selenium 介绍
官方文档:https://www.seleniumhq.org
简单来说就是做 web 自动化测试框架,可测试不同的浏览器.
webdriver 系统架构
环境搭建
- python2.7 或者 3.6
- pycharm 编辑器
- chrome 浏览器
- chrome webdriver
安装 selenium
https://pypi.org/project/selenium/
pip install selenium
chrome webdriver 选择版本
查看 chrom 浏览器的版本,需要下载其对应版本的 chrome webdriver.
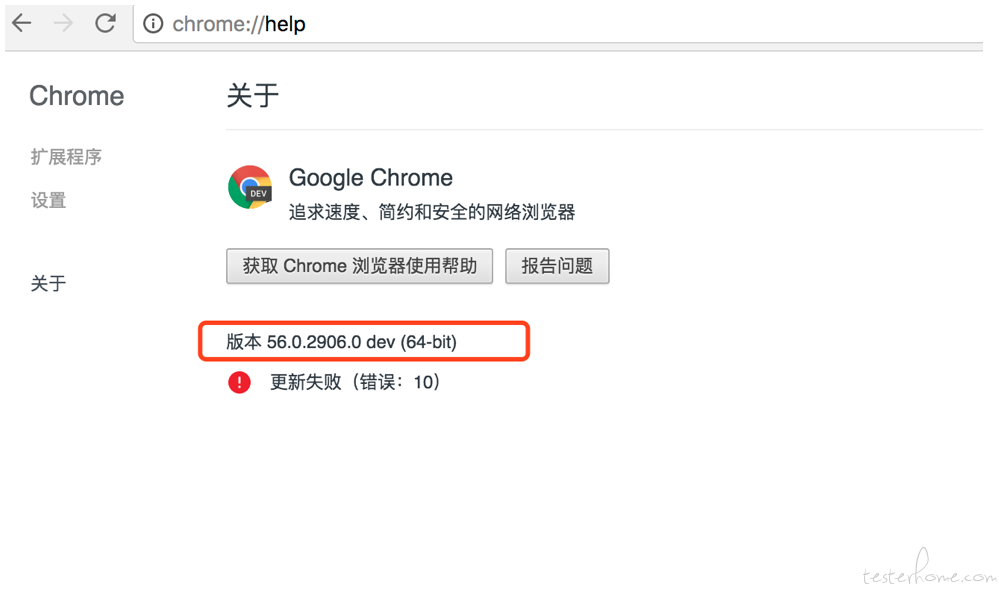
下载对照表
https://sites.google.com/a/chromium.org/chromedriver/downloads
不同浏览器的 driver
- browser = webdriver.Chrom()
- browser = webdriver.Firefox()
- browser = webdriver.Safari()
- browser = webdriver.Ie()
第一个 demo
使用 chrome 浏览器打开百度
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
报错提示需要指定"chromedriver"路径.
解决方案下载对应版本的 chromedriver,代码改动如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path="/Users/xinxi/PycharmProjects/selenium_demo/webdriver/chromedriver_mac")
# executable_path来指定chromedirver路径
browser.get('https://www.baidu.com')
指定代码,会启动一个 chrome 浏览器并且打开百度首页.
chromeOptions
- chromeOptions 是一个配置 chrome 启动是属性的类。通过这个类,我们可以为 chrome 配置如下参数(这个部分可以通过 selenium 源码看到):
- 设置 chrome 二进制文件位置 (binary_location)
- 添加启动参数 (add_argument)
- 添加扩展应用 (add_extension, add_encoded_extension)
- 添加实验性质的设置参数 (add_experimental_option)
- 设置调试器地址 (debugger_address)
设置不弹出自动化提示
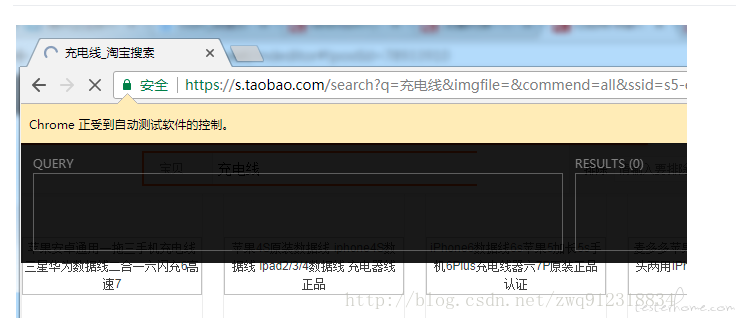
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('disable-infobars')
后台运行
option = webdriver.ChromeOptions()
option.add_argument('headless')
伪装移动设置
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
设置开发者模式
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browser = webdriver.Chrome(executable_path=chromedriver_path, options=options)
禁止加载图片
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs
元素定位
web 页面所有的元素最终都是以 html 格式展示.
使用 chrome 浏览器,右键查看页面元素.把鼠标定位到元素上,页面会自动定位到页面上.
