WeTest腾讯质量开发平台 游戏人工智能 读书笔记 (四) AI 算法简介——Ad-Hoc 行为编程
作者:苏博览
商业转载请联系腾讯 WeTest 获得授权,非商业转载请注明出处。
原文链接:https://wetest.qq.com/lab/view/427.html
本文内容包含以下章节:
Chapter 2 AI Methods
Chapter 2.1 General Notes
本书英文版: Artificial Intelligence and Games - A Springer Textbook
这个章节主要讨论了在游戏中经常用到的一些基础的人工智能算法。这些算法大部分都出现在一些人工智能和机器学习的入门书籍中。在讲解算法在游戏中的应用的时候,会以吃豆人(Ms Pac-Man) 作为样例,讲解怎么用行为树算法,树搜索算法,监督学习算法,无监督学习算法,强化学习算法和进化算法来构建一个玩游戏的 AI。

吃豆人
一. AI 算法的基本要素
这些 AI 算法虽然形态各有不同,但是本质上都是基于两个基本的要素来做文章。一个是算法的表示 (Representation), 另外一个是效用 (Utility)。
首先是怎么把学到的玩游戏的知识用某种数据结构来表示出来。这个数据结构也是和要用的算法强相关的。比如如果用文法演化算法 (Grammatical Evolution),最后学到的就是一些文法(Grammars);如果用概率模型或者有限状态机,最后知识就表示成一个图 (Graphs);而行为树和决策树还有遗传算法会学到一颗树 (Trees),神经网络自然是联结主义的 (Connectionism), 遗传算法和演化策略会带来一些基因编码 (Genetic Representation), 而 TD-learning 和 Q-learning 则学到了一下状态转移的表格 (Tabular)。
当然,寻找一个最优的算法表示通常是很难的,并且世界上没有免费的午餐,算法之间总是各有利弊的。不过一般来说,我们希望选择的算法的表示尽可能的简单,和占用更小的空间。而我们需要有一些先验知识来找到一个较好的算法表示。
另外一方面,我们会用效用(Utility) 这个来自博弈论的术语来指导算法的训练。不严格的来说,可以把它看做一个函数,输入是当前状态和算法可能的动作 (Action),输出是算法做出某个动作所能够获得的好处。理论上来说,如果我们能得到一个准备的 Utility Function, 我们的算法每次都可以找到最优的路径。但实际上,我们只能够得到一个估计值,或者更确切的,在没有先验知识的情况下,我们只能通过记住我们探索过的状态和路径及其获得的回报来估算一个效用值来表示某个走法的好坏 (Measure of Goodness)。如果游戏本身的状态空间比较小,我们可以通过遍历所有的可能情况来得到一个准备的 Utility Function。而通常我们面对的问题都有着极大的搜索空间,因此我们希望能够尽可能的探索到更多的路径,然后在探索到的数据上进行采样来得到一个估计的 Utility。
Utility 在不同的算法上的叫法会有所不同,在含义上也有细微的差别。例如在一些树搜索算法上,我们会用启发式的规则 (Heuristic) 来指导算法的收敛。而在遗传算法上,它又被叫做适应度函数 (Fitting Function)。在优化算法上,我们更常用的词语是 Loss, Error, Cost; 而在强化学习,Reward 是一个更常用的单词,这里最主要的原因是:做 RL 的人由于整天面对着逆天难的问题,所以喜欢用 reward(相对于 loss) 来激励自己。(大雾)
