Crash 率被称之为 APP 地雷,经常和开发者 “躲猫猫”,和用户 “亲密约见”,最终导致用户与 APP 一言不合就提分手!那么如何降低 Crash 率?做好排雷工作?
本篇文章,带您回顾美团外卖 C 端 Android APP 项目负责人王晓飞在华为终端开放实验室 Openday 上的经验分享——移动端 crash 的治理方案!

2015 年,美团外卖的 3.6 版本 DAU 和 Crash 率数据分别是不到 100 万和千分之三,如今美团最新上线的版本,DAU 已经达到 300 万,Crash 率已经降到万分之一!那么,美团外卖 APP 的低 crash 率是如何实现的呢?
1、为什么 Crash 这么重要
在分享干货之前,王晓飞算了一笔账:
一个 APP 拉新成本大约是 25 元每人,假设 3 次 crash 会导致一个用户的流失,那么一年会损失 2700 万,这非常惊人!
从时间成本算,用户下一单的时间最短大概是 120s,遇到崩溃后,重新打开 App,第二次可以成功,那么每年三百万用户为千分之三的 crash 将损失的时间是 600 天。
所以 crash 对于一个 APP 而言非常重要!
2、Crash 的分类
对于 crash 进行分类有两种,一种是常规的分类,另一种是按业务进行分类。

按业务层面的分类,可以提一点关于系统本身存在的缺陷的问题,解决系统类问题的思路在大部分时候可以进行 hook,hook 分为两种:Java hook 和 native hook。

Java hook 主要依靠 Java 动态代理和反射来 hook 掉系统 API。例如前一段时间占据美团外卖 crash 比较大的 timeoutexception,就是通过 Java 层的 hook 来解决的。native hook 原理上是将目标方法的内存地址进行替换,以达到 hook 的目的。它远比 Java hook 强大,也没有接口和 hook 点的限制,可以为所欲为,但是强大是需要付出代价的。这个代价就是兼容性。Android 各个版本的虚拟机指令集都不一致,需要小心的进行兼容性适配。
Java hook 主要依靠 Java 动态代理和反射来 hook 掉系统 API。由于是在 Java 层,产生异常可以抓住,因此比较安全可控。但 Java hook 有一些限制:Java hook 需要找到 hook 点,即切入系统的入口。我们反射或者动态代理都需要一个 object,这个 object 就是 hook 点。