作者:京东科技 王亚森
前言
本文旨在从 0 到 1 的讲述一下我们团队在做系统可观测性过程中所沉淀下来的一整套解决方案,收效甚巨,不敢苟藏,当公之于众,共建吾辈光明之未来。
先讲一下我们从中得到的好处:
1,当我所负责系统宕机时我能第一时间得到通知
2,当我写的业务逻辑进入 else 或者 catch 时它会通知我
3,当我新做了一个产品功能上线后,我可以监控用户的访问情况
4,我不会再担心早上没到公司就收到同事的电话说昨晚上线的应用要回滚
5,发现新做的功能上线后有问题,可以第一时间在线将功能切换至老版本运行
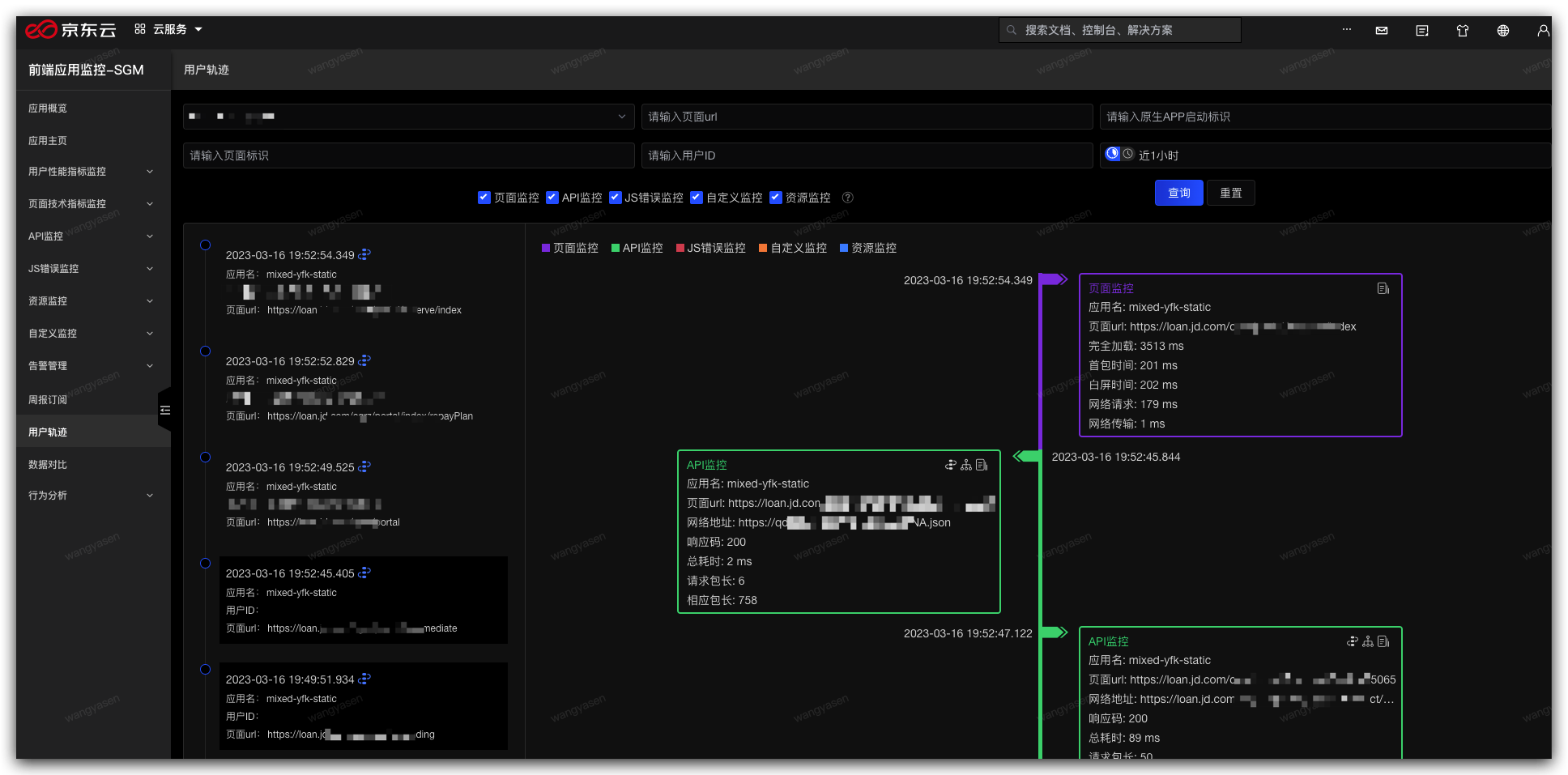
6,不管有没有发生问题我都可以还原用户的操作轨迹查找问题
7,老板说我们好久没出生产事故了
下面内容比较干,建议请提前备好茶水,一起赏用更佳
一、介绍
何为系统可观测性?