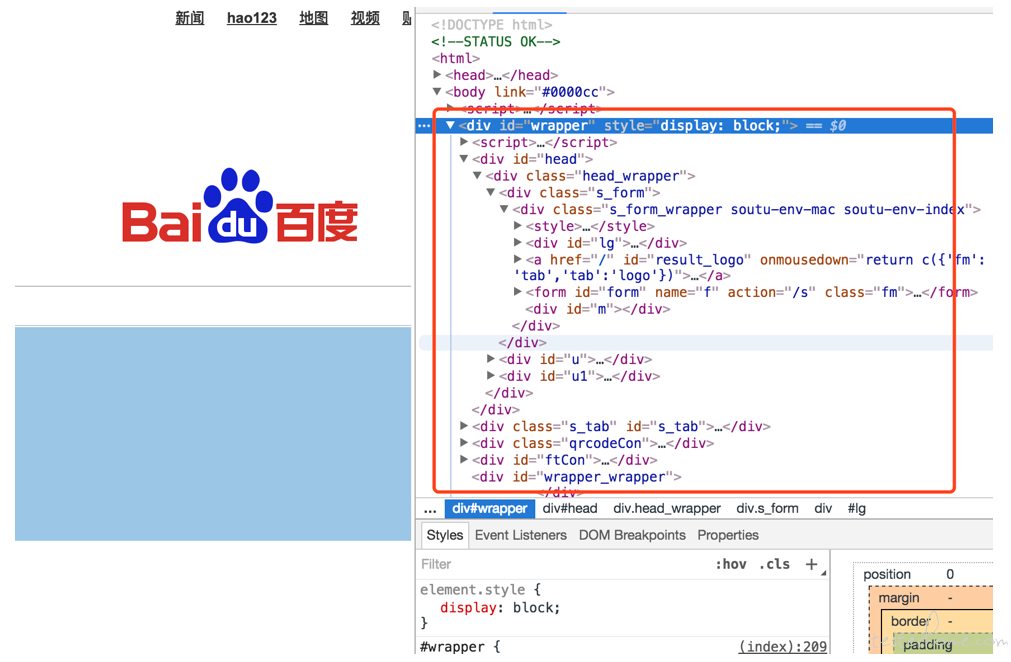
所以做 web 自动化的关键点是如何操作这些元素,模拟点击、滑动、长按等操作.
selenium 提供了八种元素定位方式
name 定位
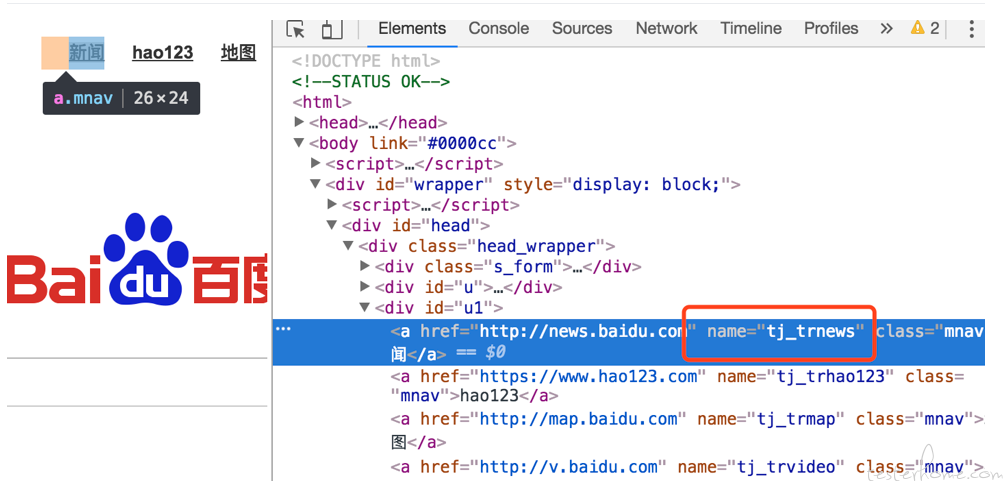
browser.find_element_by_name("tj_trnews").click()
id 定位
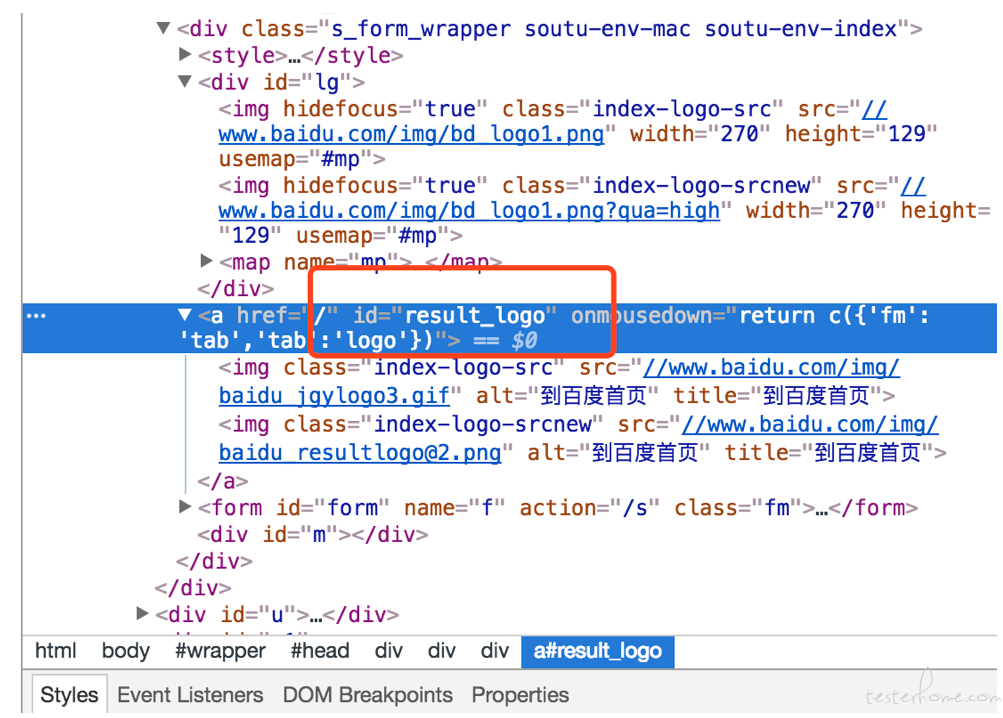
browser.find_element_by_id("result_logo").click()
class 定位
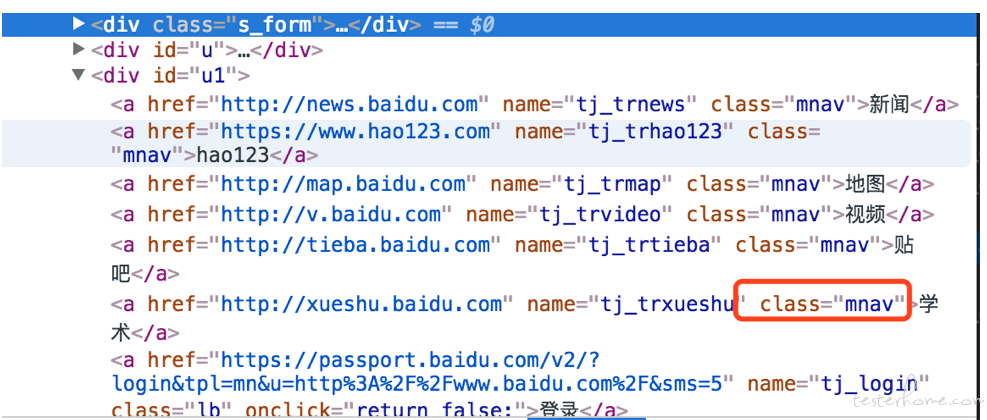
browser.find_element_by_class_name("mnav").click()
