
移动测试开发 数据对比与处理利器——Pandas 实战
引言
在当今信息爆炸的时代,数据处理和数据分析已经成为我们工作中不可或缺的环节。作为测试人员如何保证大批量数据的准确性呢?Python 作为一门强大的编程语言,凭借其丰富的数据处理库和工具,为我们提供了极大的便利。
本文将重点介绍如何运用 Python 中的 Pandas 库进行数据对比和匹配,包括文件与数据库的对比、文件与文件的对比及对比其它库的优势。这些场景在数据管理和数据分析中经常遇到,无论是进行数据质量检查、数据集成还是数据一致性验证,让我们结合实际场景,通过具体的案例来揭示它的实际效果吧~
文件与数据库字段一致性对比
如:下面为某系统导出的 csv 文件部分数据,要验证每个字段的准确性:

为了避免经常修改代码以应对不同字段和数据库的验证需求,我们可以将数据读取和比对操作封装成一个通用类。这样,我们可以在实际工作中验证各种字段和不同数据库,而不受限于特定的字段或数据库。通过这种方式,我们能够提高代码的灵活性和可重用性如下:
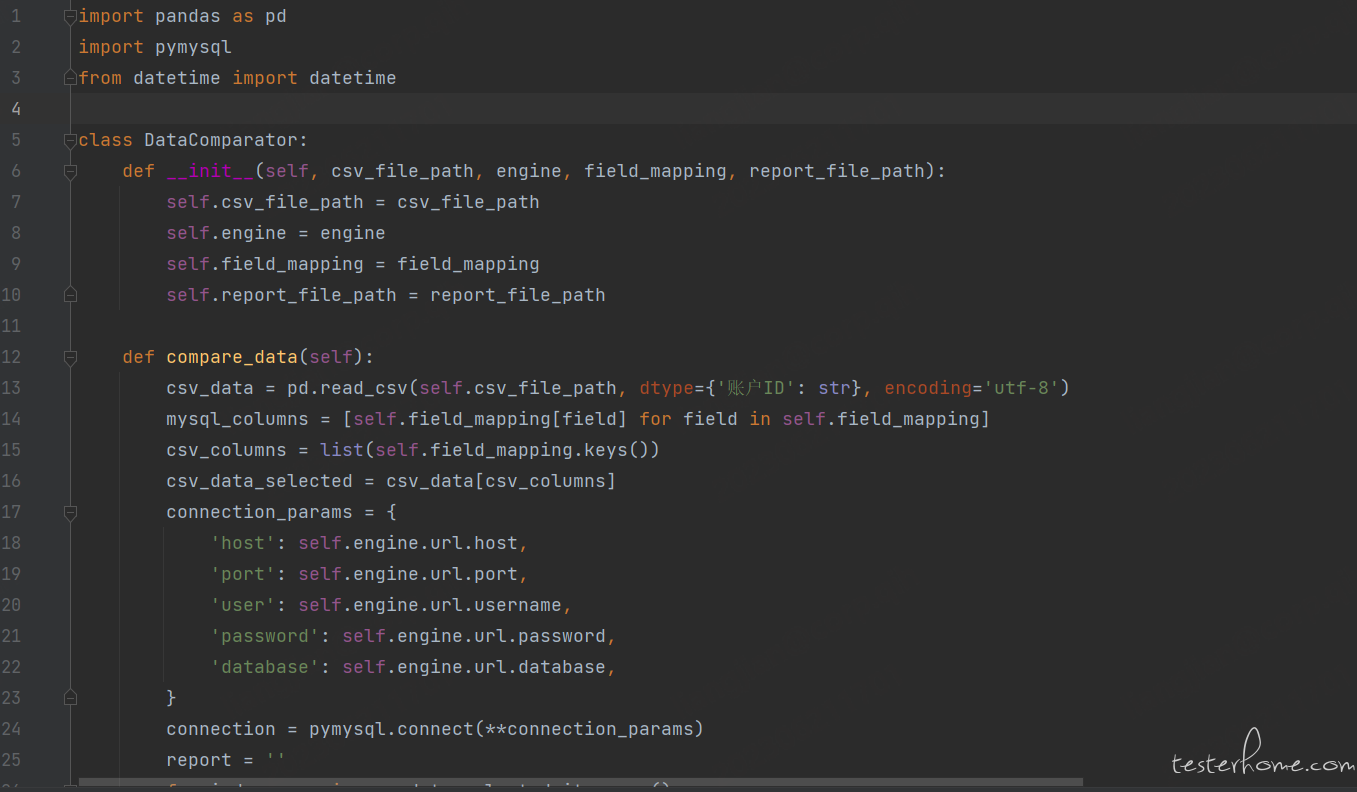
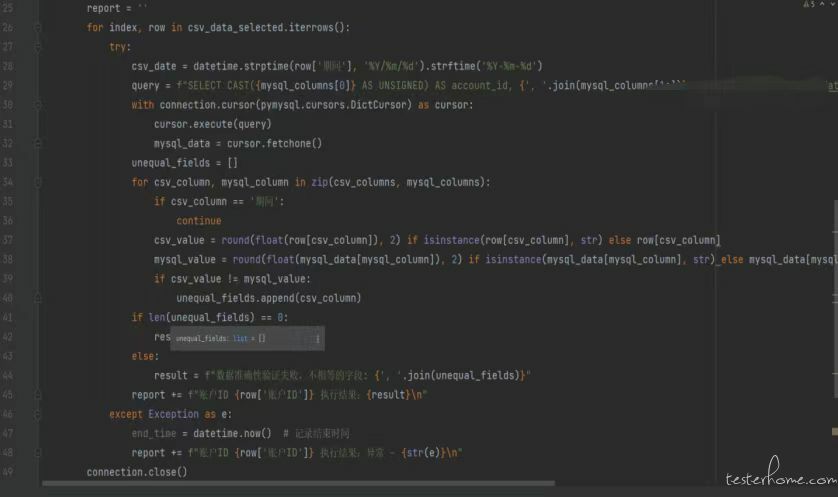
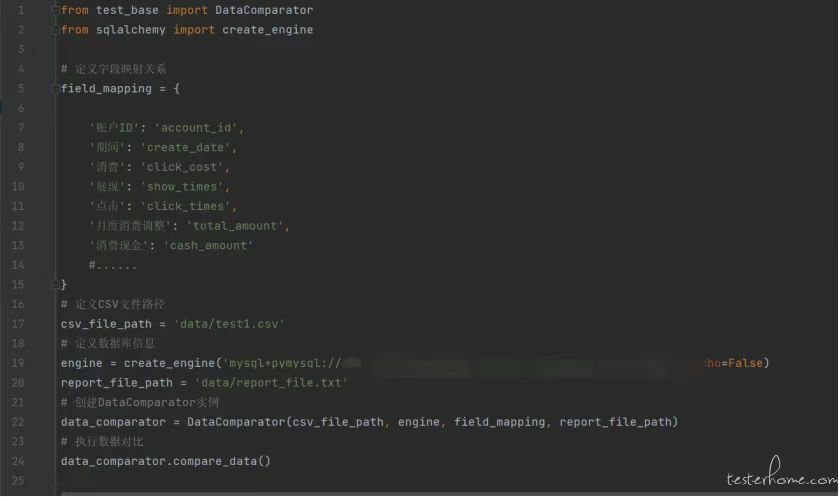