hook 点一般选择的是不变的对象,即静态变量和单例,以此为 hook 点,切入到系统层面,通过阅读 AOSP 代码,来找到达到目标的路径。出现问题的地方,即我们要 hook 的字段或者方法就是 “病灶”,通过阅读系统源代码,找到一条从 hook 点到目标的路径,则是我们 hook 的思路,然后反射一气呵成即可。动态代理需要对于接口才能起作用,因此在进行 Java hook 方案的构思时候,应该对 AOSP 中的接口高度关注,看到接口要多思考,能否利用?
native hook 原理上是将目标方法的内存地址进行替换,以达到 hook 的目的。它远比 Java hook 强大,也没有接口和 hook 点的限制,可以为所欲为,但是强大是需要付出代价的。这个代价就是兼容性。Android 各个版本的虚拟机指令集都不一致,需要小心的进行兼容性适配,同时不排除有的厂商艺高人大胆,去对虚拟机指令集动手脚。
根据 crash 的产生时机,我们可以划分 crash 为增量 crash 和存量 crash,存量 crash 可能是祖传的很多问题,我们一时半会没办法定位问题。但增量问题,我们肯定是有线索的,因为每一版本做了什么改动,肯定是知道的。牢牢的控制增量 crash 很重要,这保证了我们的 crash 的持续降低。这里面,就需要我们提前预防新的代码引入 crash 和对增量 crash 进行标识。
3、Crash 的治理原则

第一点,防护胜于治理;
第二点,异常不能随便被吃掉。这点可以解释下,如果我们随便的将 crash 的地方,catch 住了,那当前位置确实不 crash 了,但是后面的流程对不对了呢?所以,发生异常的地方,我们还需要根据当前的 crash 场景进行兜底,要保证不 crash,后面的流程也是正常的。
第三点,有点到面。这个的意思是说,我们看到一个 crash,不能简单的处理这个 crash,要考虑会不会在其他的地方还会有这样的 crash,如果有的话,我们怎么统一的处理和预防。
最后的一点就是监控和止损。crash 是没办法做到百分百没有的,我们得时刻去监控它,如果 crash 很严重,我们得有止损的策略。
4、Crash 的治理架构
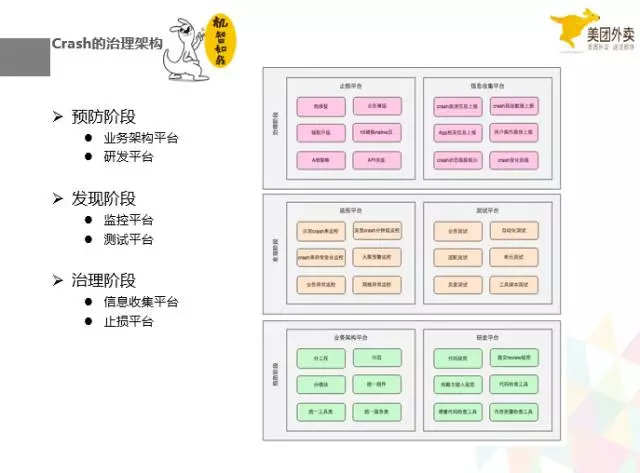
根据时间的顺序,我们按预防阶段,需要有预防的业务架构和研发平台,业务架构是一切的基础。后面我们会在对这点进行一些详细的说明。我们要有监控和测试平台,治理阶段,我们要有信心收集和止损平台。
下面我举一些例子来解析下这个张图上的一些点——
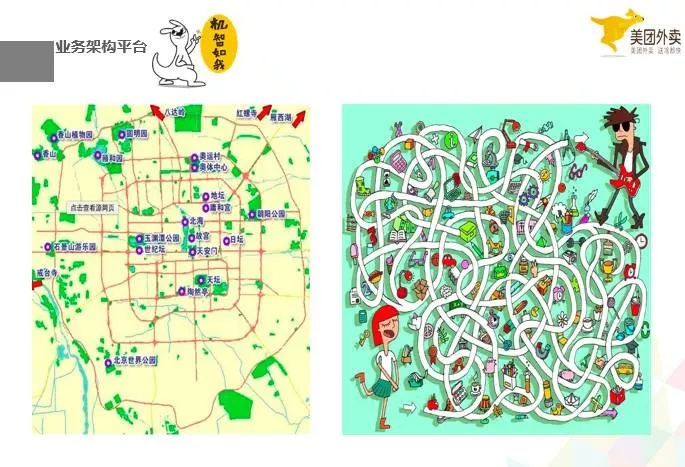