可观测性是一种系统属性,如功能性或可测试性。通过收集和分析系统的运行状态以及系统所承载的业务状态,用一种可以让人理解的形式展示出来,以供我们对系统的运行情况做出合理的判断。
我们要观测什么?
通用部分:从硬件运维(cpu, meomery, disk)与 软件应用可访问性 与 应用性能几个方面进行监控。
业务部分:从页面正常初始化,业务可交互性,交互流程完整性 方面进行监控。
我们以集团内部现有的工具进行说明如何来做,而工具实现的技术手段不在本篇文章职责之内。
二、观测指标
系统指标
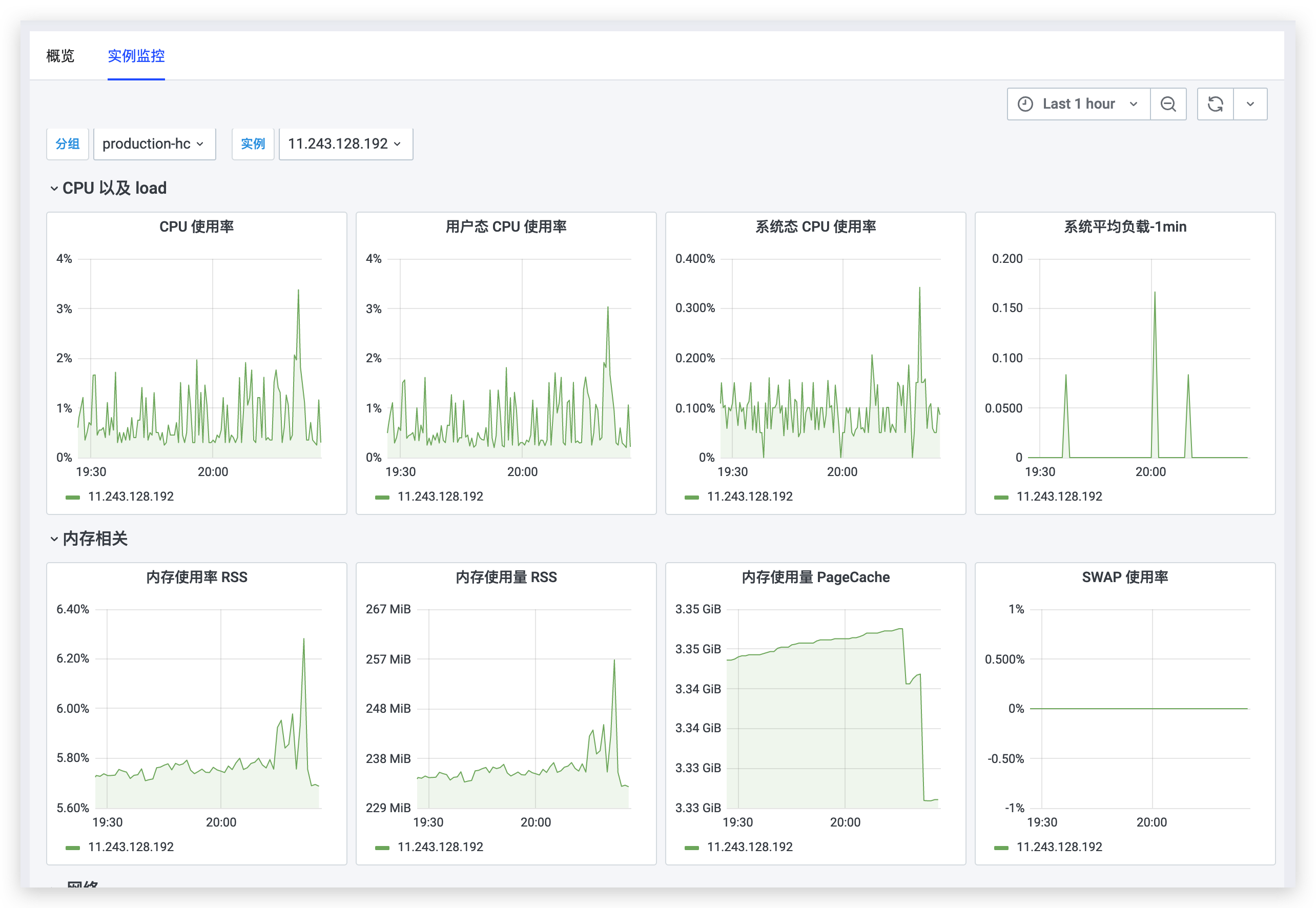
服务器运行状态
cpu 占用率
内存占用率,
硬盘 使用率
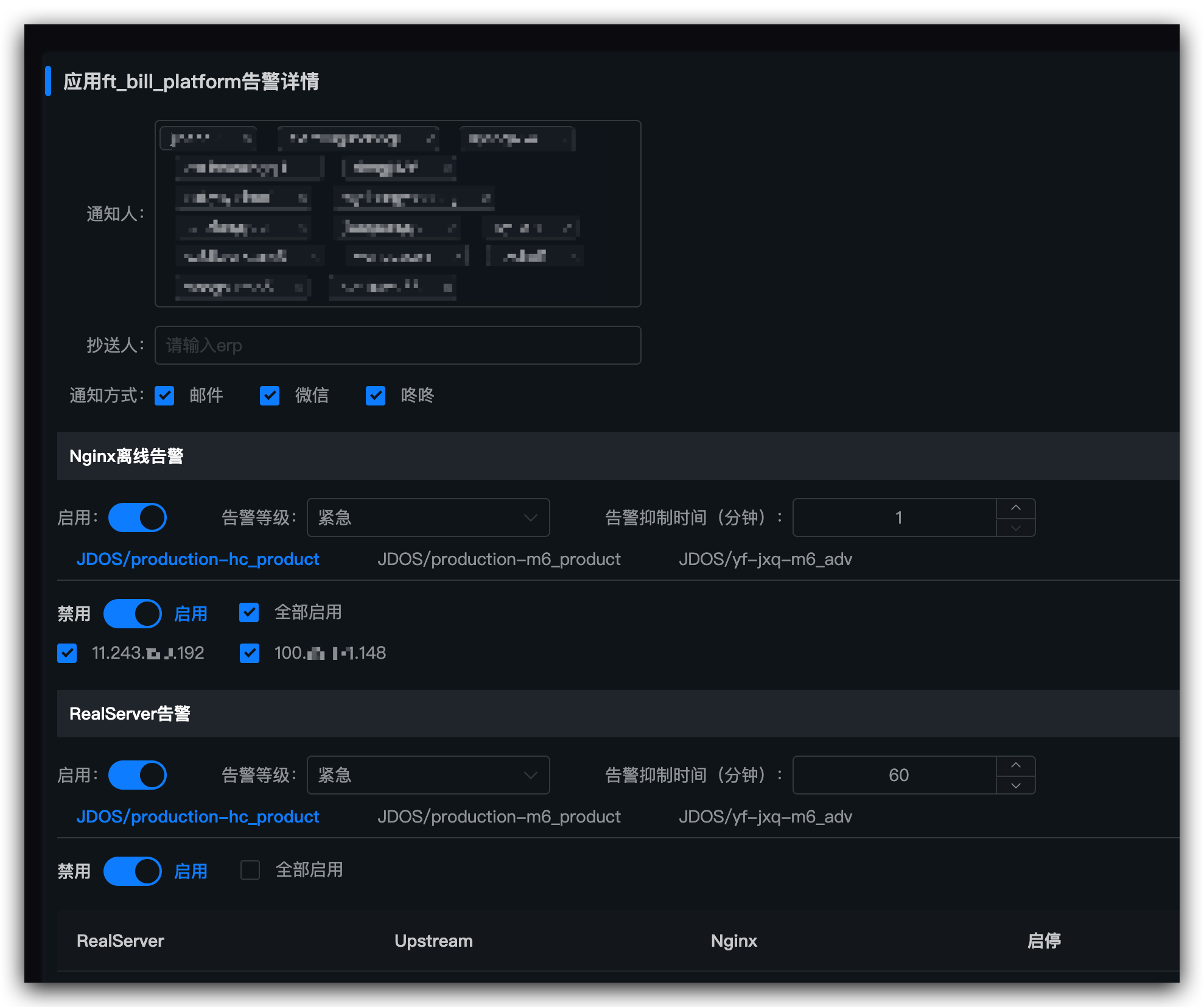
nginx 启停状态
应用指标
白屏, 因系统错误导致的白屏
资源加载错误
请求 400,500
脚本错误,导致阻塞交互
首屏渲染时间
页面完全加载耗时
接口耗时
业务指标
以信贷产品为例,整个产品的黄金流程分为三部分:授信准入,借款融资,还款。
通用部分
业务异常(999999)
掊口请求网络超时
接口请求错误
未知错误(未处理的异常码)
准入
跳转实名失败
补充信息提交失败(从用户点击提交按钮开始,未到最终提交成功)
查询地址列表异常
获取合同列表失败
合同预览失败
准入开通结果页面未在 60 秒内正常跳转至首页
资质审核页面停留时长超过 5 分钟
融资
融资申请提交失败(接口返回正常,但未进入结果页面)