我们每次执行对比操作根据自己的需求修改一下字段的映射关系、文件路径、数据库连接就可以轻松实现文件与数据库之间的对比了
文件与文件字段一致性对比
读取 + 对比公共类:
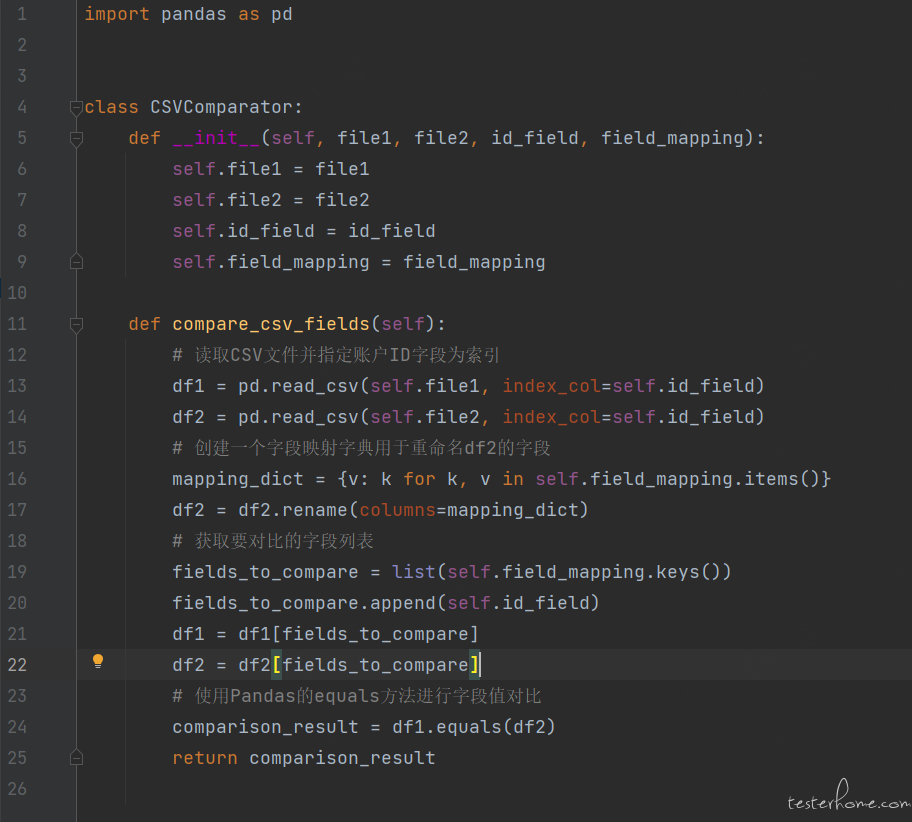
实例化对比:
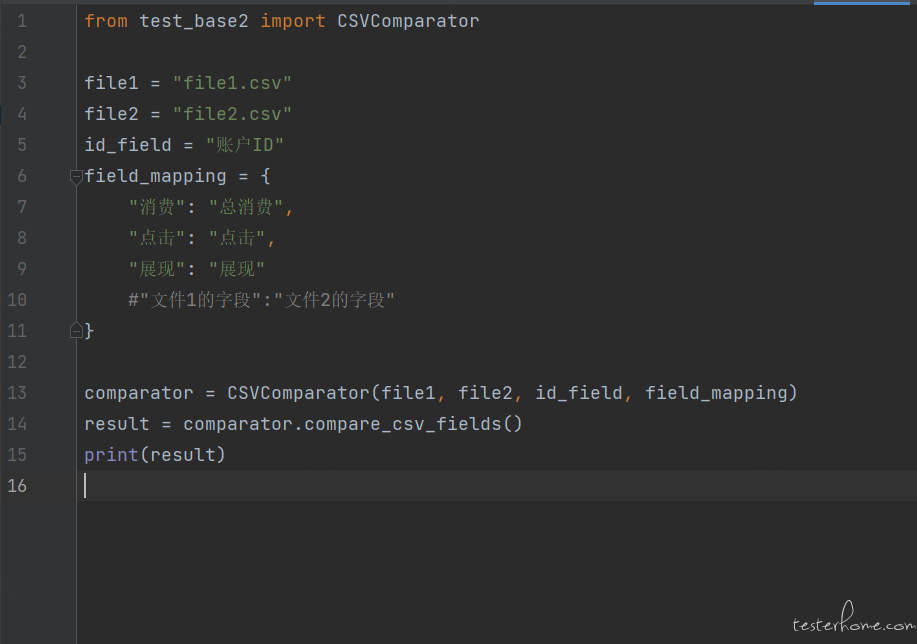
上述代码以 csv 为例加载两个文件,并将指定 “账户 ID” 字段作为索引字段。然后,它提取出要对比的字段,并使用 Pandas 的 equals() 方法对比两个 DataFrame 对象。最后,它将返回字段值对比的结果。实际工作中可能存在两个文件字段名称不一致,但是字段值的意义是相同的情况,所以我们引入了一个字段映射字典 field_mapping,它表示第一个文件中的字段名与第二个文件中对应字段名之间的映射关系。然后,我们使用 rename() 方法根据字段映射字典将第二个文件中的字段重命名。接下来,我们按照字段映射后的字段名提取要对比的字段,并进行字段值的比较。
Pandas 与其他文件处理库的特点与差异