link text 定位
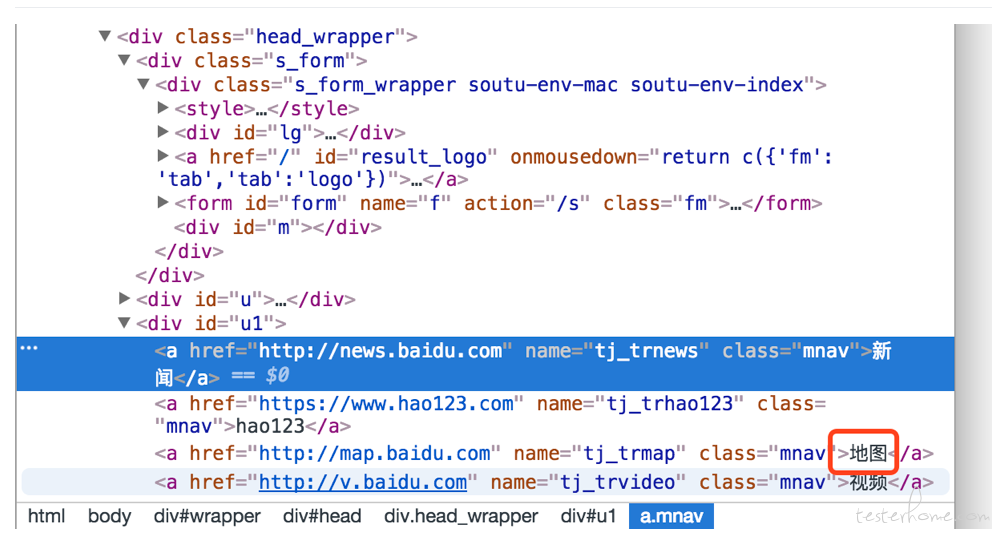
browser.find_element_by_link_text("地图").click()
xpath 定位
browser.find_element_by_xpath('//*[@id="result_logo"]').click()
css 定位
browser.find_element_by_css_selector('#form').click()
partial link text 定位
通过链接文本的部分匹配来标识元素
browser.find_element_by_partial_link_text("地").click()
tag name 定位
使用 h1、a、span 这种标签定位.
