文件描述符:
- 输入文件:标准输入 0
- 输出文件:标准输出 1
- 错误输出文件:标准错误 2
常见用法:
1) 2>&1:把错误的输出重定向到 1 正常输出里面去
2) 2>/dev/null:把错误信息输出去掉,任何往/dev/null 输入的内容会自动消失
Linux 三剑客
- grep:数据查找定位
- awk:数据切片
- sed:数据修改
grep:
语法 1:从文件读取:grep pattern file
# 抓取“https://testerhome.com”请求的响应内容并保存到testerhome.html文件
curl https://testerhome.com 2>/dev/null > testerhome.html
# 从testerhom.html文件查找包含“精华帖”的内容
grep 精华帖 testerhome.html

语法 2:从管道读取数据:| grep pattern
curl https://testerhome.com 2>/dev/null | grep 精华帖

语法 3:-E 参数指定或关系:grep -E "a|b"
# 查找包含appium或者python关键字的内容,“|”表示或关系
curl https://testerhome.com 2>/dev/null | grep -E "Appium|Python"
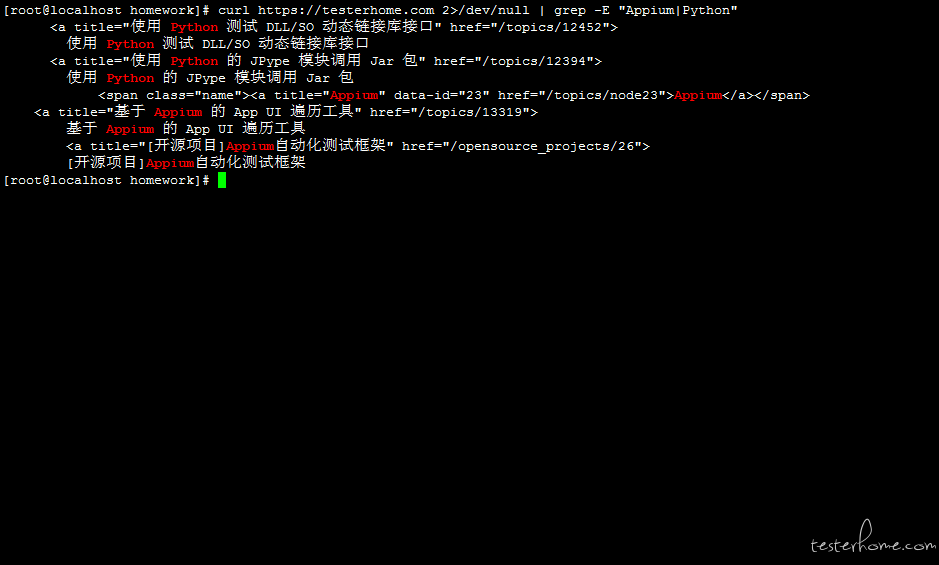
语法 4:-v 参数过滤内容:grep appium | grep -v python
# 只输出包含Appium的内容不输出包含Python的内容(过滤掉)
curl https://testerhome.com 2>/dev/null | grep Appium | grep -v Python
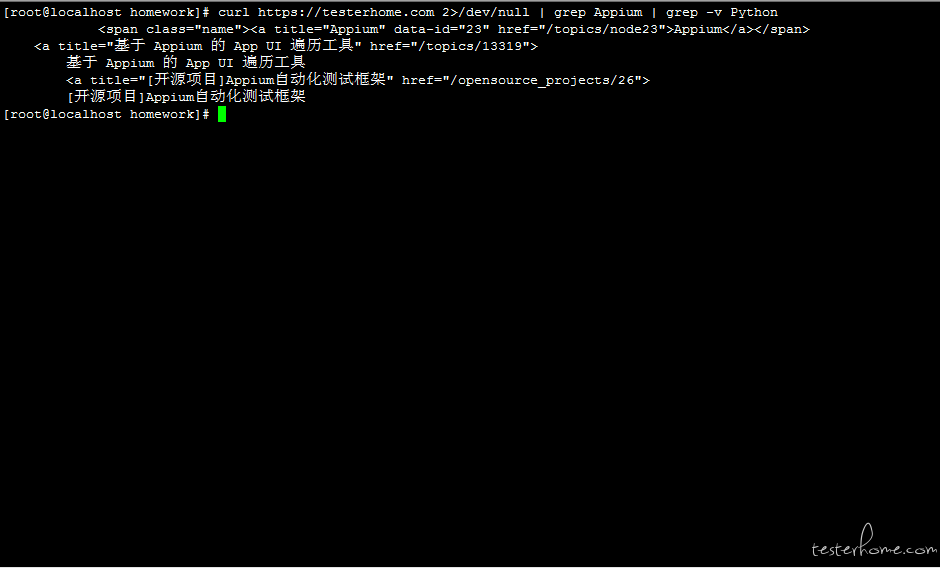
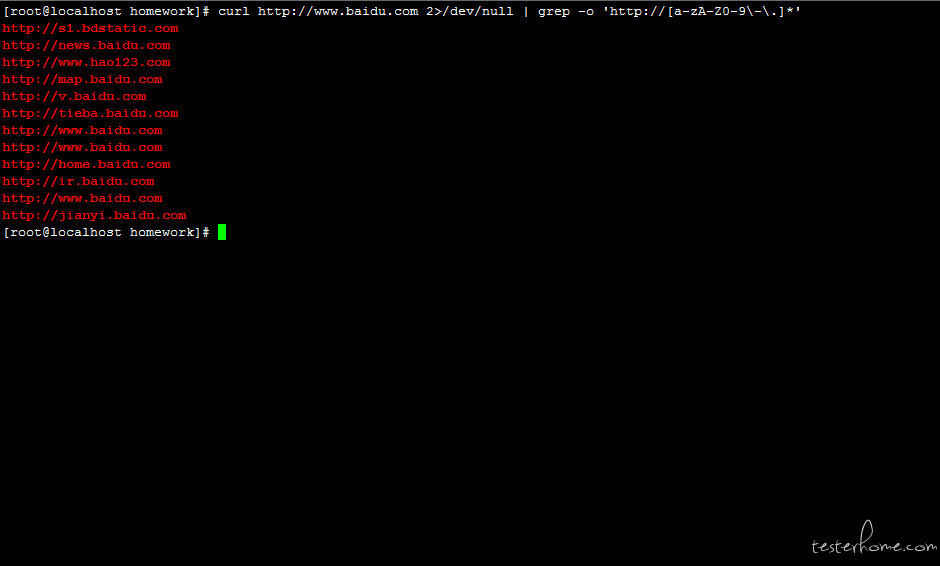
语法 5:-o 参数只取出关心的内容,不管是一行还是多行:grep -o pattern
# 筛选出百度首页包含的url,[a-zA-Z0-9\-\.]*是标准的正则表达式,中括号内指要匹配的字符内容:所有字母、所有数字、-和.
#*表示匹配前面的表达式0或多次,\表示转义,\-和\.表示匹配-和.字符
curl http://www.baidu.com 2>/dev/null | grep -o 'http://[a-zA-Z0-9\-\.]*'
awk:
awk 是 Linux 下的一个命令,同时也是一种语言解析引擎,awk 具备完整的编程特性,比如执行命令,网络请求等。
