作者 | 李龙成
背景
线上前端 node 服务器 cpu 占满,导致访问质检报告报错,需要对线上的质检报告服务进行压力测试,了解最大并发数,以应对访问量的增长。
目的
- 发现质检报告中存在的性能瓶颈,并对性能瓶颈进行优化;
- 模拟发生概率较高的单点事故,对系统得可靠性进行验证;
- 获取线上各访问场景的性能表现,了解系统的最大承受能力;
环境
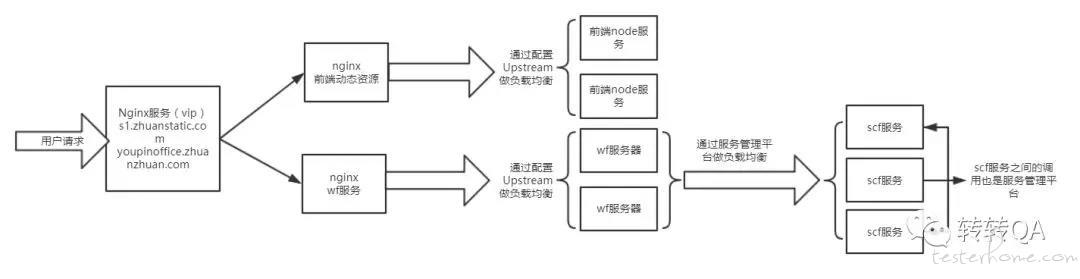
测试方案
测试工具
| 生产厂商/自产 | 工具 | 用途 | 版本 |
|---|---|---|---|
| Apache | jmter | 产生负载 | 4.0 |
压测接口
| 接口类型 | 接口地址 |
|---|---|
| 前端接口 | https://*.com/youpin/next/qcreport |
| 服务端接口 | https://*.com/business/api/ypqc/report |
压测场景
| 序号 | 最大并发数 | 访问递增方案 | 最大并发持续时间 | 观察指标 |
|---|---|---|---|---|
| 场景一 | 100 | 每秒增加 10 个 | 10min | 响应时间、TPS、事物成功数 |
| 场景二 | 500 | 每秒增加 10 个 | 20min | 响应时间、TPS、事物成功数 |
| 场景三 | 1000 | 每秒增加 20 个 | 20min | 响应时间、TPS、事物成功数 |
支持人员
在服务的保证上,我们分别告知了相关服务的责任人,比如 Nginx、Mysql、ZZRedis 和同台机器上服务的负责人,告知他们我们的压测计划,叫他们留守或者给出应急的处理方案,万一压测的过程中,相关服务挂了,可以快速恢复,防止造成大范围影响。
测试环境搭建
- 测试数据来源 由于压测线上质检报告需要线上的订单,并且要尽量少的命中缓存,所有我们从线上导出了 10w 条数据用于压测。
- Jmeter 分布式环境搭建
由于我们想要的并发数,使用单台机器模拟并发有些力不从心,甚至会引起 JAVA 内存溢出错误,所以需要分布式的形式进行施压。
使用多台机器产生负载的操作步骤如下:
