百亿条关系,比如银行、公安还有医学领域。
最后就是这几年热门的 IoT(Internet of Things)领域,随着近年智能设备的增长,预计以后 IoT 设备数量会远超过人口数量,现在我们每个人身边佩带的智能设备已不止一个,比如说智能手机、智能手表,它们之间组成一个庞大的关系网络,虽然具体应用有待后续开发,但这个领域在未来会有很大的应用空间。
图数据库的应用场景
刚才提到的是常见的关系网络,这里是我们思考的一些应用场景。
第一个应用场景是基于社交关系网络的社交推荐,比如:拼多多的商品推荐,抖音的视频推荐,头条的内容推荐,都可以基于已有的好友关系来推荐。
第二个就是风控领域,风控其实是银行保险业的核心话题。传统的风控是基于规则——基于规则的风控手段,相对已经比较成熟了,一般是拿直接的交易对手来做规则判断。但现在风控有个新趋势,就是通过关联关系做拓展,比如交易对手等相关的周边账号,通过这些关系来判断这笔交易或者转账的风险。从规则向基于关联关系的风控演进,这个趋势比较明显。
关于知识图谱这一块,和 Google 比较有关,谷歌在 2003,2004 年时候,其实已经在慢慢把它的 search engine,从反向索引转向转到了知识图谱。如果只有倒排表,比如说要查 “特朗普” 今年几岁,这个是很难做到的,因为已有的信息是他的生日是哪年。
这几年机器学习和 AI 领域发展非常快,大家知道就机器学习或者模型训练范畴来说,平时用大量数据去训练模型,其实归根结底是对大量数据汇总或者说统计性的结果。最近一两年,大家发现光有统计性结果不够,数据和数据之间的关系也应体现在模型里,所以开始将基于图的数据关系加入到模型训练,这个就是学术界非常流行的 Graph Embedding,把图的结构引入到模型训练里面。
在健康和医疗领域,患者的过往病史、服药史、医生的处方还存在纸质文档的情况,一些医疗类公司通过语音和图像将文档数字化,再用 NLP 把关键信息提取出来。根据关键信息,比如:血压、用药等等构造一棵大的决策树或者医疗知识图谱。这块也是比较新的应用。
区块链的应用其实比较容易理解,区块链本身虽然说是链,但有很多分支结构,当分支交织后也就构成一个网络。举个简单例子,A 某想通过比特币洗钱,常用方法是通过多个账号,几次转账后,资金通过数字货币形成一个闭环,而这个方法是可以通过图进行洗钱防范。
最后一块是公共安全领域,比如,某些犯罪是团伙作案,那么追踪团伙中某个人的行为轨迹,比如:交通工具、酒店等等就可标识出整个团伙的特征。某个摄像头和某个嫌疑人在某个时间构建起来关联关系,下一个时刻,另外一个摄像头和另外一个嫌疑人也建立了关联。这个图不是静态的,它是时序的。
这些就是一些已经看到的图的应用领域。
图数据库面临的挑战