这样,我们训练 AI 的过程就是寻找一套 Representation 最好的参数,可以最大化 Utility。因此,能够学到一个好用的模型,取决于 Utility Function 是否设计的合理,和我们的目标是否完全一致。对于监督学习来说,Utility 等价于其 Label;对于强化学习来说,Utility 来自于环境的反馈。而无监督学习的 Utility 则来自于数据本身的结构和共性。
二. 基于有限状态机的 AI 实现
实现一个 NPC,最简单的方法当时就是写一些规则,但这样子显然比较 low,不过在很多场景下其实也能满足需要了。如果我们把规则(If, else 语句)抽象,就变成了有限状态机 (Finite State Machine, FSM) 或者 行为树 (Behavior Trees, BT)。
FSM 直到 21 世纪的前十年都还是广泛的应用到各种游戏之中。我们可以把 FSM 理解为一个图 (Graphs), 游戏中的状态是图的一个节点(Nodes), 可以相互转化的状态之间有连线 (Edges),连线之间定义了状态转移 (Transitions) 的条件,而在每个状态中,定义了一系列的动作 (Actions),当 AI 处于该状态时,就执行具体的动作,如向左或向右或者更复杂的组合动作。
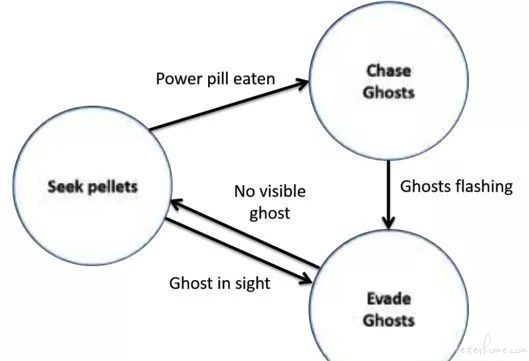
一个 FSM 的吃豆人 AI, 定义了 3 个状态:躲避 Ghosts, 追逐 Ghosts 和寻找豆子以及状态之间的转移条件
例如上面的一个基于 FSM 的吃豆人 AI,首先定义了状态和状态转移的条件。当在寻找豆子的状态的时候,可以给 AI 编程具体在每个状态的行为。比如在寻找豆子的状态,一开始随机游走,如果看到豆子就去吃掉它,如果看到 Ghost,就进入到躲避 Ghost 的状态。下面是一个简单的 3 种状态下动作的伪代码:
def seek_pellet: while 1:
if ghost_in_sight:
return evade_ghost_state
if power_pill_eaten:
return chase_ghost_state
if pellet_in_sight:
go_and_eat_pellet() #using pathfinding algorithm find best action
else:
move_randomly() def evade_ghost:
while 1:
if not ghost_in_sight:
return seek_pellet_state
if power_pill_eaten:
return chase_ghost_state
leave_the_ghost() # using tree search to find best actiondef chase_ghost:
while 1:
if power_pill_expired:
return seek_pellet_state
find_the_ghost() # using tree search to find best action
三. 基于行为树的 AI 实现
可以看到 FSM 的 AI 的模式是非常固定的,玩家很容易发现其中的 pattern,这个通过模糊逻辑 (Fuzzy Logic) 和增加概率可以得到一定缓解。另外,对于一些要完成比较难的任务的 NPC,需要为其设计很多不同的状态和状态转移方式,整个过程是非常复杂和难以调试的。因此人们定义了行为树(BT),通过模块化 (Modularity) 的设计,可以把复杂的行为拆解成简单的任务,从而减轻整个系统的复杂度和提高可维护性。因此,自光晕 2(Halo 2) 之后,BT 就取代了 FSM,成为游戏工业界最常用的 NPC 算法。