首先我想解释的是业务架构平台。左边的图是北京市地图,方方正正,右边是一个迷宫。我们假设 crash 就是在这张地图上的某一个点发生问题了,我们要去找他,我们怎么去呢?

我们根据我们的地址,北京市朝阳区望京科创大厦 A 座 4 层,找到了美团,找到了 crash,但是要面对一个迷宫一样的工程,我们怎么去找到一个 crash。不说找到 crash,这个项目想要维护下去都很难。
没有好的业务架构平台,你是很难定位 crash,很难统一治理 crash,很难从业务层面隔离不同业务产生的 crash 的,更要不说在工程里面取监控,去止损了。
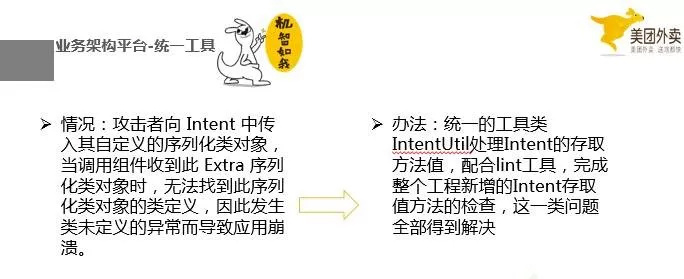
我们在监控的平台做了一个大图的预计监控,这个的前提就是外卖的业务架构平台的所有图片都是能够走到一个地方的,如果业务架构平台不是这样,你就会增加监控和止损的成本。
但是我们怎么保证所有的同学知道这点呢,毕竟维护我们的工程的人员,不是一个人,而且好多个小组了现在,我们要配合代码检查工具,当开发人员,在写这个 Intent 方法的时候,就会提醒要使用安全的,如果不使用,会报错。这样,所以的人都会遵循规范。
这个就是研发平台的需要做的事情,我们需要将常见容易 crash 的东西都建立一套标准的规范,这套规范不仅仅需要人来维护,而且需要一些工具是保证每个人来遵守,这样才会不重蹈覆辙。这也是一个由点到面的例子。
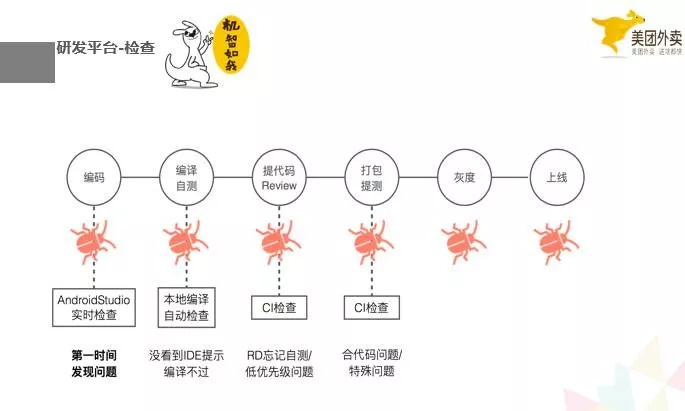
这是我们研发平台的一个检查的流程图,我们会在开发阶段,编译阶段,打包提测简单,通过本地的代码检查和 ci 检查,去查找一些 crash 的确定点和可疑点,确定点不允许编译和提到远程代码库里,可疑点给予警告。
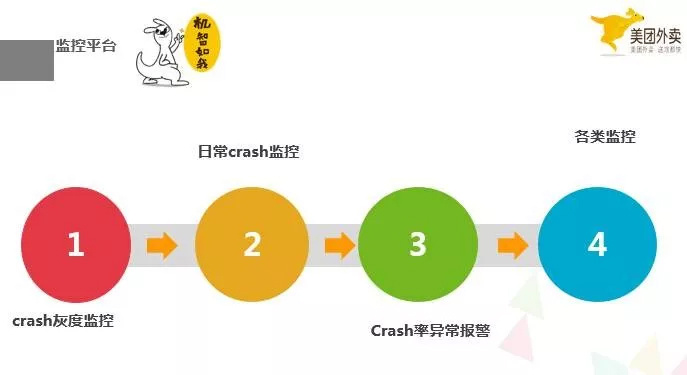
下面看下我们的监控平台做的一些事情,crash 的灰度监控、日常 crash 监控,crash 率的异常报警,和其他类的监控,例如,之前提到的大图监控。灰度监控是源头,在灰度期间,我们需要时刻关注 crash,这个阶段是增量 crash 最容易暴露的阶段,如果这个阶段没有很好的把握住,会使得增量变存量,这样就会提高 crash 率。如果条件允许的话,可以在灰度期间建立一些灰度策略去提高这个阶段 crash 的暴露。例如分渠道的灰度,分城市去灰度,分业务场景去灰度等等。
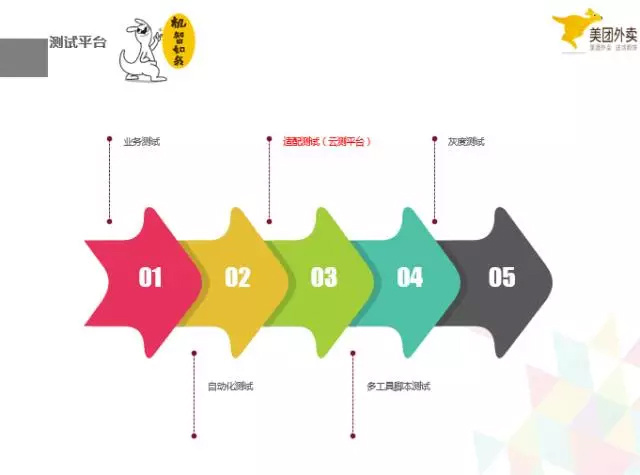