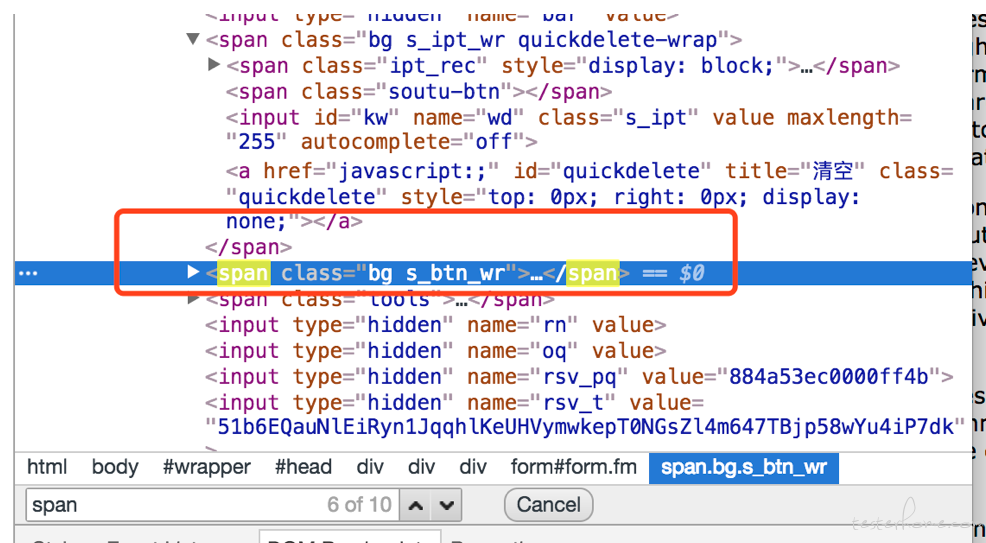
browser.find_element_by_tag_name("span").click()
定位选择顺序
id > class > name > link_text > xpath > css
frame 切换
是 HTML 元素,它定义了一个特定区域,另一个 HTML 文档可以在里面展示.
<html>
<frameset cols="25%,50%,25%">
<frame src="/example/html/frame_a.html"> <frame src="/example/html/frame_b.html"> <frame src="/example/html/frame_c.html">
</frameset> </html>
由此可见不同的 frame 包含不用的元素里里边. douban ⽹⾸⻚为例例,通过元素检查登录区域是一个 frame 区域
那⽤⾃动化脚本点击"密码登录"按钮,代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path="/Users/xinxi/PycharmProjects/selenium_demo/webdriver/chromedriver_mac") # executable_path来指定chromedirver路路径
browser.get("https://www.douban.com")
print("登录douban")
browser.find_element_by_class_name('account-tab-account').click()
print("点击密码登录")
错误提示如下:
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element:
{"method":"class name","selector":"account-tab-account"}
修改代码如下:
browser.switch_to.frame(browser.find_elements_by_tag_name("iframe")[0]) print("切换frame") browser.find_element_by_class_name('account-tab-account').click() print("点击密码登录")
此时代码运行正常,说明点击"元素"之前说明需要切换到该 frame 上. selenium 提供了了 switch_to.frame 方法
用法如下:
driver.switch_to.frame('frame_name') # 使⽤用名字
driver.switch_to.frame(0) # 使⽤用名字 # 使⽤用位置序号 driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0]) # 使⽤用标签序号
windows 切换
在 web ⻚页⾯面上经常有点击一个页⾯后,另外打开一个新窗口.是因为 html 中 target 参数是"_bank"控制.

所以在做⾃动化测试过程中,点击跳转以后.页⾯句柄还在当⻚面,所以不能点击跳转以后的页面元素. 所以此时需要切换 windows,selenium 提供了了 switch_to.frame ⽅法
⽤法如下:
driver.switch_to.window('main') window的名字
代码如下:
from selenium import webdriver
browser = webdriver.Chrome(executable_path="/Users/xinxi/PycharmProjects/selenium_demo/webdriver/chromedriver_mac") # executable_path来指定chromedirver路路径
browser.get("https://www.douban.com")
print("登录douban")
browser.find_element_by_class_name("lnk-book").click() print("点击读书")
handles_list = browser.window_handles print(handles_list) browser.switch_to.window(str(handles_list[-1])) print("切换窗⼝口")
if browser.current_window_handle == str(handles_list[-1]): print("切换窗⼝口成功...")
