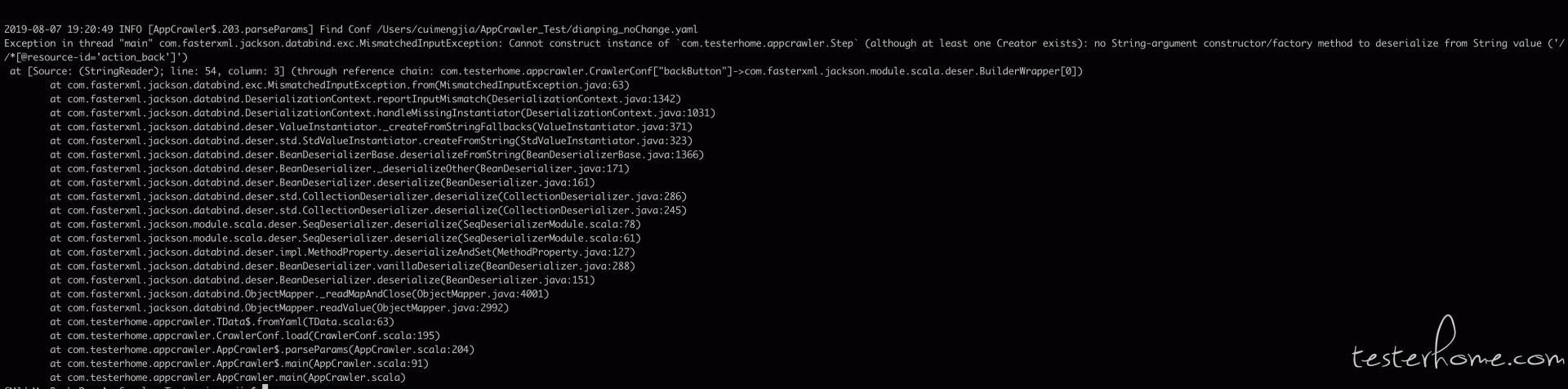
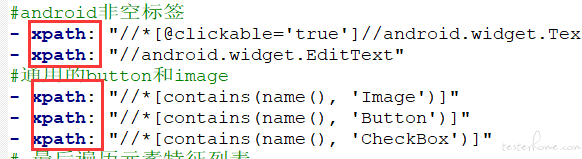
AppCrawler Appcrawler 参数实验经验
配置文件内容
存放路径 appcrawler/conf/acp.yml
配置内容
---
#插件列表
#pluginList:
#- "com.testerhome.appcrawler.plugin.FlowDiff"
#- "com.testerhome.appcrawler.plugin.ProxyPlugin"
#- "com.testerhome.appcrawler.plugin.TagLimitPlugin"
#- "com.testerhome.appcrawler.plugin.ReportPlugin"
reportTitle: AppCrawler-acp4.7
currentDriver: "android"
# 结果目录
resultDir: ""
# 最大运行时间
maxTime: 10800
logLevel: "TRACE"
#结果报告是否展示没有遍历被取消的控件
showCancel: true
#特定元素的tag布局层级完全一样时的遍历最大值
tagLimitMax: 4
#是否截图
saveScreen: true
screenshotTimeout: 20
# appium的capability通用配置
capability:
newCommandTimeout: 120
launchTimeout: 120000
platformVersion: ""
platformName: ""
# Appium是否需要自动安装和启动应用。默认值true
autoLaunch: "true"
# 直接转换到 WebView 上下文。 默认值 false
autoWebview: "false"
# 不要在会话前重置应用状态。默认值false。
noReset: "false"
# android专属配置 最后会和capability合并
androidCapability:
deviceName: "192.168.58.101:5555"
appPackage: "com.sinacp.ggaicai"
appActivity: "com.aicai.pluginhost.activity.MainActivity"
app: "/home/cmd/appcrawler/acp4.7p.apk"
