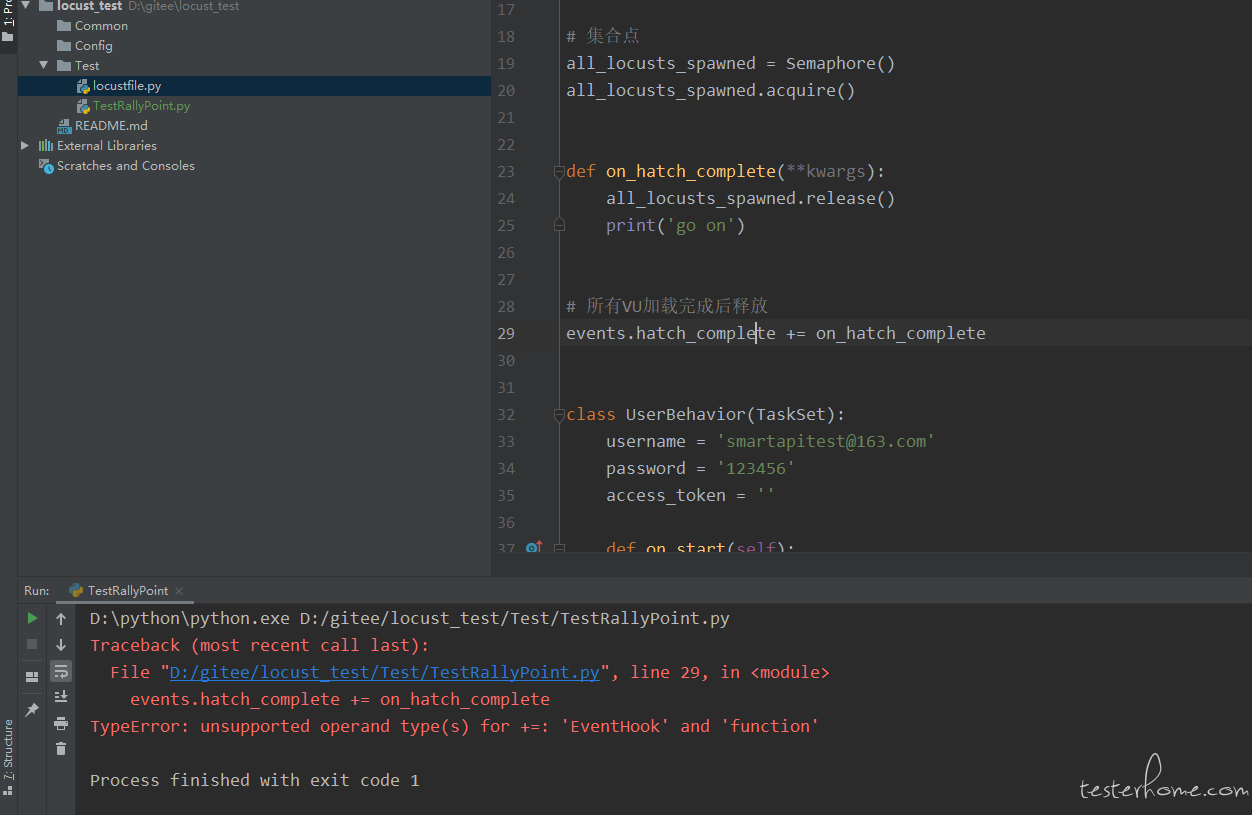
Locust 作为一款基于 Python 轻量化的性能测试工具,中小型的团队做接口压测还是比较方便的,直接编写接口事务脚本对后台接口进行测试;但有时测试需要让所有并发用户完成初始化后再进行压力测试,这就需要类似于 LoadRunner 中的集合点的概念,由于框架本身没有直接封装,google 后实践有效,分享出来:
Python 相关代码
from locust import events
from gevent._semaphore import Semaphore
all_locusts_spawned = Semaphore()
all_locusts_spawned.acquire()
def on_hatch_complete(**kwargs):
all_locusts_spawned.release()
events.hatch_complete += on_hatch_complete
class TestTask(TaskSet):
def on_start(self):
""" on_start is called when a Locust start before any task is scheduled """
self.login()
all_locusts_spawned.wait()
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!