等待
等待的⽬目的主要是为了页面加载完成才点击元素,避免找不到元素的现象. 一共有三种等待:
硬编码等待
time.sleep(1) ,不不推荐
全局隐示等待
browser.get("https://www.douban.com") print("登录douban")
browser.implicitly_wait(10) # 会等待每个元素最⼤大时间10s browser.find_element_by_class_name("lnk-book").click() print("点击读书")
显示等待
WebDriverWait(browser, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "lnk-book"))).click() # 显示等待lnk-book 5s
使⽤用⽅方式:显示等待 > 全局隐示等待 > 硬编码等待
常用方法
获取窗口大小
print browser.get_window_size() # 获取窗⼝口⻚页⾯面当前⾼高和宽
获取 cookies
print(browser.get_cookies())
设置网络
print(browser.set_network_conditions(
offline=False,
latency=5, # additional latency (ms)
download_throughput=500 * 1024, # maximal throughput
upload_throughput=500 * 1024) # maximal throughput)
)
获取 title
print(browser.title)
获取页面元素
print(browser.page_source)
获取页面 url
print(browser.current_url)
页面放大
browser.maximize_window()
页面缩小
browser.minimize_window()
设置页面大小
browser.set_window_size(300,300)
向前
browser.forward()
后退
browser.back()
滑动
#滑到底部 js="window.scrollTo(0,document.body.scrollHeight)" browser.execute_script(js)
#滑动到顶部 js="window.scrollTo(0,0)" browser.execute_script(js)
滑动解锁
https://www.helloweba.net/demo/2017/unlock/
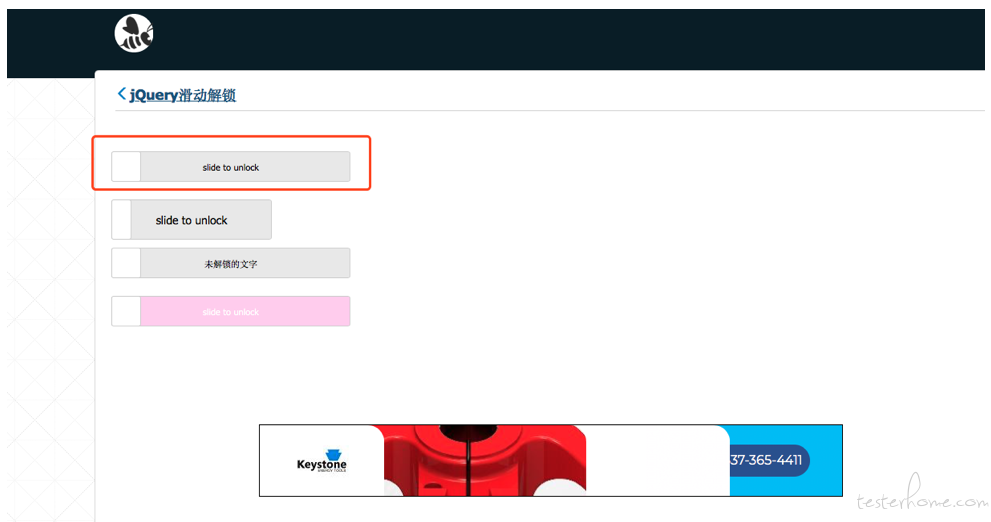
#获取拖动条
dragger = browser.find_elements_by_class_name("slide-to-unlock-handle")[0]
#获取拖动条进度条长度
dragger_text = browser.find_elements_by_class_name("slide-to-unlock-bg")[0]
x = dragger_text.location["x"]
action = ActionChains(browser)
#鼠标左键按下不放
action.click_and_hold(dragger).perform()
#平行移动大于解锁的长度的距离
try:
action.drag_and_drop_by_offset(dragger,x, 0).perform()
print("滑动...")
except Exception as e:
print("faild")
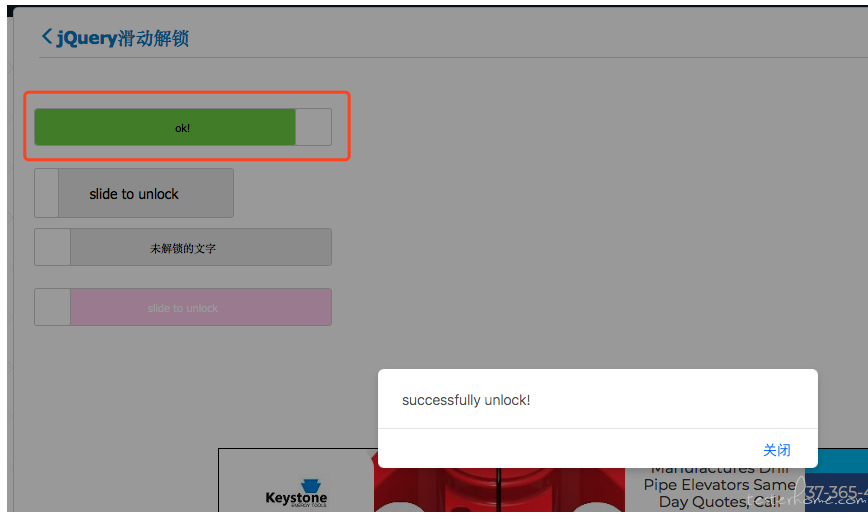
关闭弹框
time.sleep(10)
try:
tt = browser.switch_to_alert()
print("打印警告框提示...")