# 你想使用的自动化测试引擎 可以是 uiautomator2 macaca 等 默认appium
automationName: appium
appium: "http://127.0.0.1:4730/wd/hub"
macaca: "http://127.0.0.1:3456/wd/hub"
fullReset: false
noReset: true
reuse: 3
#以下为重置手机输入法为appium输入法
unicodeKeyboard: true
resetKeyboard: true
iosCapability:
deviceName: "iPhone 6 Plus"
bundleId: "com.sinacp.ggaicai"
screenshotWaitTimeout: "10"
platformVersion: "9.3"
autoAcceptAlerts: "true"
app: "/home/cmd/appcrawler/acp4.7p.apk"
appium: "http://127.0.0.1:4730/wd/hub"
#appWhiteList:
#- android
#- com.shafa.market
# 用来确定url的元素定位xpath 他的text会被取出当作url因素
#defineUrl:
# 设置一个起始url和maxDepth, 用来在遍历时候指定初始状态和遍历深度
#baseUrl:
# 默认的最大深度10, 结合baseUrl可很好的控制遍历的范围
maxDepth: 10
# 是否是前向遍历或者后向遍历
headFirst: true
# 是否遍历WebView控件
enterWebView: true
# url黑名单.用于排除某些页面
#urlBlackList:
#urlWhiteList:
#- ".*Main.*"
# 后退按钮标记, 主要用于iOS, xpath
#backButton:
# 优先遍历元素特征列表
firstList:
#- "//*[contains(@resource-id,'com.acp.main:id/tvBottomTab4')]//android.widget.TextView"
- "//*[contains(@resource-id,'com.acp.main:id/tvBottomTab3')]//android.widget.TextView"
# 默认遍历元素特征列表 需要注意的是firstList和lastList指定的元素必须包含在selectedList中
#selectedList:
# 最后遍历元素特征列表
#lastList:
# 黑名单列表 matches风格, 默认排除内容是2个数字以上的控件
blackList:
- "//*[contains(@resource-id,'com.acp.main:id/tvBottomTab4')]//android.widget.TextView"
- //*[@resource-id='com.acp.main:id/module_tj1_name']
- //*[@resource-id='com.acp.main:id/module_tj1_description']
# 引导规则. name, value, times三个元素组成
triggerActions:
- action: "yourname"
xpath: "//*[@resource-id='com.sinacp.ggaicai:id/etUserName']"
times: 1
- action: "yourpasswd"
xpath: "//*[@resource-id='com.sinacp.ggaicai:id/etPwd']"
times: 1
遍历控制需求
进入首页后,直接优先遍历社区界面,遇到社区内登录就执行登录输入,遍历完社区退到首页不进入天天盈球界面。
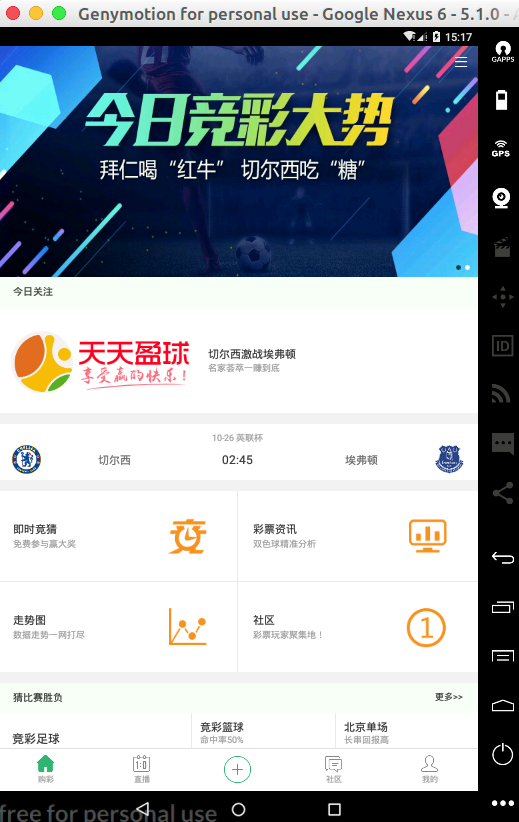
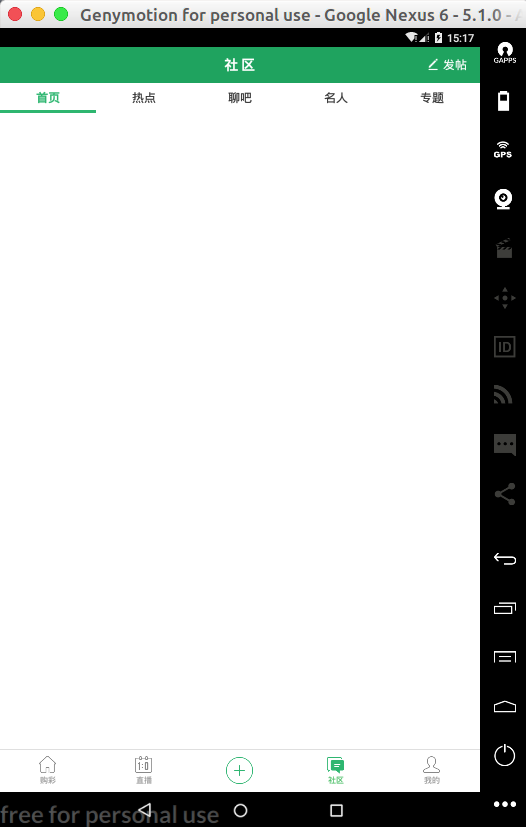
部分参数用法解释:
# 优先遍历元素特征列表
firstList:
- "//*[contains(@resource-id,'com.acp.main:id/tvBottomTab3')]//android.widget.TextView"
该段配置,是优先点击首页-》社区元素 进入社区页
tagLimitMax: 4
该值在进入社区页内,会看到效果。大家看到社区页内,有这么几个元素 首页 热点 聊吧 名人 专题 一共横向排列的 5 个元素。
如果 tagLimitMax: 4 值为 4 的话,就会只点击到第 4 个 “名人"为止,不点击第 5 个 "专题"。
官方的解释:智能判断列表和其他的相似布局元素.只遍历前 4 个相似空间. 适用于微博这种无限刷新的列表. 用于节省时间. 原理是利用特定元素的 tag 布局层级是否完全一样.
# 引导规则. name, value, times三个元素组成
triggerActions:
- action: "yourname"
xpath: "//*[@resource-id='com.sinacp.ggaicai:id/etUserName']"