回到图数据库,做图数据库到底有哪些挑战。和所有的 OLTP 系统一样:
第一个挑战就是低延时。我们不希望一次查询,要几秒钟甚至几分钟才能产生结果。比如说风控场景,在线转账的时候,我要判断这笔交易是否有风险,可能整个时间只有一百毫秒,留给风控判断的时间只有几十毫秒。不可能转账完才发现对方账户已经被标黑了,或者这笔交易其实是在套 null 现。
第二个挑战是高吞吐,现在热门的 APP,比如抖音或者头条,日常访问的并发量是非常高的,峰值可能几十万 QPS,DB 要能抗的住。
第三个挑战是数据量激增,数据量的增加速度快于硬件特别是硬盘的增长速度,这个给 DB 带来了很大的挑战。大家可能用过一些单机版的图数据库,刚开始用觉得不错,能满足需求。但一两年后,发现数据量增加太快,单机版已经完全满足不了需求,这时总不能把业务流控吧。
我们遇到过一个图 case,有超过一千亿个节点,一万亿条边,点和边上都还有属性,整个图的数据量超过上百 T。可以预计下,未来几年数据量的增长速度会远远快于摩尔定理的速度,所以单机版数据库肯定搞不定业务需求,这对图数据库开发是一个很大的挑战。
第四个挑战是分析的复杂性,当然这里分析指的是 OLTP 层面的。因为图数据库还比较新,大家刚开始使用的时候会比较简单,例如只做一些 K 度拓展。但是随着使用者的理解越来越深,就会提出更多越来越复杂的需求。例如在图遍历过程中过滤、统计、排序、循环等等,再根据这些计算结果继续图遍历。所以说业务需求越来越复杂。这就要求图数据库提供的功能越来越多。
最后一个挑战是关于数据一致性——当然还有很多其他挑战,这里没有全部罗列。前几年大家对于图数据库的使用方法更像使用二级索引,把较大的数据放在另外的存储组件,比如 HBase 将关联关系放在图数据库里,将图数据库只作为图结构索引来加速。但像刚才说的,业务越来越复杂,对响应时间要求越来越高,原先的架构除了不方便,性能上也有很大挑战。比如,需要对属性做过滤时,要从 HBase 读取出太多数据,各种序列化、过滤操作都很慢。这样就产生了新需求——将这些数据直接存储在图数据库里,自然 ACID 的需求也都有了。
图数据库模型:原生图数据库 vs 多模数据库

说完技术挑战,还有个概念我想特别澄清下。大家如果网上搜图数据库,可能有 20 个自称图数据库的产品。我认为这些产品可以分成两类,一种就是原生的,还有一类是多模的。
对于图原生的产品,在设计时考虑了图数据的特性,存储、计算引擎都是基于图的特点做了特别设计和优化。
而对于多模的产品,就有很多,比如说 ArangoDB 或者 Orientdb,还有一些云厂商的服务。它们的底层是一个表或文档型数据库,在上层增加图的服务。对于这类多模数据库,图服务层所做的操作,比如:遍历、写入,最终将被映射到下面的存储层,成为一系列表和文档的操作。所以它最大的问题是整个系统并不是为了图这种多对多的结构特点设计,一旦数据量或者并发量增大之后,问题就比较明显。我们最近碰到一个比较典型的 case,客户使用多模 DB,在数据量很小时还比较方便,但当数据量大到一定程度,做二跳三跳查询时 touch 的数据非常多,而多模 DB 底层是关系型数据库,所有关系最终要映射到关系型数据库的 join 操作,做三四层的 join ,性能会非常的差。
图数据库——Nebula Graph:一个开源的分布式图数据库