我们的测试平台,现在有业务测试,自动化测试,适配测试,工具脚本测试,灰度测定。这里重点说下适配测试,我们华为做的云测平台,我们也经常用,我觉得还是很值得称赞的一个平台,解决了我们适配机型的很重要的一个痛点。Android 的碎片化严重,想要做好适配,没有这样一个云测平台是完全不行的,现在是很难通过人工去发现所有机型存在的问题,只有通过平台来解决这件事情。我们将 apk 上传到云测平台,平台去完成自动化的测试,告诉我们有没有崩溃,哪里崩溃了,完成机型适配的工作。现在这个云测是我们 App 上线测试中,很重要的一个环节,少了这个环节,将会出现很多意想不到的 crash。
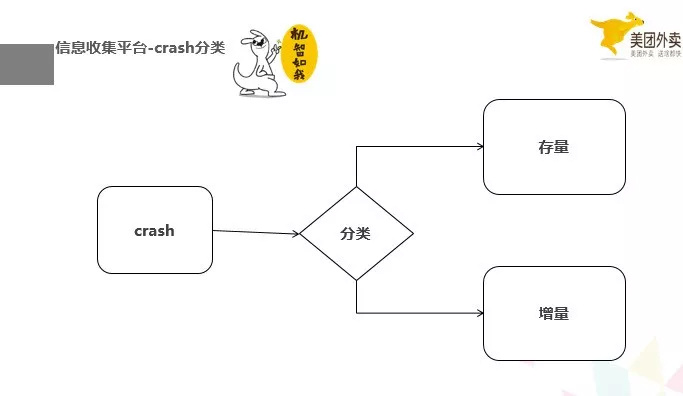
信息收集平台是治理 crash 的重要一环,你没有信息怎么解决 crash 呢,现在很多信息收集平台提供给开发者,收集的信息也很多,包括 crash 堆栈信息,机型,版本,等等,但我觉得现在的信息收集平台,缺失的一个比较重要的信息区分点,增量和存量,可能很多信息收集平台有这样的信息,但是并没有直接有过滤器过滤和展示出来,我们的美团的信息收集平台现在也是这样,我们自己做了一个小的脚本工具,现在去区分增量和存量 crash。这个增量 crash 为什么这么重要,之前也说到了,解决了增量,就能保证 crash 率。
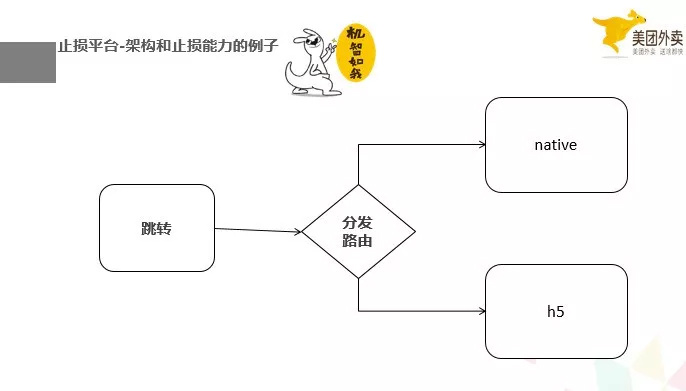
最后呢,举一个架构和止损平台结合的例子,业务的分发,在我们的架构平台,现在能做到统一到一个地方取分发,所以,如果我们能够发现一个 crash 在某一个业务出现了,那么我们可以下发指令到我们的分发路由,分发路由,就不往那个业务去跳了,跳到别的页面。如果那也业务又很重要,譬如是下单的核心流程,那我们就让跳转到具备同样功能的 h5 页面,保证能够下单。
这个止损的例子,就是架构提供的能力,你没有好的架构,可能就没办法完成这个止损。那么只能眼睁睁的看着 Crash 发生,而无能为力。
5 未来的规划
近期的一些规划,主要是结合我们的热修技术,去还原 crash 的上下文信息。有很多 crash,现在我们是知道在哪里,但不知道为什么会崩溃。如果能有上下文的数据信息,会大大提高我们治理 crash 的能力。
另一个是自动化,现在我们美团外卖的这 6 个平台,还有很多地方是人工去做的事情,很多是临时的脚本,随着我们的业务更新,这些脚本的维护也是一个很头疼的事情。我们需要一个高度自动化的能力,将每个平台之间比较生硬的融合点,变得柔和。