times: 1
- action: "yourpasswd"
xpath: "//*[@resource-id='com.sinacp.ggaicai:id/etPwd']"
times: 1
该段配置是遇到登录界面,执行用户名和密码输入.
# 黑名单列表 matches风格, 默认排除内容是2个数字以上的控件
blackList:
- "//*[contains(@resource-id,'com.acp.main:id/tvBottomTab4')]//android.widget.TextView"
- //*[@resource-id='com.acp.main:id/module_tj1_name']
- //*[@resource-id='com.acp.main:id/module_tj1_description']
该段配置的 最后两条
- //*[@resource-id='com.acp.main:id/module_tj1_name']
- //*[@resource-id='com.acp.main:id/module_tj1_description']
是点击首页天天盈球区域的那两个文字描述的元素 resource-id , 这两个文字描述都将进入天天盈球页内。通过设置
黑名单过滤掉,不点击这两个文字描述元素,这样就进不了天天盈球页内了。如果只留一个 ,遍历将顺序遍历到第二个文字描述,这样还是会进入盈球页内。所以此处要过滤掉两处位置才不会进入盈球页内。
经验
可以先默认不带 /conf/acp.yml 任何配置文件 让 appcrawler 自己全部遍历,可以设置遍历时间参数 maxTime: 来控制遍历最大时间,这样可基本遍历到所有界面和界面内。
遍历完成后在结果目录 /result/ 你将会看到一共有这么四类文件:
1 dom 文档对象树文件
2 图片文件
3 树形的思维导图
4 appcrawler.log 日志文件
这四类文件非常有用处:
1 图片文件是按点击顺序编号的,你从第一个开始看起,就会看到 appcrawler 遍历的执行顺序,和点击了哪些元素。这样可以帮助我们观察,然后基于自己遍历流程需要,进行过滤和优先设置。
2 dom 文件也是按点击顺序编号的且和图片点击顺序一致。在配置编辑配置遍历顺序时,可以从这里来分析元素的 xpath 或其他 tag 属性来进行定位。
作者工具的思路是这样的,先去 getpagesource 获取整个界面的元素(它先将界面当做或转换为 url 类似的),并捕获为 dom 文件,这样它根据整个 dom 里的 Xpath 等属性来去做判断和是否点击遍历。所以这个很重要,自己要去定制配置的话,必须依靠该 dom 去分析。