上面是我们对行业的一些思考。这里是我们在做的图数据库,它是一个开源的分布式的项目——Nebula Graph。
存储设计
这里我想说下我们在设计 Nebula 时候的一些思考,为什么会这样设计?
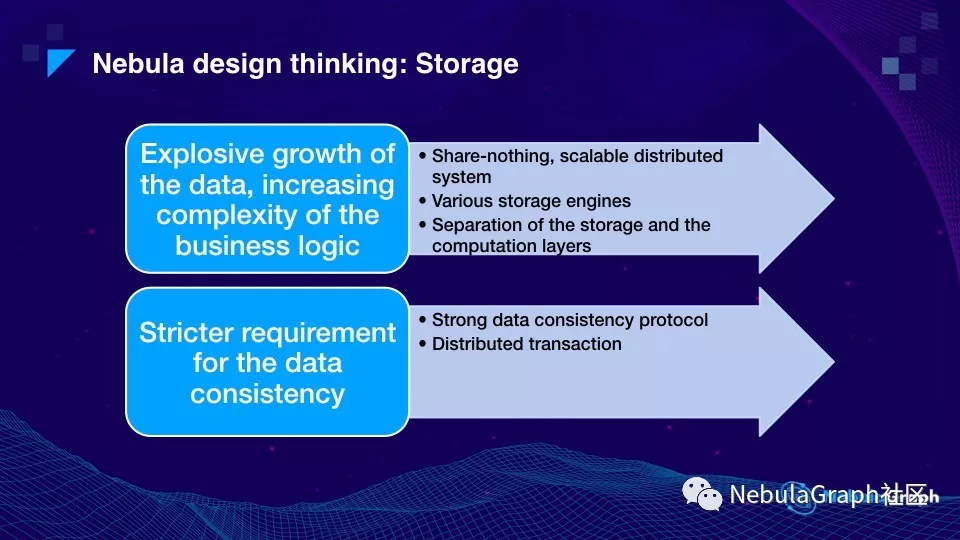
刚刚说到过技术挑战中数据量迅速膨胀,业务逻辑越发复杂,像这样的开发挑战,Nebula 是如何解决的。
Nebula 在设计存储时,采用 share-nothing 的分布式架构,本质上存储节点间没有数据共享,也就是整个分布式结构无中心节点。这样的好处在于,第一,容易做水平拓展;第二,即使部分机器 Crash,通过数据强一致性—— Raft 协议能保证整个系统的可用性,不会丢失数据。
因为业务会越发复杂,所以 Nebula 支持多种存储引擎。有的业务数据量不大但对查询的实时性要求高,Nebula 支持纯内存式的存储引擎;数据量大且查询并发量也大的情况下,Nebula 支持使用内存加 SSD 模式。当然 Nebula 也支持第三方存储引擎,比如,HBase,考虑到这样使用存在的主要问题是性能不佳,我们建议用在一些对性能要求不是很高的场景。
第三个设计就是把存储和计算这两层分开了——也就是 “存储计算分离”。这样的设计有几个明显的好处。所有数据库在计算层通常都是无状态的,CPU intensive,当 CPU 的计算力不够的时候,容易弹性扩容、缩容,而对于存储层而言,涉及到数据的搬迁情况要复杂些。所以当存储计算分离后,计算层和存储层可以根据各自的情况弹性调整。
至于数据强一致这个挑战,有主要分两个方面,一个是关于数据的强一致,就是多数派协议——Nebula 现在使用的 Raft 协议,通过多副本的方式来实现强一致。另外个是分布式的事物务 Transaction,它来保证要向多台机器写入一批相互依赖数据的正确性,这个和 NewSQL 里面的概念是非常类似的。
计算设计