融资鉴权失败
还款
还款计划试算失败
还款失败
三、如何观测
以下所有的观测工具,皆以京东内部为准,以现有的工具,提供观测方案
系统指标观测方法
通过 jdos 3.0 的智能监控系统 brolly 对系统的 cpu 占用率,内存占用率,硬盘使用率 进行监控告警
http://brolly.jdos.jd.com/app/

通过 jen 对 nginx 状态,以及服务器状态进行监控告警
应用相关指标观测方法
前端应用我们选择科技内部的 sgm 做为应用内场景上报工具,关于 sgm 的介绍与接入指引参考:sgm 接入指引
1,白屏告警
由于 sgm 中的白屏概念是指访问页面开始,到页面展示第一个字符或图片内容结果,中间用户感受到地白屏时间,如果因为发生系统错误导致无法展示内容而一直白屏,sgm 采集到的白屏时间 为 0,所以 sgm 无法监测白屏故障。
由于白屏时,页面 #app 内容为空,此时页面已经完全加载,所以可能通过监听页面 load 事件,判断 #app 内是否有内容来监控页面是否白白屏,再配上 sgm 自定义监控告警,从而达到可以有效监控白白屏故障。
window.addEventListener('load', () => {
if(document.querySelector('#app').children.length < 1){
window.__sgm__.custom({
type: 'error',
code: '系统白屏'
})
}
})
2,资源告警