3 树形的思维导图 是被遍历过元素的记录树形图
4 appcrawler.log 是 appcrawler 的执行过程日志。里边很详细的记录了所有做的事,且都有 index = 12 这类点击顺序的索引标识,这个索引数字标识和你的 dom 文件和图片截图中的数字标识都是一一对应的。该日志有所有的遍历执行的动作记录,对分析遍历顺序和遍历过程也有帮助。
见下图:
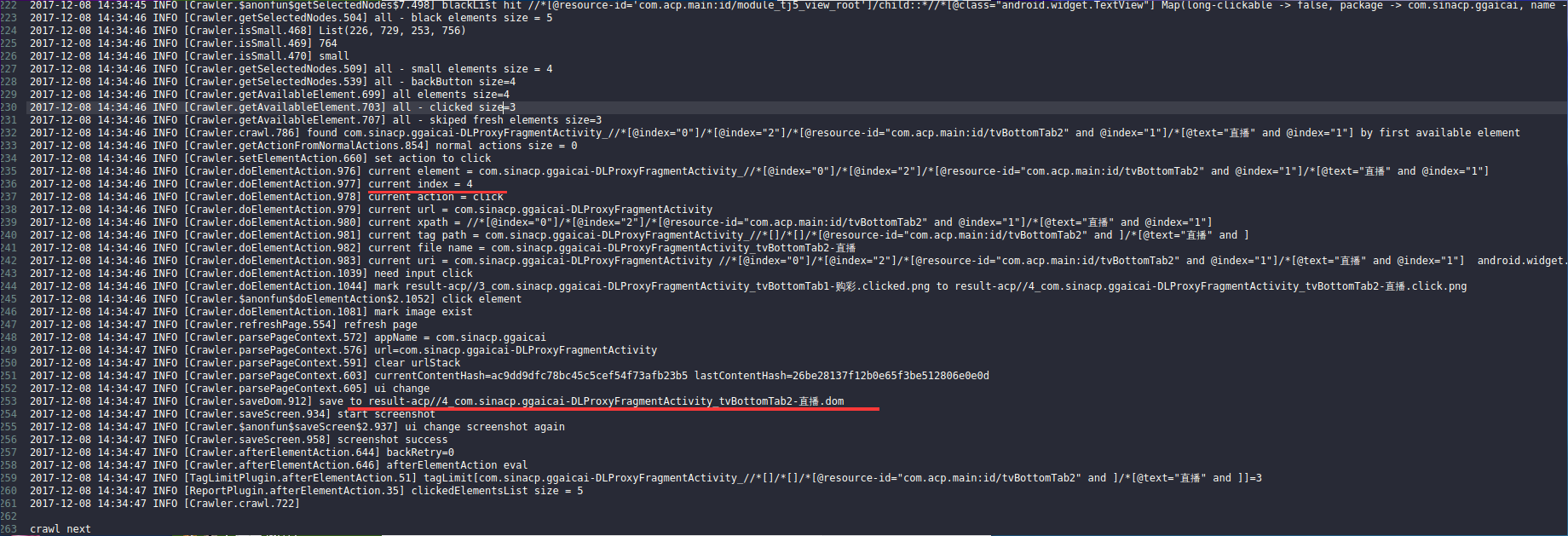
纠正
今天来补充纠正下两个参数的含义
https://github.com/seveniruby/AppCrawler/blob/master/doc/%E9%81%8D%E5%8E%86%E6%8E%A7%E5%88%B6.md
在这里我们看到了解释是这样的:
firstList 表示优先遍历元素特征
lastList 表示最后应该遍历的元素特征
那么按字面意思,我正好和作者的意思理解反了,实际作者是这么解释的。
lastList “哪一个最重要,是大类目功能的 放在最后去点击” 意思就是大多数 APP 底部都有一些大类目的功能切换,比如雪球 APP 底部的 “首页 自选 动态 行情 开户” 这些都是大类目功能。 所以之前我文章中的用法就反了,理解错 first 和 last 了。如果你想控制 APP 底部大类目的切换遍历顺序,应该讲配置写进 lastList。
firstList 这里的 first 呢 是指比如进入到一个大类目界面下了 比如 自选,那么这个自选界面内的哪些优先点击 是配置一个大类目功能界面内的优先。比如这个界面内优先遍历界面内的哪些元素。
所以作者的 xueqiu_private.yml
firstList:
- "//*[contains(name(), 'Popover')]//*"
- "//*[contains(name(), 'Window')][3]//*"
- "//*[contains(name(), 'Window')][2]//*"
selectedList:
#android非空标签
- //*[@clickable="true"]//android.widget.TextView[string-length(@text)>0 and string-length(@text)<20]
- //android.widget.EditText
#ios