刚刚是我们对存储引擎的一些思考,这里是我们对计算引擎的思考。
前面提到的一个技术挑战是低延时、高并发,Nebula 整个的核心代码都是 C++ 写的,这样保证了执行效率。其次,做了很多并行和异步执行的优化。第三个是计算下推。在分布式系统里面,硬件上网络对整体性能的影响最大,所以数据搬迁是一个很低效的动作。有些开源图数据库产品,比如 JanusGraph,它的存储层在 HBase,上面有个单独的计算层,当计算层需要数据的时候,会到 HBase 里面拉回大量的数据,再做过滤和计算。举个例子,1 万条数据里面最终过滤出 100 条,那相当于 99% 的网络传输都浪费了。所以 Nebula 的设计方案是移动计算,而不是数据,计算下推到存储层,像前面这个例子,直接在存储层做完过滤再回传计算层,这样可以有 100 倍的加速。
第二,如果大家接触过图数据库领域的一些产品,会发现图数据库这领域,相比关系型数据库有个很大的问题——没有通用的标准。关系型领域的标准在差不多 30 年前已制定,但图数据库这个领域各家产品的语言相差很大。那么针对这个问题 Nebula 是怎么解决?第一尽量贴近 SQL,哪怕你没有学过 Nebula 语言,你也能猜出语句的作用。因此 Nebula 的查询语言和 SQL 很像,为描述性语言,而不是命令式语言。第二个是过去几年我们做图数据库领域的经验积累,就是 No-embedding(无嵌套)。SQL 是允许 embedding 的,但嵌套有个问题——当查询语句过长时,语句难读,因为 SQL 语句需从内向外读,语序正好跟人的理解相反,因为人比较习惯从前往后来理解。所以 Nebula 把嵌套语句写成从前往后的方式,作为替代,提供 Shell 管道这样的方式,即前面一条命令的输出作为后一条命令的输入。这样写出来的语句比较容易理解,写了一个上百行的 query 你就会发现从前往后读比从中间开始读要易于理解。
第三,和传统数据库相比,图的计算不光是 CRUD,更重要是基于图结构的算法,加上新的图算法不停地涌现,Nebula 怎么 keep up?
- 将部分主要算法 build in 到查询引擎里;
- 通过支持 UDF(user-defined function,用户定义函数),用户可把业务相关逻辑写成程序或者函数,避免写重复 query;
- 查询语言的编程能力:Nebula 的查询语言 nGQL 是 Programmable。
架构设计
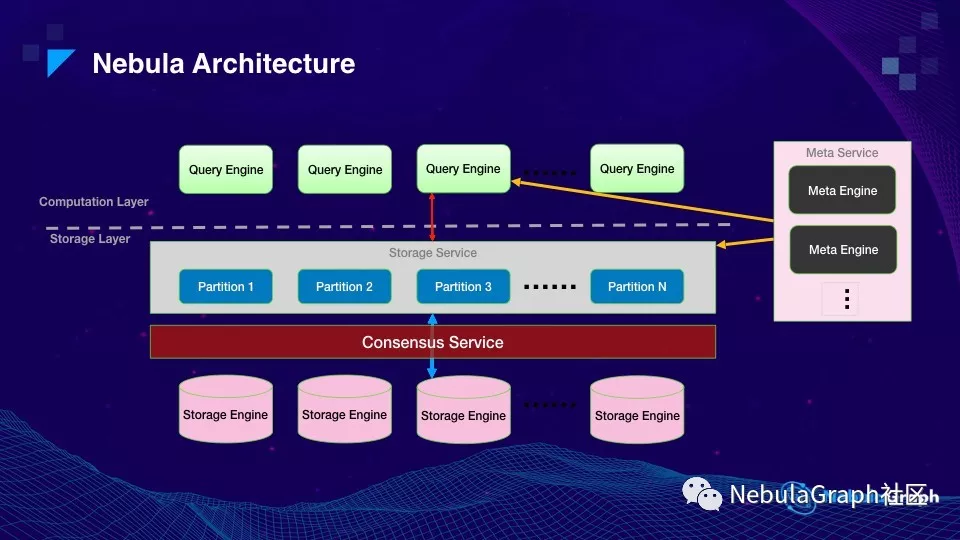
Overview 这一章节的最后内容是 Nebula 的架构。上图虚线把存储和计算一分为二,上面是整个计算层,每一台机器或者虚拟机是一个节点,它是无状态的,相互之间没有任何通讯,所以计算层要做扩缩容非常容易。
下面是存储层,有数据存储所以是有状态的。存储层还可以细分,第一层是 Storage Service,从计算层传来的请求带有图语义信息,比如:邻居点、取 property,Storage Service 的作用是把图语义变成了 key-value 语义交给下层的 KV-store,在 Storage Service 和 KV-store 之间是一层分布式 Raft 协议。
图的右边是 Meta Service,这个模块有点类似 HDFS 的 NameNode,主要提供两个功能,一个是各种元信息,比如 schema,还有一个是指挥存储扩容。大家都知道存储扩容是个非常复杂的过程,在不影响在线业务地情况下一步步增加机器,数据也要一点点搬迁,这个时候就需要有个中心指挥。另外 Meta Service 本身也是通过 Raft 来保证高可用的。
图数据库 Nebula 的查询引擎设计