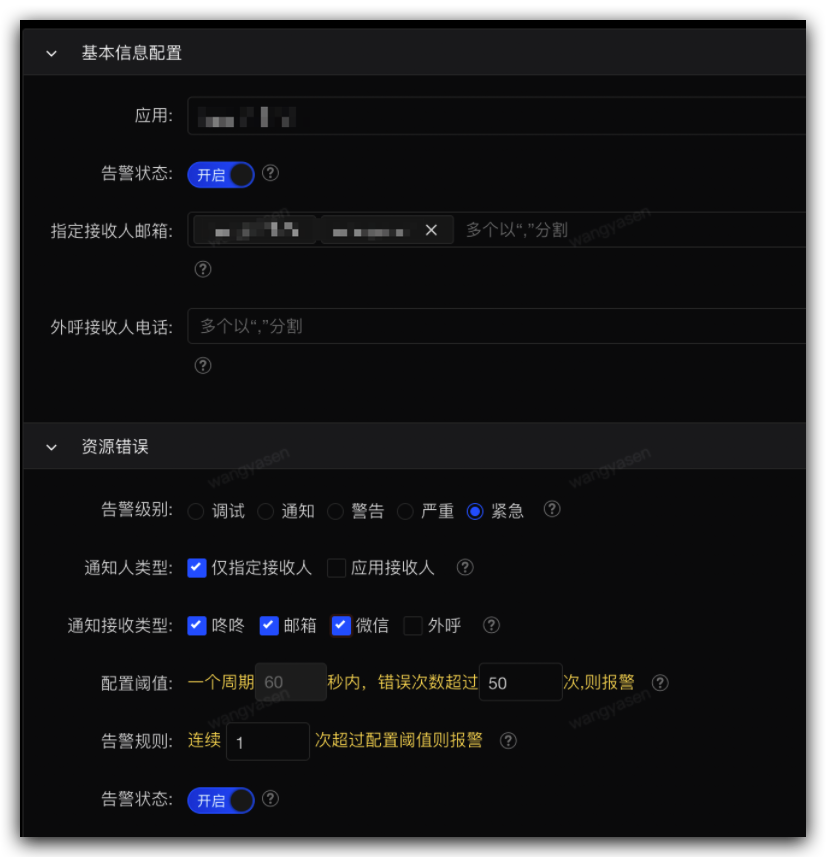
详情见:sgm 接入指引
3, API 告警
详情见:sgm 接入指引
4, js error 告警
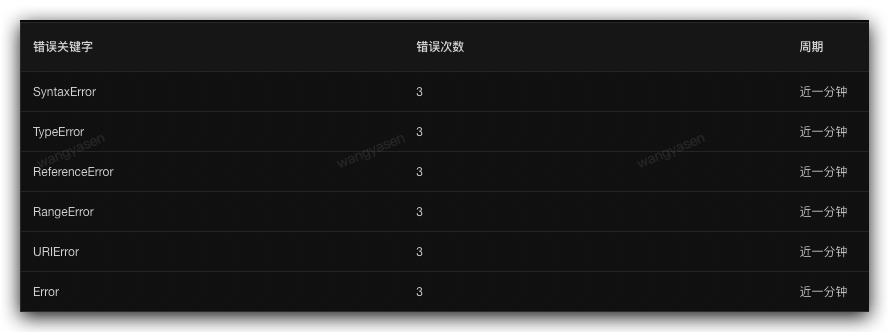
通过 sgm-web 对页面中所有的脚本错误的关键字进行监控,常见的 js 错误类型为
SyntaxError 语法错误
TypeError 类型错误
ReferenceError 引用错误
RangeError 范围错误
URIError url 解析错误
InternalError 内部错误
5,性能告警
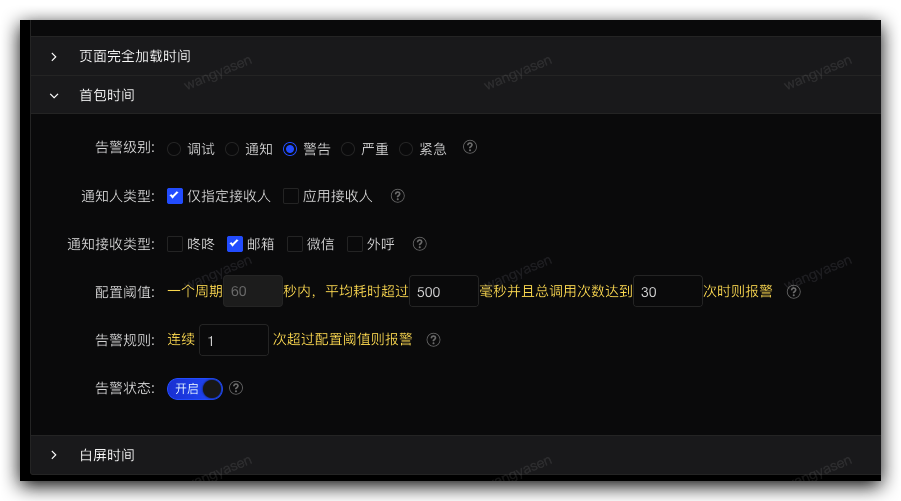
详情见:sgm 接入指引
业务指标观测方法
自定义监控告警
自定义告警是监控业务指标的最佳手段,页面提交失败,函数进入 catch 逻辑,等都可以通过自定义监控进行告警设置。
下图例子中带 Error 的编码,代表进入 catch 逻辑,需要我们关注,可以通过设置调用量的阈值,来进行告警配置
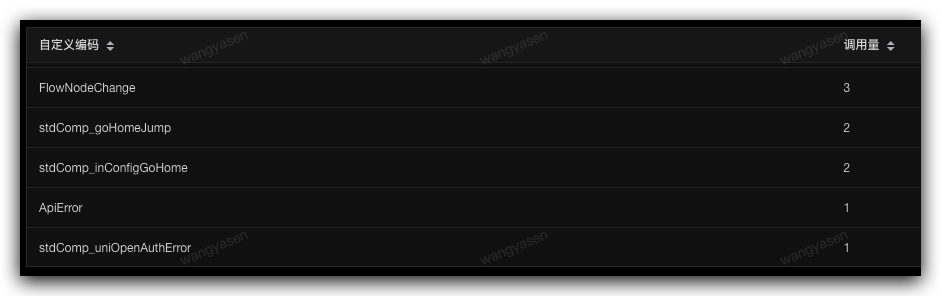
详情见:sgm 接入指引
注意事项
a,埋点上报需包含的信息
userinfo 接口返回的用户信息,以确保可以拿到用户标识,查询相关日志或者用户轨迹
当前报错接口对应的出,入参
自定义上报埋点的上下文信息,以确认出现错误的场景
b, 其中页面路由跳转失败的场景可以通过定时器的方法进行上报,在页面销毁时清除定时器、