- //*[contains(name(), 'Text') and string-length(@value)>0 and string-length(@value)<20 ]
#通用的button和image
- //*[contains(name(), 'Button')]
- //*[contains(name(), 'Image')]
#todo:如果多个规则都包含相同控件, 如何排序
#处于选中状态的同级控件最后点击
lastList:
- //*[contains(@resource-id, 'header')]//*
- //*[contains(@resource-id, 'indicator')]//*
#股票 组合
- //*[../*[@selected='true']]
#港股 美股
- //*[../../*/*[@selected='true'] and @resource-id='']
#tab标签
- //*[../../*/*[@selected='true'] and contains(@resource-id, 'tab_')]
#ios 沪深 港股等栏目
- //*[../*[@value='1']]
#ios 底层tab栏
- //*[contains(name(), 'Button') and ../*[contains(name(), 'Button') and @value='1']]
#tab低栏
- //*[contains(@resource-id,'tabs')]//*
是这样写的。看界面就能理解遍历顺序优先意图了。
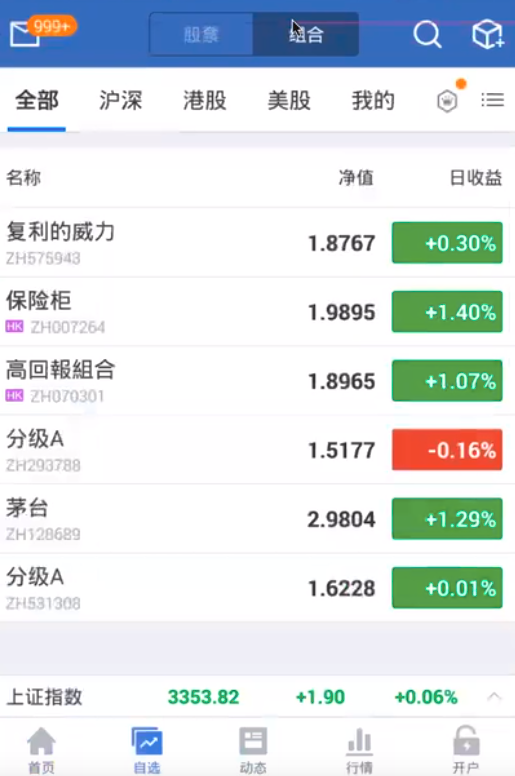
接下来 我们来自己看下对比下跑完一次遍历后的 result 结果文件。在对比配置写法,来研究遍历顺序控制。
我们在 result 结果文件 找到首页界面的 dom 打开。
我们看这句 Xpath 表达式,应该是底部的大类目功能 tab 切换标签,也就是界面上的底部 首页 自选 动态 行情 开户 五个 tab 大类目
#tab 标签
- //[../..//*[@selected='true'] and contains(@resource-id, 'tab_')]
好 我们搜索 tab_ 共找出 10 个并且且只搜出这 10 个 ,都是类似 含有 resource-id 属性 并且值是 含有 tab_ 匹配的。 说明该句可以定位到底部大类目功能 tab 标签。
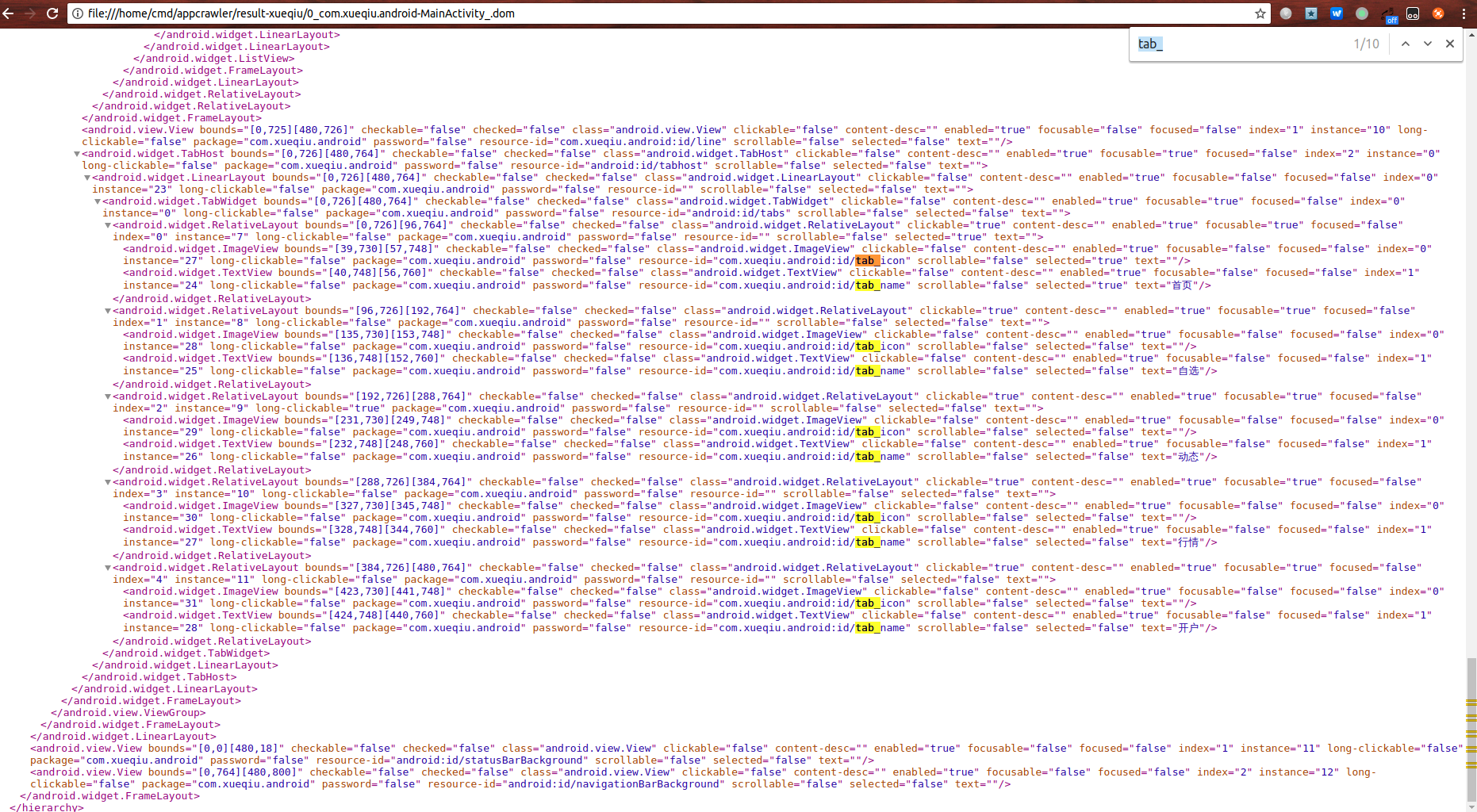
同时加上了另一个属性@selected='true' 来用 and 两个属性满足的条件 作为配置。