尽管在 Python 中有许多用于数据处理的库可供选择,如 NumPy、csv、xlrd 和 openpyxl 等,但推荐使用 Pandas 的原因在于其在数据处理领域的独特优势。下面我们对比一些其他库的数据处理能力:
● NumPy:NumPy 是一个强大的数值计算库,但它主要专注于多维数组的操作,相对不太适合处理结构化数据和表格形式的数据。Pandas 构建在 NumPy 之上,并提供了更高级的数据结构和丰富的数据处理功能。
● csv 模块:Python 的 csv 模块提供了基本的 CSV 文件读写功能,但其功能相对有限,对于复杂的数据操作和转换可能需要编写更多的代码。Pandas 提供了简洁且功能强大的 API,能够更轻松地进行数据清洗、转换、分组聚合等操作。
● xlrd 和 openpyxl:这两个库主要用于读写 Excel 文件,对于处理结构化数据以及进行复杂的数据操作和分析,相对较为繁琐。Pandas 提供了更高级的数据结构(如 DataFrame)和丰富的数据处理函数,使得处理 Excel 数据更加简单和高效。
小结
综上所述,尽管可以使用其他库来实现数据处理任务,但 Pandas 凭借其丰富的功能和灵活性,成为首选库之一。它提供了简单而强大的数据结构和数据操作功能,使数据分析和处理变得更加高效和便捷。无论是处理小规模数据还是大规模数据集,Pandas 都能提供出色的性能和易用性。