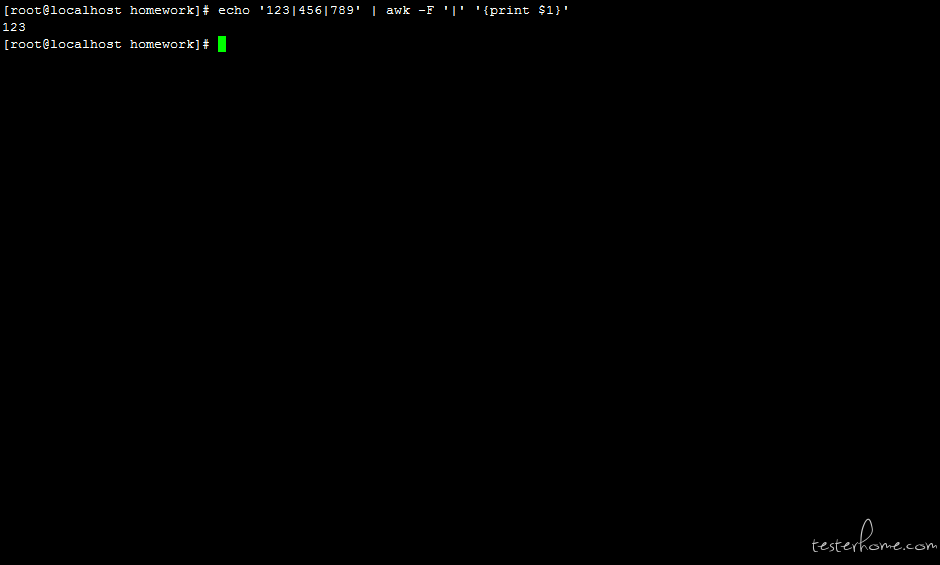
语法 1:-F 选项指定字段分隔符并拆分记录
# '123|456|789'是一个记录,-F即Filter,指定分隔符为|,即以|为分隔符拆分记录数据, $1指匹配到的第一列数据
echo '123|456|789' | awk -F '|' '{print $1}'
语法 2:多个 awk
# 查找搜索到的关键字的条数
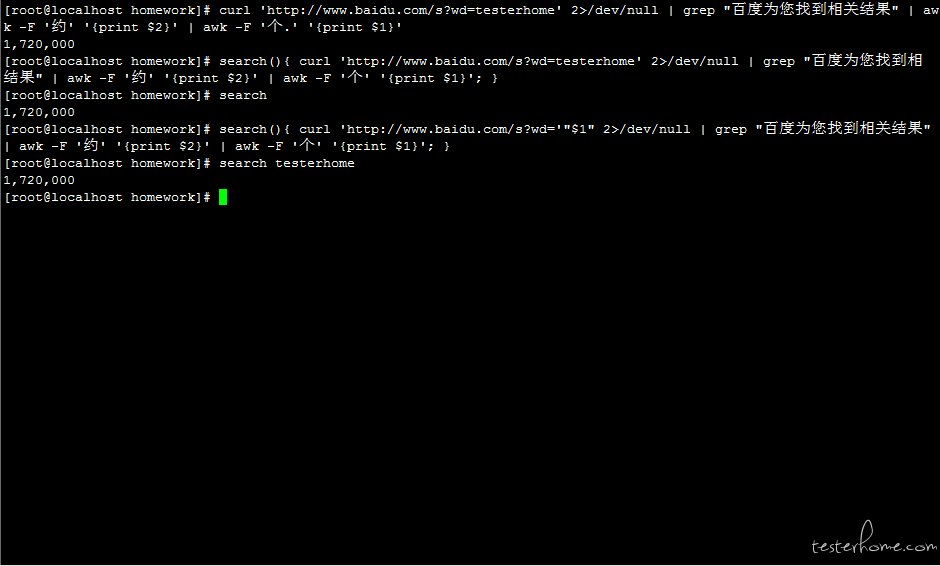
curl 'http://www.baidu.com/s?wd=testerhome' 2>/dev/null | grep "百度为您找到相关结果" | awk -F '约' '{print $2}' | awk -F '个.' '{print $1}'
# 改进1:封装为search函数,调用方法:search
search(){ curl 'http://www.baidu.com/s?wd=testerhome' 2>/dev/null | grep "百度为您找到相关结果" | awk -F '约' '{print $2}' | awk -F '个' '{print $1}'; }