上面就是 Nebula 的总体介绍,下面这个部分介绍查询引擎的设计细节。
查询语言——nGQL

先来介绍下 Nebula 的查询语言 nGQL。nGQL 的子查询有三种组合方式:管道、分号和变量。
nGQL 支持实时的增删改、图遍历、属性遍历,也支持对属性先做 index 再遍历。此外,你还可以对图上的路径写个正则表达式,查找所有满足这个条件的图路径。
查询引擎架构
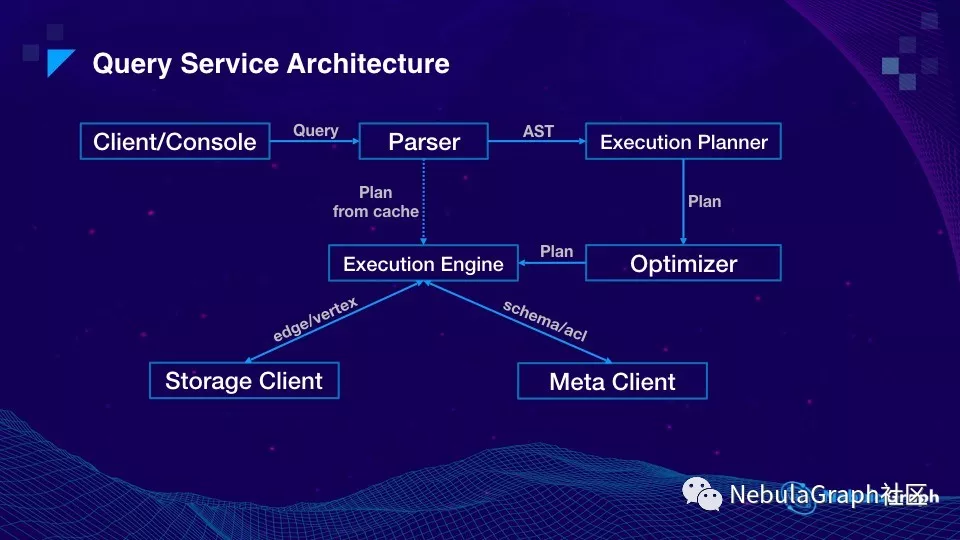
再来介绍下查询引擎的架构,从查询引擎的架构图上来看,和数据库类似:从客户端发起一个请求 (statement),然后 Parser 做词法分析,之后把分析结果传给执行计划(Execution Planner),执行计划会基于这个语句的特点,交给优化器 (Optimizer) 进行优化,最后将结果交给执行引擎 (Execution Engine) 去执行。执行引擎会通过 MetaService 获取点和边的 schema,通过存储引擎层获取点和边的数据。
执行计划案例
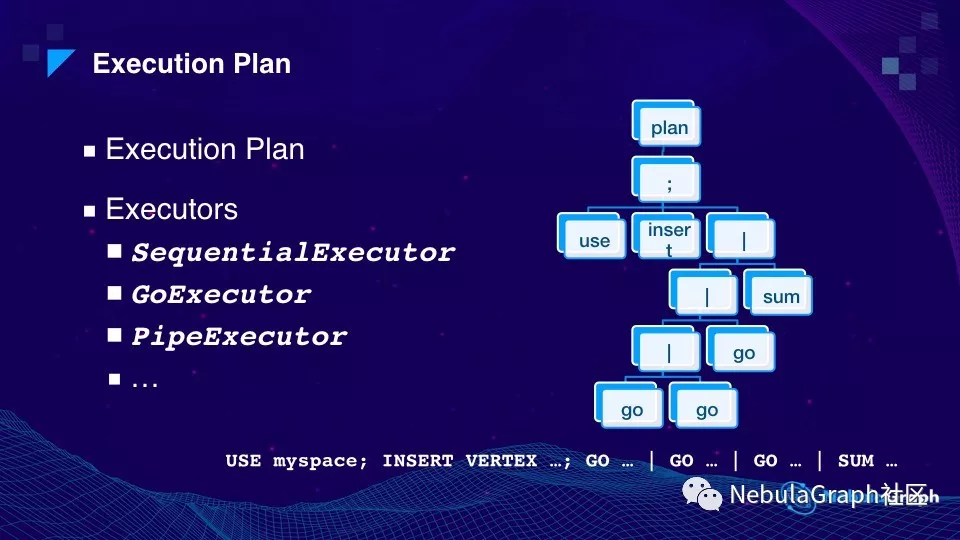
这里有个小例子展示了执行计划,下方就是一条语句。首先 use myspace,这里的 space 和数据库里的 database 是一个概念,每个 space 是一个物理隔离的空间,可用来区分敏感数据和非敏感数据,或者说做多租户的支持。分号后面是下一语句—— INSERT VERTEX 插入节点, GO 是网络拓展, | 为 Nebula 的管道用法,这条语句的意思是将第一条 Go 的结果传给第二条 Go,然后再传给第三条,即往外走三步遍历,最后把整个结果做求和运算。这是一种常见的写法,Nebula 还支持其他写法。
这样语句的执行计划就会变成上图右边的语法执行树。这里每个节点,都叫做 Executor(语法执行者),语句中的分号对应执行 SequentialExecutor ,Go 对应执行 GoExecutor ,"|"(管道)对应执行 PipeExecutor 。
执行优化