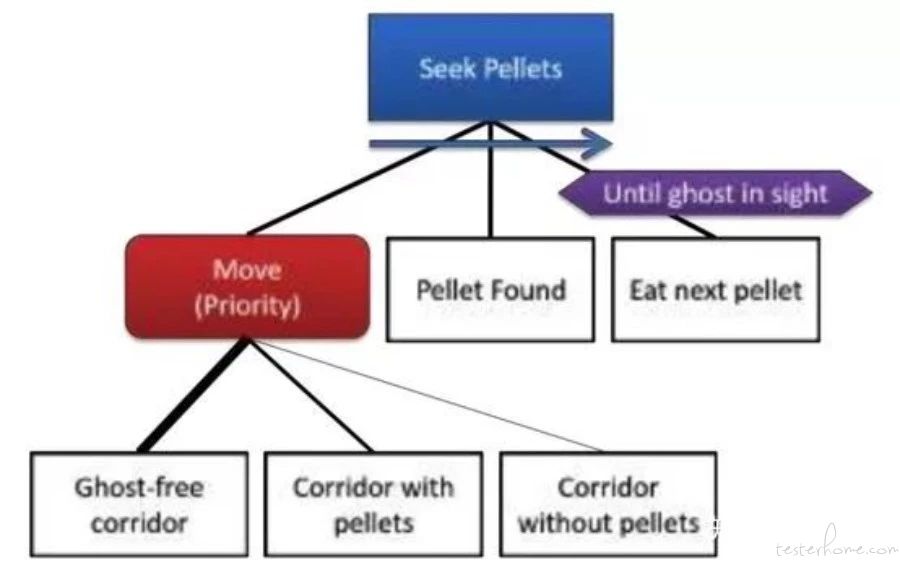
行为树是把 FSM 的图转变成为一颗树结构。因此行为树是有一个 Root 节点,然后往下有一些中间节点,最后是叶子节点。我们从根节点遍历行为树,每一个子节点被执行的时候都按预设的时间间隔回传三种信息给到父节点:
Run: 表示这个节点还在继续执行
Success:表示这个节点已经成功执行了
Failure: 表示这个节点执行失败了
而行为树的节点有 3 种类型:
Sequence: (如上图的蓝色方块)表示该父节点会顺序执行它的子节点,并且知道它的所有子节点都成功执行了,它才会回传 Success 给更上层的节点。
Selector:(如上图的红色方块)表示该父节点会从其子节点中选择其中一个执行,只要有一个子节点执行成功,该父节点就会返回 Success。除非所有子节点都执行失败,该父节点才会返回失败。父节点选择子节点的顺序有两种方式:a. Probability:按概率选取子节点执行的顺序;b. Priority: 该预设的顺序选取子节点。
Decorator:(如上图紫色的方块)相当于节点执行增加一些条件,比如限定执行的时间,或者失败重新执行的次数。如图中是限定了一个条件,只有在看到 Ghost 的时候,吃豆子 (Eat Next Pellet) 这个节点才会返回 Fail 状态。
可以看到,行为树的结构可以比较方便的把复杂的行为分解成层次的简单结构,方便维护。例如我可以在吃豆子(Eat Next Pellet) 这个 Node 上设定新的很复杂的算法,但不会影响整个树的其他节点。同时测试起来也比较方便,我们可以针对行为树的某个子树来进行测试,而不影响整个大的框架。
当然,行为树和 FSM 也有同样的问题,就是 NPC 的行为的可预见性还是比较大的,整个行为的模式还是受限于整体的行为树框架。虽然可以通过一些概率的方式来增加一些随机性,但整体来看还是有很多局限性的。
在行为树里面,选择不同子树的方式还是稍显简单,通过一定的规则,或者预设的概率来选择不同的子节点(子树)来执行。因此人们在上面添加了基于效用的方式 (Utility-based)。简单说来,我们定义一个 Utility Function: u = F(S,a)。 根据当前游戏的环境状态 S, 得到某一个行为 a 的效用值 u。这个 Utility Function 是可以通过规则设定,也可以通过一些复杂的学习方法来得到。比如我们可以用一个神经网络去预测在当前状态下,做哪个动作更好。比如在吃豆人游戏中,可能我们就不需要来写一些规则来判断该做什么动作(比如看到 Ghost 就停止吃豆子的子树执行),而可以用更动态的方式来控制(比如 Ghost 在多远的地方,往哪个方向走,豆子和 Ghost 和 NPC 的位置关系怎么样)是否停止吃豆子的子树执行。当然更 General 的说,其实后续的强化学习,监督学习也好,都是在学一个 Utility Function 来控制 NPC 的动作。本质上,Utility-based AI 是一种构建 NPC 的思想,可以应用到不同的 AI 方法上。
更多推荐
游戏人工智能 读书笔记(一)前言与介绍
游戏人工智能 读书笔记(二)游戏人工智能简史
游戏人工智能 读书笔记(三)游戏和人工智能的相互影响
“深度兼容测试” 现已对外,腾讯专家为您定制自动化测试脚本,覆盖应用核心场景,对上百款主流机型进行适配兼容测试,提供详细测试报告。
点击:https://wetest.qq.com/cloud/deepcompatibilitytesting 了解更多详情。
如果使用当中有任何疑问,欢迎联系腾讯 WeTest 企业 QQ:2852350015