- 我们申请了 4 台沙箱机,分别在这 4 台机器上安装了 jmeter,用于施压
- 配置 agent: 修改 jmeter 下面的 jmeter.properties 文件,配置执行机远程启动端口 server.rmi.ssl.disable=true server.rmi.localport=1099 server_port=1099 启动 jmeter 服务./jmeter-server
- 配置 master 修改 jmeter.properties remote_hosts 中添加 agentid,端口一定要写 1099 例 remote_hosts=10.9.193.122:1099,10.9.193.87:1099,10.9.193.83:1099,10.9.186.41:1099
- 把压测的脚本.jmx 文件和数据文件分别拷到对应的 agent 机器中
- 本地启动 jmeter,选择 run-remoter Start All,即可下发施压任务
线上服务器监控
在做压测的时候,需要对线上的服务器性能进行监控,我主要用 Spotlight 进行监控,由于转转的服务器都是通过堡垒机进行登录的,所以想监控机器需要做免密登录和端口转发,配置方式如下:
- 修改 ssh 服务的配置文件 vi /etc/ssh/sshd_config 修改 Port 33 添加一个端口
- service sshd restart 重启 ssh 服务
- 进入/root/.ssh 目录 本地系统执行 ssh-keygen -t rsa 命令,生成 id_rsa 私钥文件和 id_rsa.pub 公钥文件
- 把公钥拷贝到监控的机器的 authorized_keys 里面
- 本地启动 Proxifier,启动一个 socks5 的代理服务
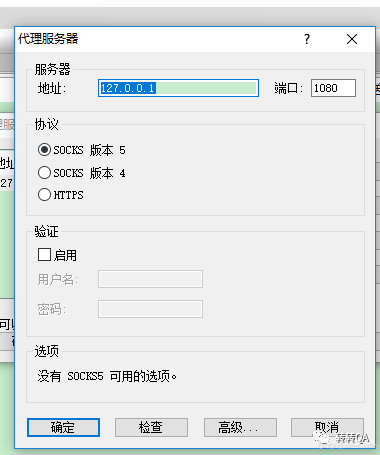
- 设置一个匹配规则,把 22 端口的请求转发到本地 127.0.0.1:1080 上
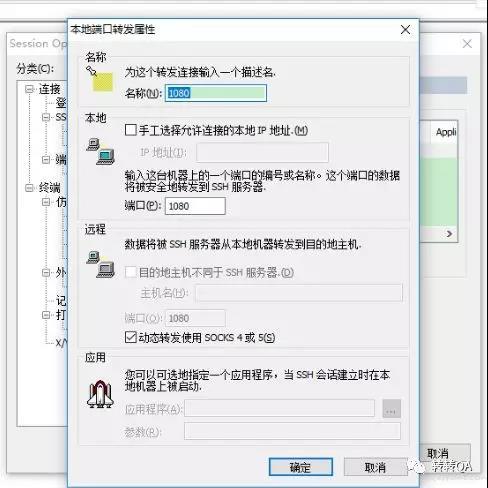
- 启动 CRT 做端口转发
用公钥登录服务器,并设置端口转发,把 1080 端口的请求转发到本服务器上
- 启动 spotlight,用私钥连接服务器
