百度 AI 开放平台接口调用
百度 AI 开放平台地址 http://ai.baidu.com/tech/face
1,注册登录百度账号
2,创建应用
3,看接口文档,参考接口请求代码示例
接口文档地址http://ai.baidu.com/docs#/Face-Detect-V3/top
Face++ 人工智能开放平台接口调用
方法参考以上
代码示例
# -*- coding: utf-8 -*-
"""
测试图像中人物年龄,调用百度和face++的结果做对比
代码中key ,secret等内容保密,已删减,代码运行时请填写自己申请的key,secret等值
"""
import urllib.error
import time
import json
import requests
import base64
import glob
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def face_api(file_path):
try:
http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'
key = ""
secret = ""
boundary = '----------%s' % hex(int(time.time() * 1000))
data = []
data.append('--%s' % boundary)
data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_key')
data.append(key)
data.append('--%s' % boundary)
data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_secret')
data.append(secret)
data.append('--%s' % boundary)
ff = requests.get(file_path).content
data.append('Content-Disposition: form-data; name="%s"; filename=" "' % 'image_file')
data.append('Content-Type: %s\r\n' % 'application/octet-stream')
data.append(ff)
data.append('--%s' % boundary)
data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_landmark')
data.append('1')
data.append('--%s' % boundary)
data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_attributes')
data.append(
"gender,age,smiling,headpose,facequality,blur,eyestatus,emotion,ethnicity,beauty,mouthstatus,eyegaze,skinstatus")
data.append('--%s--\r\n' % boundary)
for i, d in enumerate(data):
if isinstance(d, str):
data[i] = d.encode('utf-8')
http_body = b'\r\n'.join(data)
# build http request
req = urllib.request.Request(url=http_url, data=http_body)
# header
req.add_header('Content-Type', 'multipart/form-data; boundary=%s' % boundary)
# post data to server
resp = urllib.request.urlopen(req, timeout=20)
# get response
qrcont = resp.read()
result = json.loads(qrcont.decode('utf-8'))
if result["faces"]:
age = result["faces"][0]["attributes"]["age"]["value"]
return age
else:
pass
except urllib.error.HTTPError as e:
pass
def baidu_api(file_path):
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=kKA8eAY&client_secret=l6bfP'
headers = {'Content-Type': 'application/json', 'charset': 'UTF-8'}
r = requests.get(host, headers=headers, verify=False)
access_token = r.json()["access_token"]
# 二进制方式打开图片文件
# img = base64.b64encode(file_path.read())
request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect"
params = {"image": file_path, "image_type": "URL", "face_field": "age"}
request_url = request_url + "?access_token=" + access_token
header = {'Content-Type': 'application/json'}
res = requests.post(request_url, headers=header, data=params, verify=False)
if res:
if res.json()["error_code"] == 0:
age = res.json()["result"]["face_list"][0]["age"]
return age
else:
pass
if __name__ == '__main__':
import pandas as pd
with open("/home/ling/skin_age/skin_Age.txt", 'r') as f:
file = f.readlines()
num = 1
result_list = []
try:
for url in file:
url = url.strip()
try:
age_1 = baidu_api(url)
age_2 = face_api(url)
except Exception as e:
print(e)
result_list.append([url, None, None])
else:
print("{} {} {} -- {}".format(url, age_1, age_2, num))
num += 1
result_list.append([url, age_1, age_2])
finally:
dt = pd.DataFrame(result_list, columns=["image", "baidu_age", "face_age"])
dt.to_excel("age_result.xlsx") # 安装好openpyxl包
部分数据结果查看
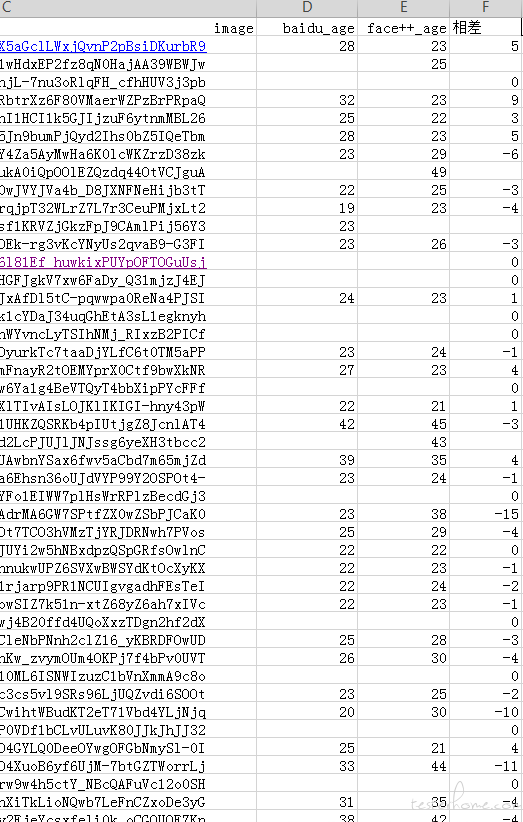
有部分调用失败情况,可能图片大小超过出接口限制,可能网络超时。商用付费的应该会比较稳定点。
从数据上看两者年龄相差还是有点大。相差超过 10 岁的数据也有一些。
「原创声明:保留所有权利,禁止转载」
暂无回复。