这一页介绍执行优化。在顺序执行过程中优化器会判断当前语句是否存在相互依赖关系,在没有相互依赖时,执行引擎可并行执行从而加速整个执行过程,降低执行延时。流水线优化,跟处理器 CPU 的流水线优化类似。上面 “GO … | GO … | GO … ” 例子中,表面上第一个 GO 执行完毕后再把结果发给第二个 GO 执行,但实际执行时,第一个 GO 部分结果出来之后,就可以先传给下一个 GO,不需要等全部结果拿到之后再传给下一步,这对提升时延效果明显。当然不是所有情况都能这样优化,里面有很多工作要做。前面已提过计算下沉的优化,即过滤的操作尽量放在存储层,节省通过网络传输的数据量。JIT 优化在数据库里已经比较流行,把一条 query 变成代码直接去执行,这样执行效率会更高。
图数据库 Nebula 的存储引擎设计

刚才介绍了查询引擎,下面介绍存储引擎。
存储架构
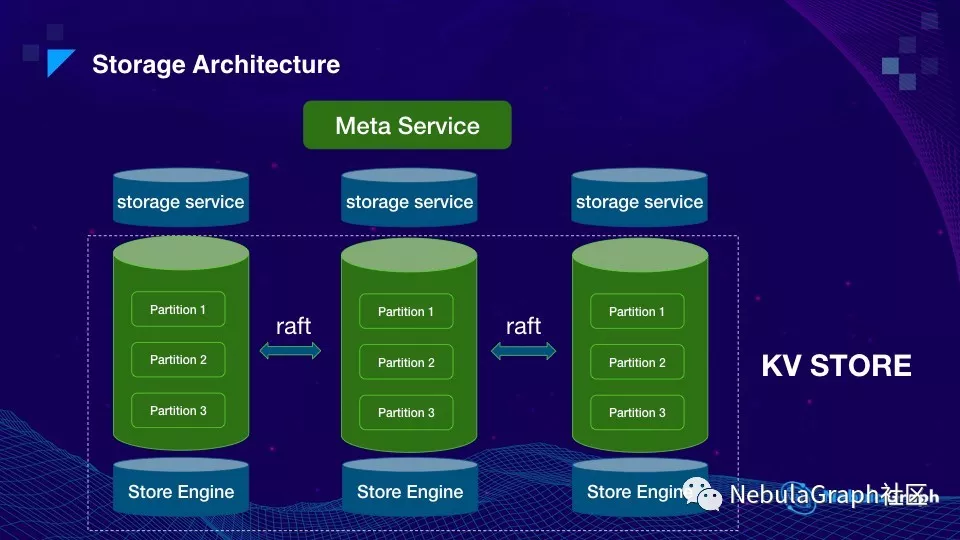
这张图其实是前面整体架构图的下面部分。纵向可理解为一台机器,每台机器最上面是 Storage service,绿色的桶是数据存储,数据被切分成很多个分片 partition,3 台机器上同 id 的 partition 组成一个 group,每个 group 内用 Raft 协议实现多副本一致性。Partition 的数据最后落在 Store Engine 上,Nebula 默认 Store Engine 是 RocksDB。这里再提一下,partition 是个逻辑概念,partition 数量多少不会额外增加内存,所以一般把 partition 数量设置成远大于机器的数量。
Schema