c,sgm 上报用户标识逻辑
四、阈值优化
1,确定点位的有效性
通过本地模拟错误进行告警,以确保所有的点位可以正常上报
2,阈值设定的合理性验证
首先将所有阈值调整至最低,然后查看报警情况
如果有报警,分析报警信息的合理性,如果每次都是需要关注的生产问题,那么这里就需要设置为最低的阈值,如果是个例问题或者无须特殊关注的问题,那么把阈值逐渐调高,至合适的频率
3,Api 监控
前端可以无需特殊关注,可以设置一个 20% 错误率批量报警数值即可
4,资源监控
以页面静态资源数为准,包含 css, js, img 的总和为监控数值,其中 img 标签存在动态 src 时,页面在初次渲染会有一次当前页面 url 的资源错误上报,可通过 v-if 来避免误报
5,自定义监控
业务中的自定义错误上报 遵循第 2 条的原则进行逐渐优化
6,应用监控告警阈值配置原则:
由于 sgm 常规计算以 60 秒错误数(),为一个周期,连续发生多少()周期 ,则触发告警规则,所以我们需要计算出应用的日均 pv,以及对应指标产生的数量级,进行设置合理的阈值。
以 日均 pv 为 10000 的应用 为例,每 60s pv 约等于 7,每个 pv 资源数约为 20, 接口调用数量约为 3,那么每秒总量是 140 次资源请求,21 个接口调用 。以 20% 错误率上报为标准,来设置对应的阈值。
以上数值可以根据业务线流量视情况而定。
五、报警信息触达
1,邮件(必选)