except Exception as e:
print("faild")
success_text = tt.text
print(success_text)
tt.accept()
截图
保存截图
browser.save_screenshot("/Users/xinxi/PycharmProjects/selenium_demo/screen_folder/截图.png")
图片流截图
sc_str = browser.get_screenshot_as_png()
sc_path = "/Users/xinxi/PycharmProjects/selenium_demo/screen_folder/截图.png"
with open(sc_path,"w") as f:
f.write(sc_str)
base64 截图
sc_str = browser.get_screenshot_as_base64()
html_tmp = """
<html>
<body>
<h1>这是一个截图</h1>
<img src="data:image/png;base64,{}"/>
</body>
</html>
""".format(sc_str)
html_path = "/Users/xinxi/PycharmProjects/selenium_demo/screen_folder/截图.html"
with open(html_path,"w") as f:
f.write(html_tmp)
参数化
参数化的目的是解决不同输入参数,测试同一条测试用例,检验预期结果的差异性
安装:pip install parameterized
文档地址:https://github.com/wolever/parameterized
实例:搜索不同名称的书籍
@allure.story("读书-搜索")
@parameterized.expand([["java"], ["python"], ["php"], ])
def test_book_serach(self, arg1):
'''
首页参数化搜索
:param arg1:
:param arg2:
:return:
'''
print("test_book_serach")
self.home_page.home_serach()
self.book_page.serach_book(arg1)
安装: pip install ddt
文档地址:https://ddt.readthedocs.io/en/latest/example.html
实例:搜索不同名称的书籍
import unittest
from ddt import ddt,data,unpack
@ddt
class MyTesting(unittest.TestCase):
@data(["java"], ["python"], ["php"])
@unpack
def test_serach(self,value):
print(value)
单元测试框架
unittest
详见:接口测试帖子介绍 unittest 框架
pytest
详见:使用 uiautomator2+pytest+allure 进行 Android 的 UI 自动化测试
nose2
nose 框架使用没有 unittest 和 pytest 多,用法也比较类似.
详见文档:https://docs.nose2.io/en/latest/getting_started.html
断言
unitest
unitest 的断言,需要类继承 unittest.TestCase
import unittest
class Testunittest(unittest.TestCase):
def test_assert_eq(self):
self.assertEqual(1,1,"不相等...")
def test_assert_ne(self):
self.assertNotEqual(1, 1, "相等...")
pytest
pytest 的断言,使用 assert 关键字,assert 可以使用直接使用 “==”、“!=”、“<”、“>”、“>=”、"<=" 等符号来比较相等、不相等、小于、大于、大于等于和小于等于.
import pytest
class Testpytest():
def test_assert_eq(self):
assert 1 == 1
def test_assert_ne(self):
assert 1 != 1
def test_assert_less(self):
assert 1 >=1
Page Objects
使用页面对象模式的好处:
- 创建可在多个测试用例之间共享的可重用代码
- 减少重复代码的数量
- 如果用户界面发生更改,则修复程序只需要在一个位置进行更改
PO 原则
https://github.com/SeleniumHQ/selenium/wiki/PageObjects
- 公共方法表示页面提供的服务
- 尽量不要暴露页面的内部
- 页面一般不做断言
- 方法返回其他 PageObjects
- 无需代表整个页面都建模
- 针对相同动作的不同结果被建模为不同方法
selenium 的 po
https://selenium-python.readthedocs.io/page-objects.html
page-objects
安装:pip install page_objects
相关介绍
https://github.com/eeaston/page-objects
https://page-objects.readthedocs.io/en/latest/tutorial.html#a-simple-page-obje
实例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time,sys,unittest,os
from page_objects import PageObject, PageElement
from selenium import webdriver
class LoginPage(PageObject):
'''
登录页面
'''
logintab = PageElement(class_name='account-tab-account')
username = PageElement(id_='username')
password = PageElement(name='password')
login = PageElement(link_text='登录豆瓣')
class TestLogin(unittest.TestCase):
def setUp(self):
PATH = lambda p: os.path.abspath(
os.path.join(os.path.dirname(__file__), p)
)
chromedriver = PATH("../webdriver/chromedriver_mac")
print(chromedriver)
driver = webdriver.Chrome(
executable_path=chromedriver)
page = LoginPage(driver)
page.get("https://www.douban.com")
driver.implicitly_wait(5)
global driver,page
def test_login(self):
driver.switch_to.frame(0)
print("切换frame")
page.logintab.click()
page.username.send_keys("11111")
page.password.send_keys("11111")
page.login.click()
assert page.username.text == 'secret'
if __name__ == '__main__':
unittest.main()
报告
报告主要目的记录成功、失败数量,错误日志,失败截图.