这一页是 schema,讲的是怎么把图数据变成 KV 存储。这里面的第一个概念是标签(Tag),“标签” 表示的是点(Vertex)的类型,一个点可以有多种 “标签” 或者说 “类型”。另一个概念是边类型(Edge Type),一条边需要用起点 ID,终点 ID,边类型和 Ranking 来唯一标识。前面几个字段比较好理解,Ranking 这个字段是留给客户表示额外信息,比如:转账时间。这里补充下说明下 Nebula 顶点 Vertex、标签 Tag、边 Edge、边类型 Edge Type 的关系。
Vertex 是一个顶点,用一个 64 位的 id 来标识,一个 Vertex 可以被打上多个 Tag(标签),每个 Tag 定义了一组属性,举个例子,我们可以有 Person 和 Developer 这两个 Tag,Person 这个 Tag 里定义了姓名、电话、住址等等信息,Developer 这个 Tag 里可能定义了熟悉的编程语言、工作年限、GitHub 账号等等信息。一个 Vertex 可以被打上 Person 这个 Tag,这就表示这个 Vertex 代表了一个 Person,同时也包含了 Person 里的属性。另一个 Vertex 可能被同时打上了 Person 和 Developer 这两个 Tag,那就表示这个 Vertex 不仅是一个 Person,还是一个 Developer。
Vertex 和 Vertex 之间可以用 Edge 相连,每一条 Edge 都会有类型,比如:好友关系。每个 Edge Type 可定义一组属性。Edge 一般用来表示一种关系,或者一个动作。比如,Peraon A 给 Person B 转了一笔钱,那 A 和 B 之间就会有一条 Transfer 类型的边,Transfer 这个边类型(Edge Type)可以定义一组属性,比如转账金额,转账时间等等。任何两个 Vertex 之间可以有多种类型的边,也可以有多条同种类型的边,比如:转账,两个 Person 间可存在多笔转账,那每笔转账就是一条边。
上面例子中,点和边都带有属性,即多组。Nebula 是一个强 schema 系统,属性的每个字段名和对应的类型需要在构图时先定义,和数据库中的 alter table 类似 Nebula 也支持你在后续操作中进行 Schema 更改。Schema 中还有常见的 TTL(Time To Live),指定特定数据的生命周期,数据时效到后这条数据会被自动清理。
数据分片和 Key 的设计

刚才有提到过分片(Partition)和键(Key)的设计,这里再详细解释一下。
数据分片 Partition 或者有些系统叫 Shard,它的 ID 是怎么得到?非常简单,根据点的 ID 做 Hash,然后取模 partition 数量,就得到了 PartitionID。
Vertex 的 Key 是由 PartID + VID + TagID 三元组构成的,Value 里面存放的是属性(Property),这些属性是一系列 KV 对的序列化。
Edge 的 Key 是由 PartID + SrcID + EdgeType + Ranking + DstID 五元组构成,但边和点不同:一个点在 Nebula 里只存储一个 KV,但在 Nebula 中一条边会存两个 KV,一个 Out-edge Key 和一个 In-edge Key,Out-edge 为图论中的出边,In-edge 为图论中的入边,虽然两个 Key 都表示同一条逻辑边,但存储两个 KV 的好处在于遍历时,方便做出度和入度的遍历。
举个例子:要查询过去 24 小时给我转过钱的人,即查找所有指向我的账号,遍历的时候从 “我” 这个节点开始,沿着边反向走可以看到 Key 的设计是入边 In-edge 的 DstID 信息在前面。所以做 Key 查询时,入边和终点,也就是 “我” 和 “指向我的边” 是存储在一个分片 Partition 上的,这样就不涉及跨网络开销,最多一次硬盘读就可以取到对应数据。
多副本和高可用

最后再谈下数据多副本和 Failover 的问题。前面已经提到多副本间是基于 Raft 协议的数据强一致。Nebula 在 Raft 做了些改进,比如,每组 partition 的 leader 都是打散的,这样才可以在多台机器并发操作。此外还增加了 Raft learner 的角色,这个角色不会参与 Raft 协议的投票,只负责从 leader 读数据。这个主要应用于一个数据中心向另外一个数据中心做异步复制场景,也可用于复制到另外第三方存储引擎,比如:HBase。

容错机制
Nebula 对于容错或者说高可用的保证,主要依赖于 Raft 协议。这样单机 Crash 对服务是没有影响的,因为用了 3 副本。那要是 Meta Server 挂了,也不会像 HDFS 的 NameNode 挂了影响那么大,这时只是不能新建 schema,但是数据读写没有影响,这样做 meta 的迁移或者扩容也比较方便。

最后是 Nebula 的 GitHub 地址,欢迎大家试用,有什么问题可以向我们提 issue。GitHub 地址:https://github.com/vesoft-inc/nebula
Nebula Graph:一个开源的分布式图数据库。
GitHub:https://github.com/vesoft-inc/nebula