报警方式中选择邮件,另外在邮箱中配置报警邮件规则,由于报警邮件可能会有很多包括后端的报警,以及一些非紧急报警邮件,可以通过邮件标题来进行区分。
一般标题中会包含应用名,可以通过筛选应用名来过滤前端应用,另外可以根据标题中的 [SGM-WEB] 来过滤前端相关的报警信息。
H5_RESOURCE 资源错误标题关键字
H5_CUSTOM_CODE 自定义监控关键字
H5_JS_ERROR 脚本错误关键字
2,咚咚(必选)
咚咚 报警渠道会比邮件提醒更加及时,被看到的时效性会更高
3,外呼(可选)
时效性最高的报警方法,对于一些关键场景,批量错误,可以确定是生产问题类的场景需要增加外呼方式,及时触达信息
六、生产切量监控
可以使用自定义监控来配合系统的切量功能进行监控
假如我要上线一个新的重大功能,需要在生产环境通过切量的方式,逐渐替换老版本的功能,我们如何去监控上线后新老功能
我们需具备两个功能,一个是切量功能,一个是监控功能
切量是业务系统实现的一个功能,大概流程如下:
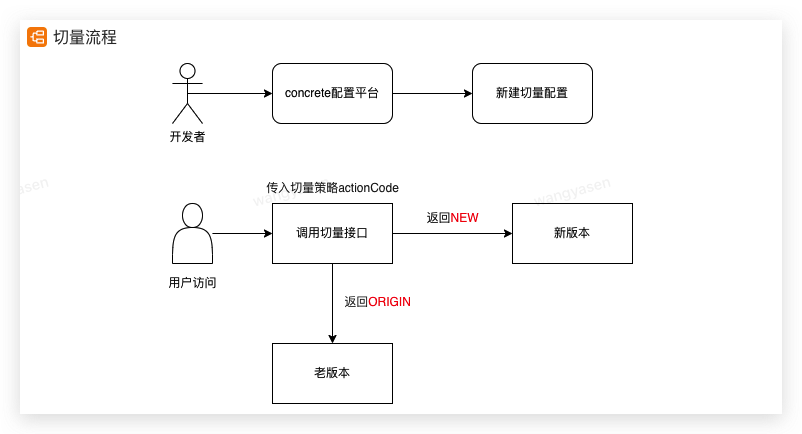
我们分别在新老版本的分支流程里通过自定义埋点来进行监控有多少用户走到了新流程,有多少老用户走到了老流程,
然后再通过 sgm 来查看两个流程的用户轨迹来判断用户是否在新流程中完成了全部操作,或者是用户卡在了哪一步,
以此来确定新上线的功能是否有问题,问题出在哪里
并且可以通过查看监控数据,来确定本次切量是否成功,是否需要及时回滚,或者修复上线,将影响范围缩小。