search
# 改进2:封装为search函数,并将搜索内容参数化,调用方式:search 要搜索的关键字
search(){ curl 'http://www.baidu.com/s?wd='"$1" 2>/dev/null | grep "百度为您找到相关结果" | awk -F '约' '{print $2}' | awk -F '个' '{print $1}'; }
search testerhome
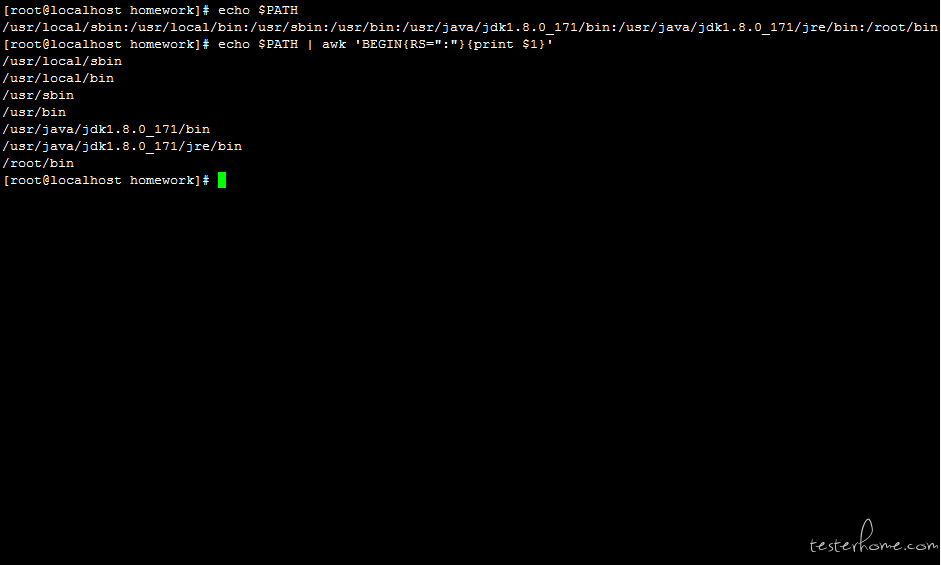
语法 3:RS 行记录分隔符,将一行拆分成多行
# RS=":"指定:为行分隔符
echo $PATH | awk 'BEGIN{RS=":"}{print $1}'
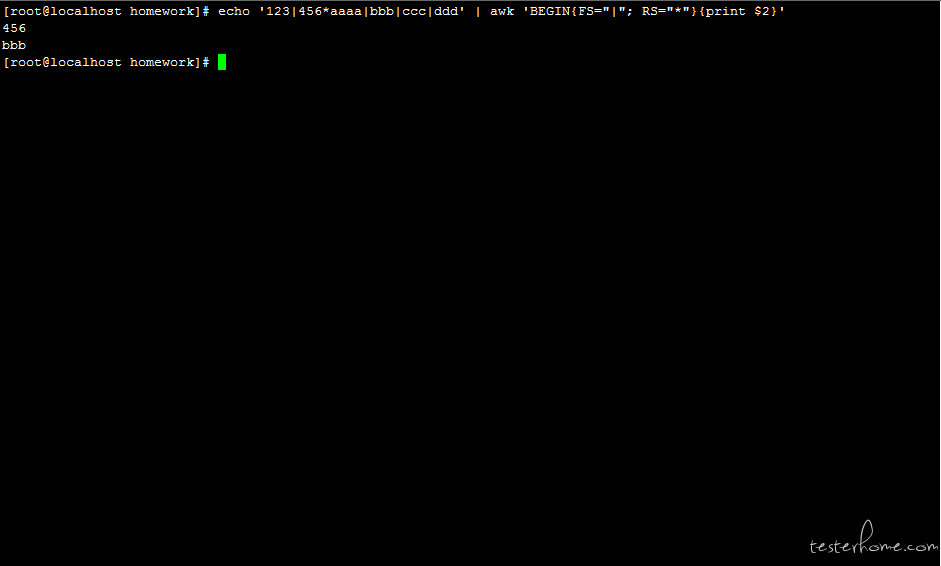
语法 4:FS 记录分隔符:'BEGIN{FS="*"} 等价于-F '*'
# 同时多个分隔符,指定FS为"|", RS为“*”
echo '123|456*aaaa|bbb|ccc|ddd' | awk 'BEGIN{FS="|"; RS="*"}{print $2}'
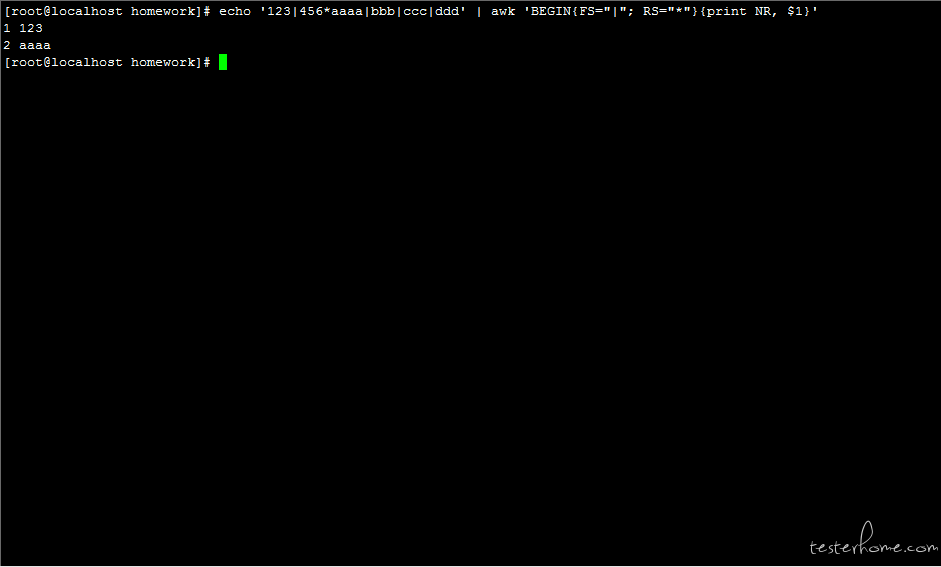
语法 5:NR 记录数:Number of Record
