前言
持续交付这个专题到现在已经写了七八篇文章,前面重点都是在写 pipeline 的整体实现,这块大致的内容也都写的差不多了(docker 这个坑先不去挖它)。论坛里一些同学的认可,既让人欣慰又有些惶恐,本来已经很久没有写博文,但自己挖的这个大坑不管怎么样含泪也要填完吧 。
。
今天又看了一次目录,暂且先跳过中间各个测试方法(有点审美疲劳),决定先开始聊聊最末端的监控(别问为什么,就是任性哈哈)。
线上监控概述
也许持续交付理论更多的是强调作为软件开发交付的过程实践,发布后线上监控在《持续交付》这本书中其实已经难得觅到相关内容(这也是个人觉得这本书稍显遗憾的地方)。
但当把软件部署到机器,APP 发布到商店以后,并不意味着就万事大吉了,任何一个环节出错线上故障就会出现。所以我们还需要一整套完整线上监控体系对系统运行情况进行监测,希望一有问题就能及时发现解决,并避免问题的大面积扩大,这也是质量保障非常重要的一个环节。
目前通用的监控方法和手段主要包括:
1.运维层面的监控:包括主机资源情况、机房网络情况等
2.业务层面的监控:如在线用户数,用户活跃度等
3.APP/WEB 层面的错误监控:如 Crash 率,卡顿,性能,页面错误等
4.服务层面的监控:如服务的请求量,tps,code 反馈情况,链路状态等。
5.安全层面的监控:恶意安全扫描请求,安全感知,行为风控等
6.测试层面的监控:这篇会重点先介绍下这个,通过测试拨测实现对线上功能和可用性的监控。
线上拨测监控产生
几年前我们开始实施自动化测试的覆盖,从 UI 层到接口层,自动化测试脚本在不停的积累,并在测试环境中通过持续集成的方式发挥效力,在发布到线上以后,我们也会抽取一部分脚本进行线上的验收,但在发布验收完以后还是时不时会跑出一些故障。
原因多种多样,比如 CDN 不稳定的问题,系统性能的问题,受人恶意攻击,发布后人为操作错误,配置不当等等。出现故障以后大家压力都很大,测试同学也觉得非常委屈,发布到大半夜我做了各种验收确认那时候都是没问题的,但后面不知怎么回事又出问题了,这时我就会想是否可以把这些线上验收的脚本在线上就让他定期跑起来,监测我们所有的服务(不管是域名服务还是域名后面的各个子服务),出现问题后就通过报警机制发布给相关开发测试同学,第一时间排查问题,所以就有了这套线上拨测监控系统。
目前这套拨测监控机制已经稳定运行了三年,积累了数千个监控点。我个人对它也是又爱又恨,爱的是它确实有效发现了线上无数的故障,成为了团队应急处理的首选响应信号,恨的是多少个晚上被短信报警惊醒,需要起来召集大家排查问题,当然现在已经逐渐把报警细分到项目成员,我参与应急处理的也逐渐少了,但一些大面积的故障还是要及时参与。
需求概述
拨测监控系统是一款用于监控公司所有应用以及核心业务是否正常运行的系统。系统需要实现以下目标:
1、可以 7×24 小时自动运行。
2、监控任务范围、执行时间可动态配置。
3、可以针对 Web 服务、WebService 服务、Hessian 服务、Dubbo 服务、数据库、缓存、消息队列等等多种服务进行监控。
4、发现异常后需要邮件、短信进行报警
整体设计
软件功能模块
监控系统主要包含三个模块,分别为:
a. 各个应用监控脚本,各个负责监控各个应用或业务是否正常运行,如果出现异常发送报警短信以及邮件。
b. 监控任务调度模块,负责任务调度,定时执行监控脚本。
c. 短信以及邮件报警模块,在监控异常的时候向应用负责人发送邮件以及短信报警。
软件技术架构设计