html-testRunner
pip install html-testRunner
报告展示:
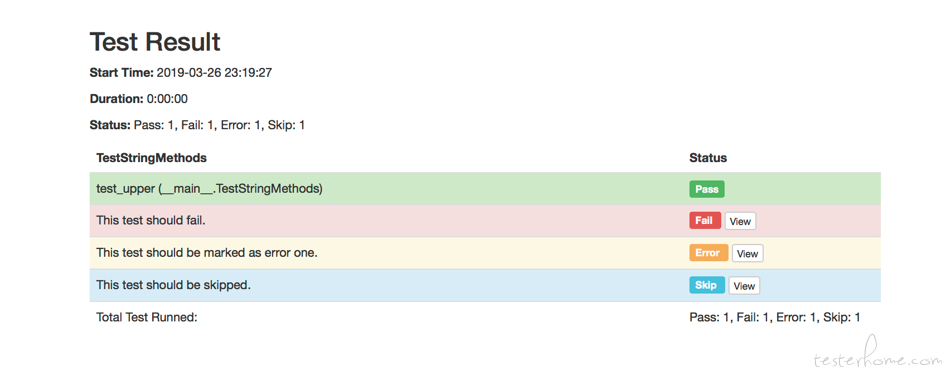
带错误截图的报告:
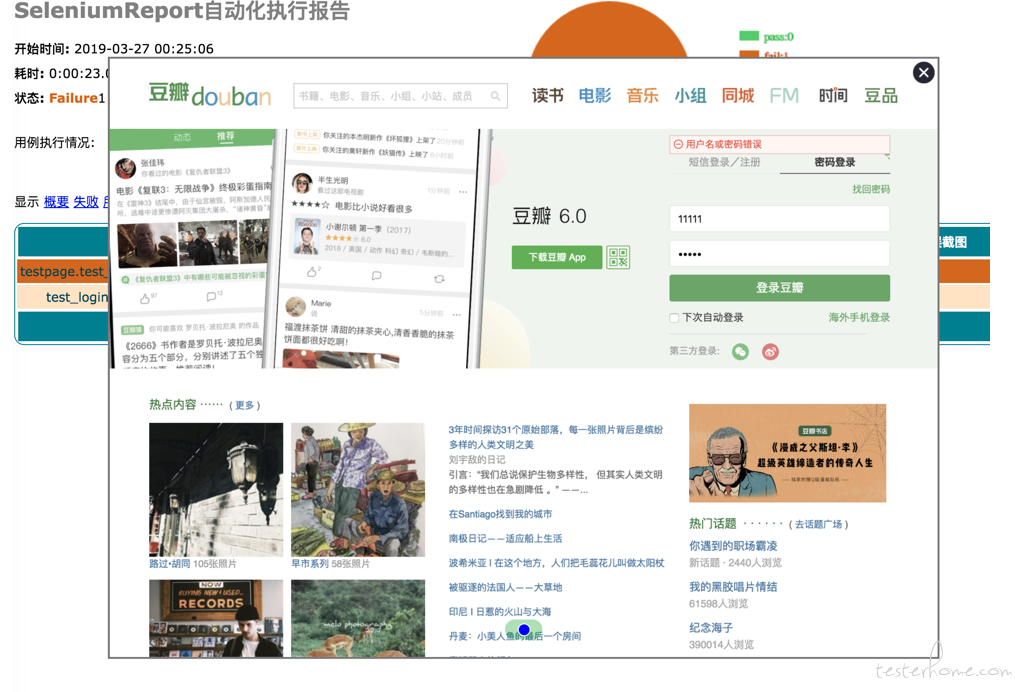
allure 报告

自定义报告
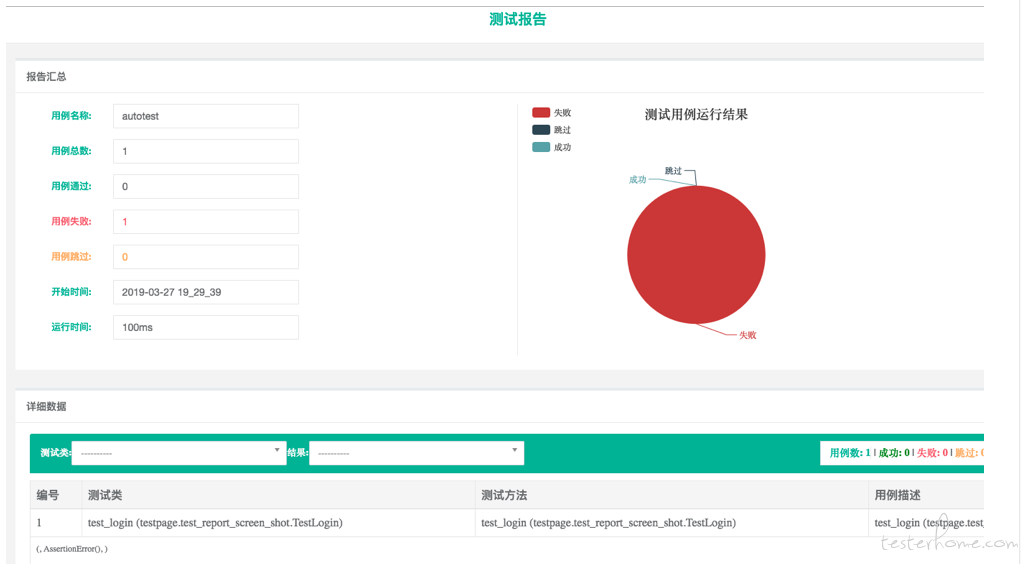
jenkins 持续集成
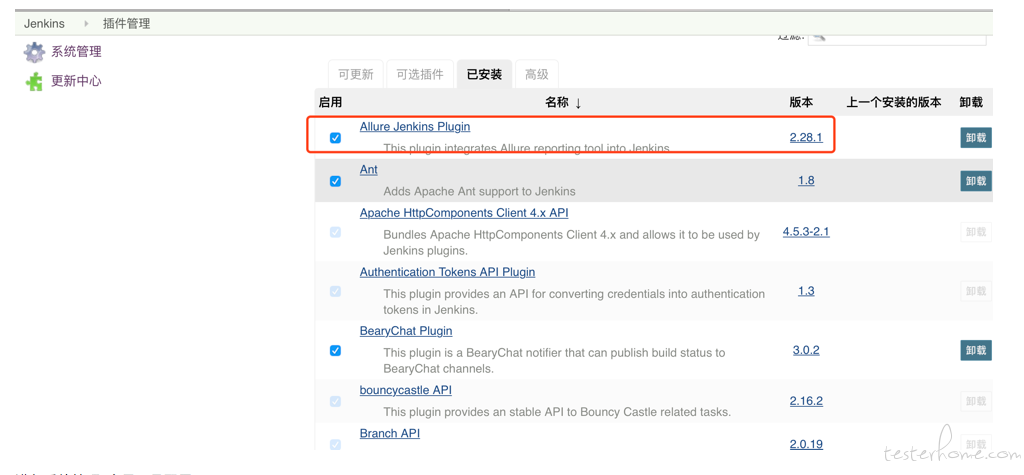
使用 Allure 作为报告展示
安装插件 allure-jenkins-plugin
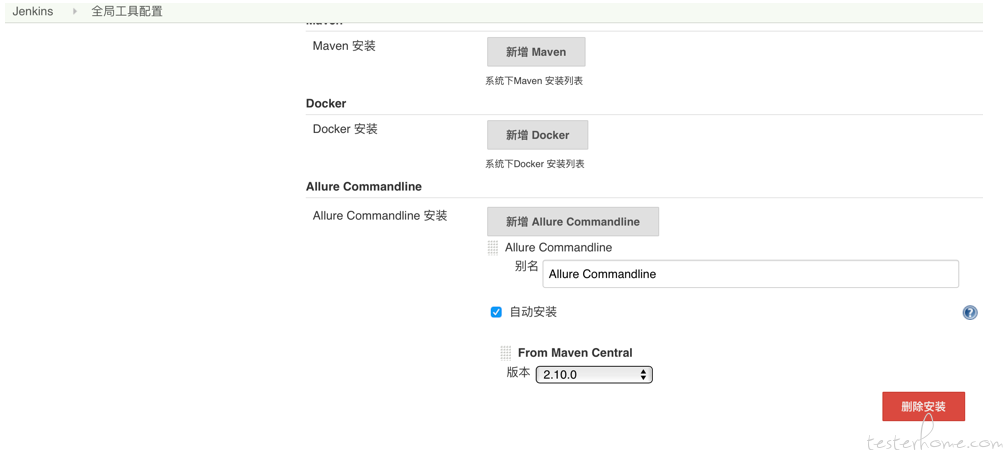
进入系统管理 - 全局工具配置-Allure Commandline
创建自动化 job
设置 allure 报告地址
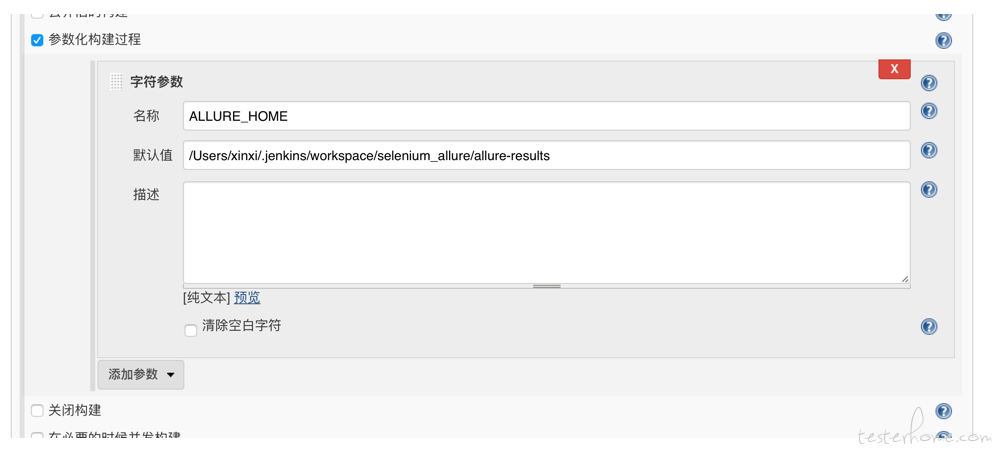
构建 shell
构建历史
selenium 分布式
官方文档:https://github.com/SeleniumHQ/selenium/wiki/Grid2
下载 selenium-server-standalone-3.141.59.jar
启动 hub
java -jar selenium-server-standalone-3.141.59.jar -role hub -port 4455
启动 node
java -Dwebdriver.chrome.driver="/Users/xinxi/PycharmProjects/selenium_demo/webdriver/chromedriver_mac"
-jar selenium-server-standalone-3.3.1.jar -role node -port 5555
-hub http://192.168.56.1:4455/grid/registe
查看节点 log 日志
http://localhost:4455/grid/console
多 node 测试
学习贴
linux 下执行
https://blog.csdn.net/qq_41963758/article/details/80320309
selenium grid
https://www.jianshu.com/p/fb1587fb0822
Selenium 跳过 Webdriver 检测并模拟登录淘宝
https://mp.weixin.qq.com/s/17t5O1S2KjZ3b_uNY0OeKQ
Capabilities & ChromeOptions
http://chromedriver.chromium.org/capabilities
selenium+python 配置 chrome 浏览器的选项
https://blog.csdn.net/zwq912318834/article/details/78933910