echo '123|456*aaaa|bbb|ccc|ddd' | awk 'BEGIN{FS="|"; RS="*"}{print NR, $1}'
语法 6:NF 字段数:Number of Filter
# 计算行的字段数:用*把记录分成2行,每行用|隔开,第一行是2个字段,第二行是4个字段
echo '123|456*aaaa|bbb|ccc|ddd' | awk 'BEGIN{FS="|"; RS="*"}{print NR, $1, NF}'
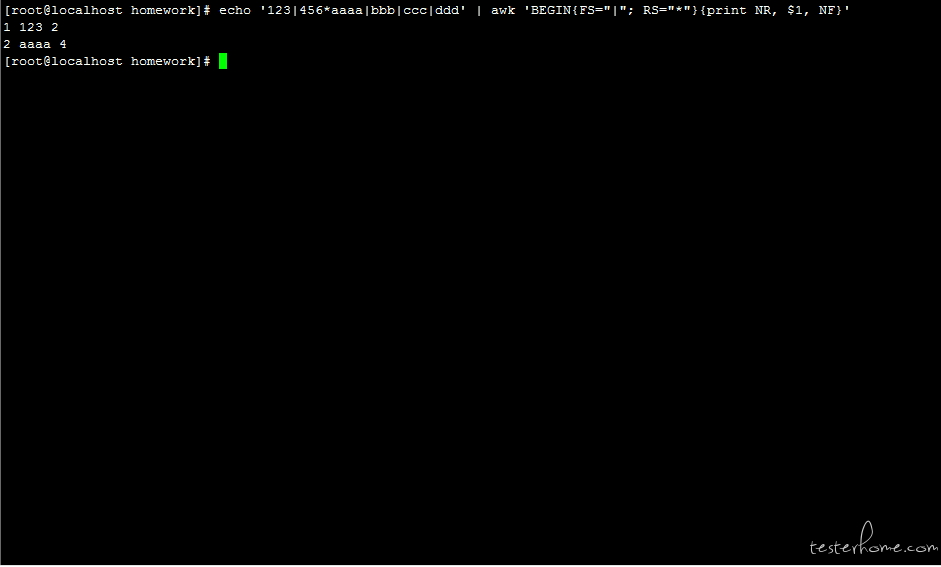
语法 7:BEGIN END:BEGIN{}是在文件开始扫描前进行的操作,END{}是扫描结束后进行的操作
# 进行浮点数运算,打印1/3的结果
awk 'BEGIN{print 1/3}'
# 扫描结束时执行打印记录数和最后一条记录
echo $PATH | awk 'BEGIN{RS=":"}END{print NR, $1}'
sed:
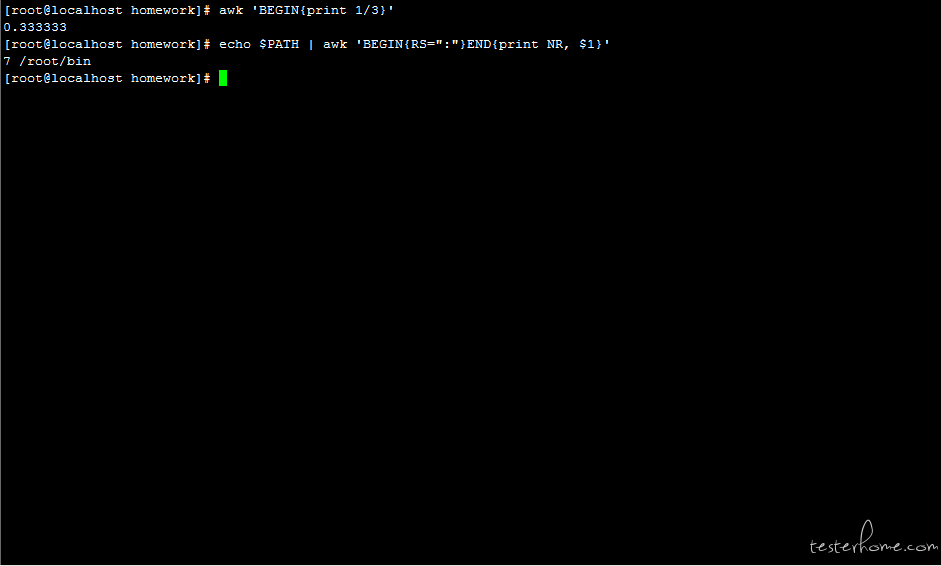
语法 1:sed 's#,##'
# 把“,”替换成空,s命令表示替换指定字符,此处使用前面封装的search函数
search mp3 | sed 's#,##'