监控系统主要采用 Jenkins + Java 技术来实现。Jenkins 主要负责任务调度、监控任务管理、监控报告发送。Java 负责各个监控功能实现,具体还涉及 Spring、HttpClient、Selenium、Appium、Maven、JUnit 等框架。说白了就是 CI 平台 + 自动化测试脚本 + 报警模块。
监控系统架构图
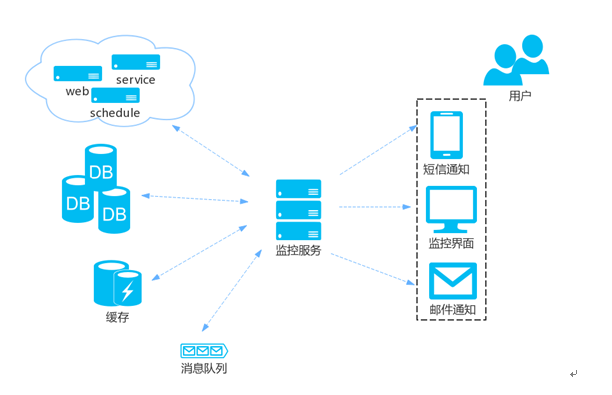
监控框架流程图
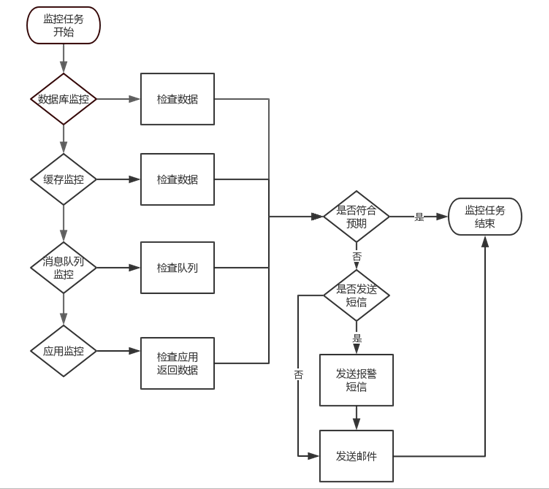
功能流程
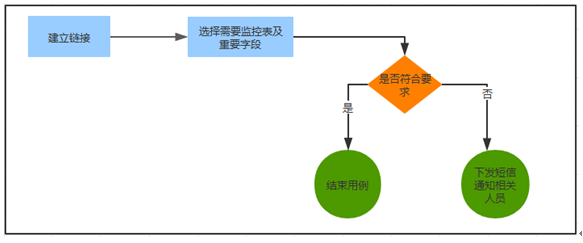
数据库监控流程
通过对应用数据库中重要表字段进行监控,当发现有异常数据入库,或者应用系统异常表中有数据插入时,能第一时间发现问题,下发短信通知相关人员跟进,确保线上系统的正常运行。主体流程图如下:
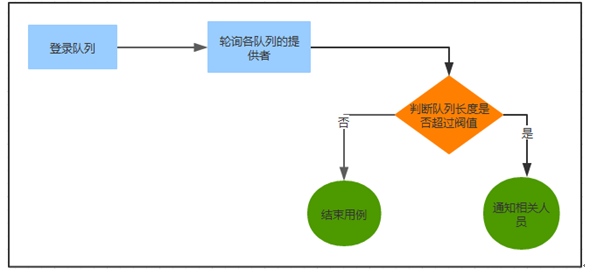
消息队列监控流程
通过定期轮询各队列提供者,当发现某个队列等待长度超过阀值时,说明队列消费存在问题,发送短信通知相关人员进行跟进。目前已实现的监控队列系统有:ActiveMQ、RabbitMQ、Kafka。
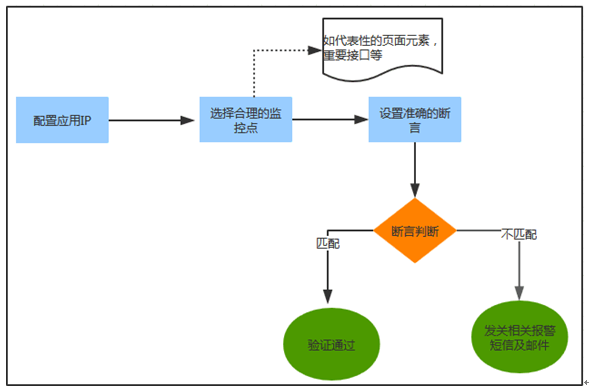
应用可用性监控流程
此功能是本系统实现的重点,针对每个线上应用,选择不同的重点功能进行监控。通过对重点功能的用例设计,制定合理的监控策略,设置准确的预期结果,通过对预期结果的断言,采集相关的返回信息,若有异常,及时下发短信通知相关人员。已覆盖超过 90% 的线上系统,为线上系统的正常运行提供了有力的支撑。
敏感请求越权监控
探测方法:这个是安全方面的一些监控,每天定时执行检查涉及敏感信息的接口或页面,检查是否存在越权获取数据的情况。
规则:只允许获取有权限的数据,无权限的数据不能获取,如果获取了无权限的数据就报警。
其实还有不少其他监控点,比如一些业务指标的对比,一些重要定时任务的执行等,都可以按需去增加。
实施要点
1.稳定,稳定,还是稳定。拨测脚本的断言点必须要保证稳定,宁可少必须精,谁也受不了大半夜被监控惊醒然后发现是一通误报。
2.与发布平台的配合,在发布的时候会先停止相应的监控脚本,并在发布完以后自动启动。
3.尽量选取读取操作进行监控,不要污染线上数据,比如说注册,购买之类的操作就尽量不要监控了。数据库监控也是只会做读操作,不允许做写入操作。
4.报警内容必须要描述清晰,具体到哪个应用,哪个服务器,在哪个环节出现了哪些错误,方便尽快的进行问题定位。
结语
在以前的理念里,线上的监控似乎都是运维团队的事情,但光靠运维对主机网络的监控,其实远发现不了应用本身的一些故障,而如果通过错误日志的监控,成本较大而且线上日志打印一般都比较混乱,也不能及时有效的发现问题。利用测试团队积累的自动化测试脚本的方式对线上进行拨测,实现成本很小会是一种不错的实现方式。
不足之处是这套机制只能发现哪里有问题,但不能详细的给出问题的原因,所以我们一般还需配合链路监控的机制进行排查,链路监控和安全监控这两个我相对熟悉的专题后面有时间的话我也会想办法整理下。
所以这篇就先到这里了,重点介绍测试层面的监控,15 年的时候看到过 rickyqiu(这家伙听说已经转型 CTO 了)的一个 PPT,也开展过类似的工作,大家也可以找来看看,其实没有太复杂的东西,在我看来就是把一些最稳定的自动化测试脚本搬到线上定时运行,并增加相应报警机制而已,每个团队都可以尝试实施。