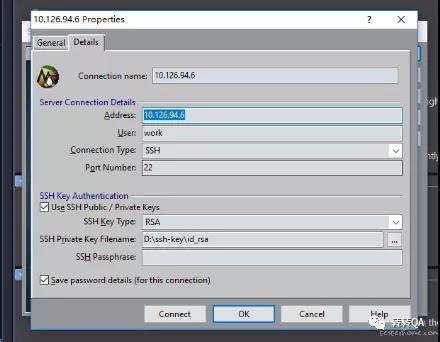 最后启动 spotlight 就能监控对应服务器的时时性能了。
最后启动 spotlight 就能监控对应服务器的时时性能了。
测试结果与分析
这里主要对其中一个前端问题进行分析
场景描述:每秒启动 10 个线程,最多起 100 个,最大并发情况下持续运行 10 分钟
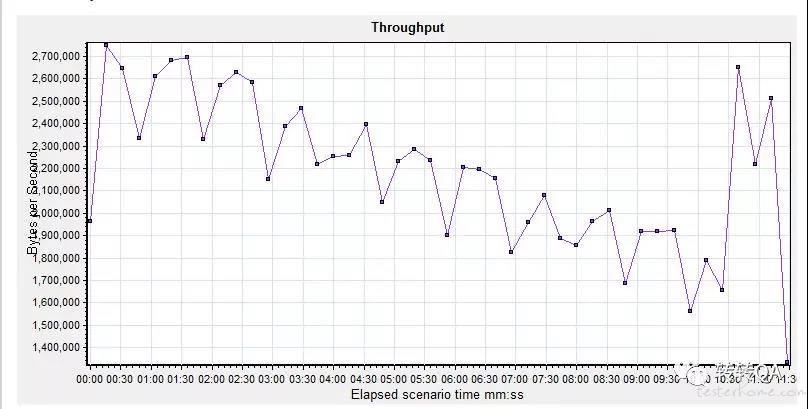
前端接口测试结果:业务吞吐量
前端服务器监控:

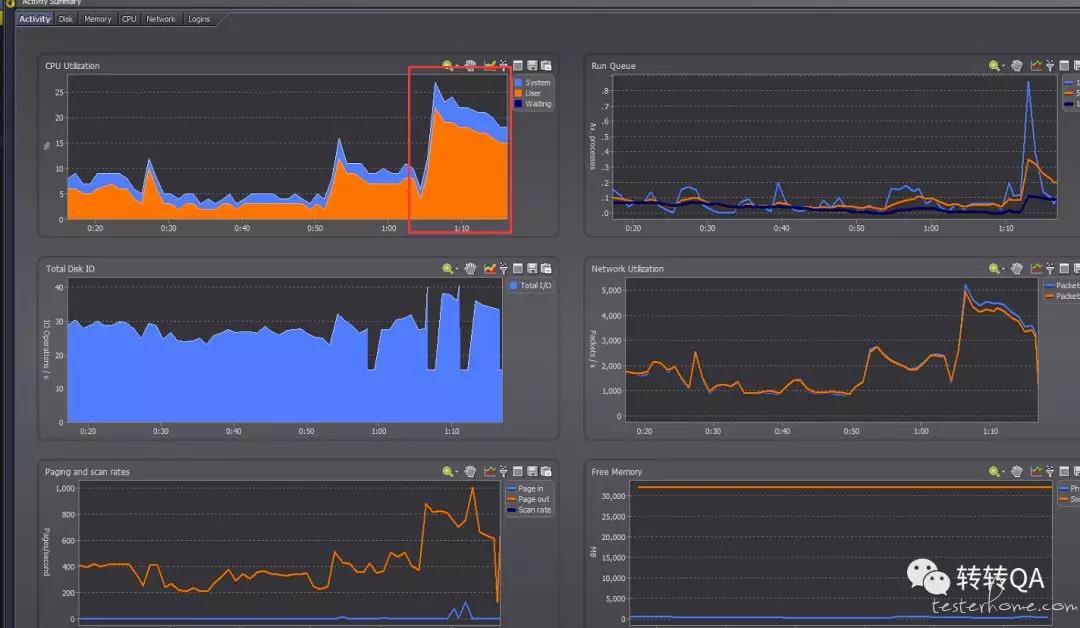
前端服务器 cpu 已经到达 100%
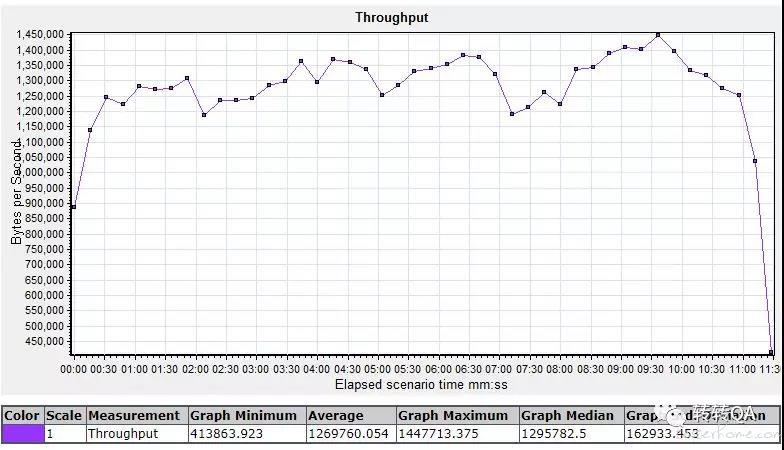
后端接口测试结果:业务吞吐量
后端服务器监控:
问题分析
从整个测试过程看:
- 前端接口当并发到达 100 时:前端 node 服务及 cpu 迅速占满,吞吐量也随之降低,平均响应时间增长;前端 node 服务有明显的性能瓶颈。
- 后端接口并发达到 100 时:业务吞吐量随虚拟用户的增加而增加,业务平均响应时间在应用服务器 CPU 占用率较低时保持平稳。
问题排查:
- 分析服务器请求连接数 通过 spotlight 我们发现请求连接数达到 6000 多,而我们的 qps 是远远小于 6000,猜测很可能是每次请求都建立了新的链接,连接一直没有及时释放,所以第一个优化点我们就在前端和后端建立连接的时候采用了长连接的形式(建立连接的时候添加 keep-alive 参数),复用连接,较少连接数
- 查看 nginx log 通过分析 nginx log,我们发现有些接口耗时是比较长的,而 node ssr server 是需要等待这些接口返回数据后才能把计算好的渲染结果返回给用户,跟相关后端同学商量,提升接口质量,同时我们把 timeout 从 5s 改为 1s
结论:
- 通过这两个优化后,我们又进行进行了一轮压测, cpu100% 的问题没有复现,服务器的各种指标也正常。
- 其他的问题就不一一列举,具体压测的性能指标在这里不便透露。关于 KeepAlive 的工作原理大家可以自行搜索相关文档。
「原创声明:保留所有权利,禁止转载」
暂无回复。