# 把所有的“,”替换成“***”,g命令表示会替换每一行中的所有匹配
search mp3 | sed 's#,#***#g'
语法 2:指定起始和结束字符:sed -n '/start/, /end/p'
# -n表示仅显示script处理后的结果,p命令表示打印模板块的行,-n和p一起使用表示只打印那些发生替换的行
echo $PATH | awk 'BEGIN{RS=":"}{print NR,$1}' | sed -n '/java/, /jre/p'

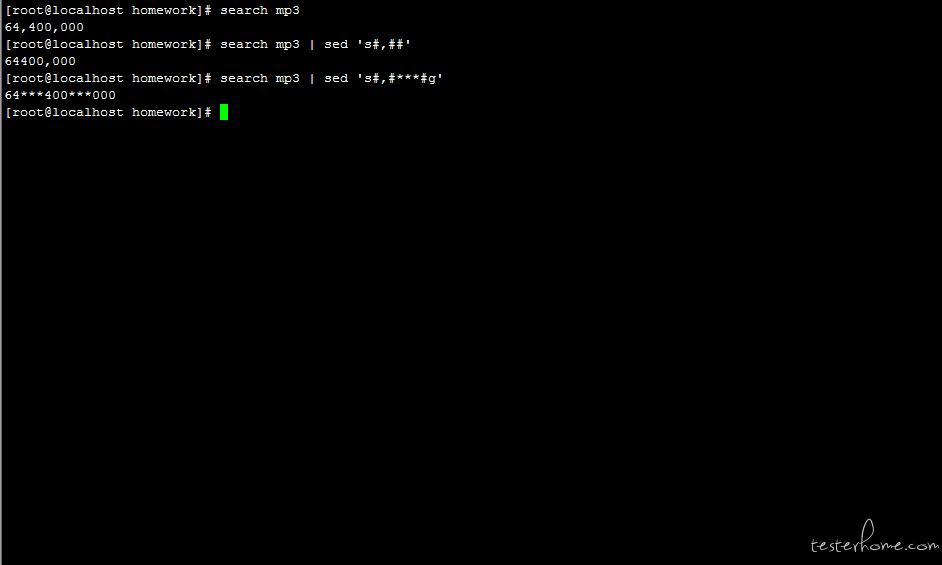
实例:访问 testerhome 的网站,找到当前页面里面的所有精华帖的标题名字
# 1. 首先使用sed指定精华帖所在的范围
# 2. 其次使用grep命令过滤包含精华帖标题的行
# 3. 最后使用awk 指定引号(")为字段分隔符,并打印行号,和每行第二个字段即精华帖标题的值
curl 'https://testerhome.com' 2>/dev/null | sed -n '/社区精华帖/, /热门节点/p' | grep -o '<a title=.* href=.*topics.*\">' | awk -F '"' '{print NR,$2}'
暂无回复。