
移动测试开发 QA 玩转 K8S 系列:从服务高可用分析滚动更新中可能踩的坑及 6 个 case 分析
Kubernetes(简称 k8s)是一种流行的容器编排工具,其中 Deployment 控制器提供了滚动更新(Rolling Update)的功能, 滚动更新是一种逐步替换 pod 的方式,可以无缝地将应用程序从旧版本切换到新版本。在 k8s 的滚动更新中,maxUnavailable 和 maxSurge 是两个重要的参数,它们对滚动更新过程中的服务的稳定性和更新速度具有重要影响。本文将通过实例来探讨 maxUnavailable 和 maxSurge 参数的功能和影响,以及如何正确设置它们以实现理想的滚动更新策略。
1、滚动更新原理
Deployment 是工作在 ReplicaSet 控制器之上的控制器,ReplicaSet 作为副本控制器,它来确保 pod 的副本数量维持在预设的个数。Deployment 就是通过控制不同版本的 ReplicaSet 来实现 pod 的滚动更新的。具体地,当 Deployment 需要更新新版本的应用时,它会创建一个新的 ReplicaSet,然后,逐步在这个新的 ReplicaSet 中创建 pod,同时减少旧版本 ReplicaSet 中的 pod 的数量,直到所有旧版本 pod 都被替换为止。
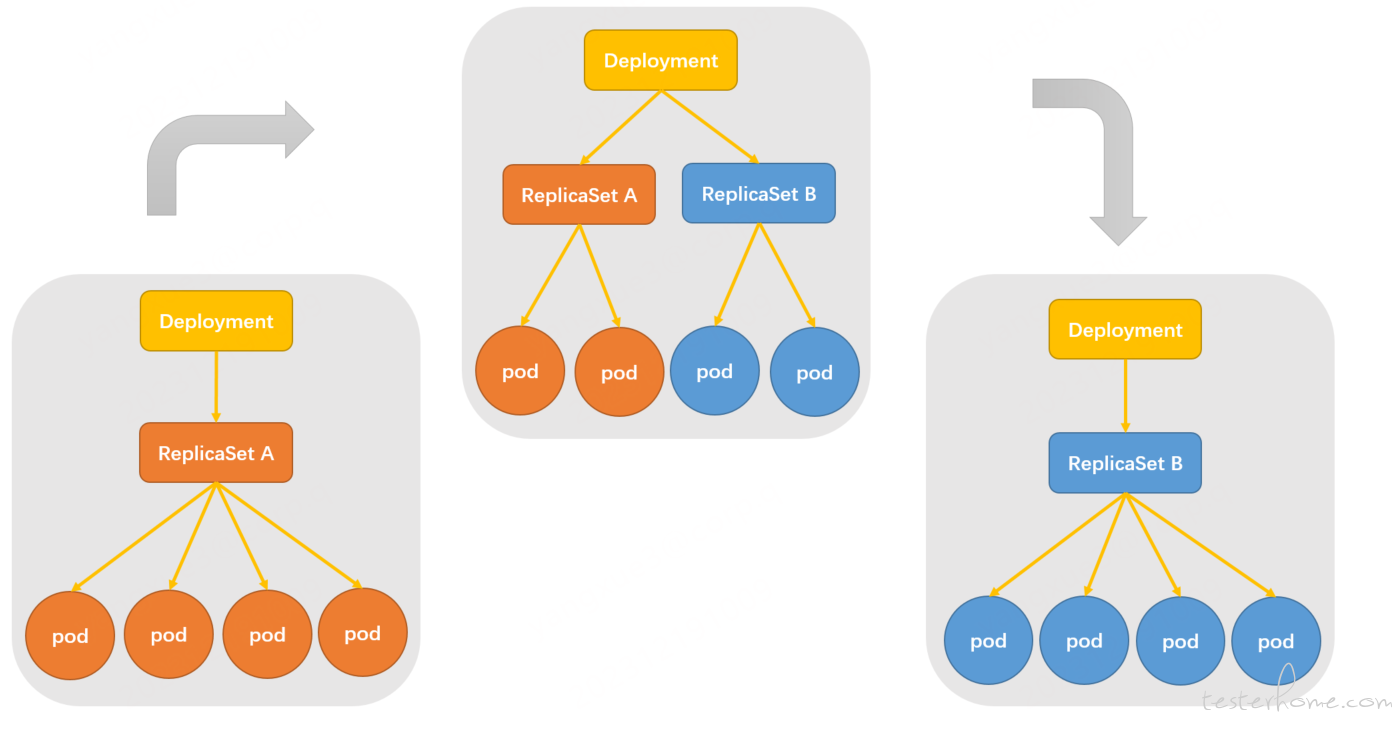
在滚动更新过程中,用户可以通过 RollingUpdateStrategy 策略来配置滚动更新过程中的参数属性,以确保滚动更新的平滑进行,其中有两个比较重要的参数:maxSurge 和 maxUnavailable。
2、参数的解释
maxUnavailable:在更新期间最大不可用 pod 数。值可以是绝对数(例如:5)也可以是预期副本数的百分比(例如:10%)。如果是百分比的话,计算最大不可用 pod 数时需要向下取整。默认为 25%。示例:当设置为 30% 时,当滚动更新开始时,旧的 ReplicaSet 可以立即缩减到所需 pod 的 70%。一旦新的 pod 准备就绪,旧的 ReplicaSet 可以进一步缩减,然后扩大新的 ReplicaSet,确保在更新期间始终可用的 pod 总数至少是所需 pod 的 70%。
maxUnavailable 翻译过来是 “最大不可用数”,参数定义了滚动更新期间允许不可用的 pod 的最大数量。在滚动更新期间,当新版本的 pod 正在部署时,旧版本的 pod 可能会不可用。通过设置 maxUnavailable 参数,可以控制不可用的 pod 数量,从而保证集群中应用程序的可用性。
maxSurge: 可以超出预期副本数进行调度的最大 pod 数。值可以是绝对数(例如:5)或是预期副本数的百分比(例如:10%)。如果是百分比的话,计算可超出预期副本数 pod 数时需要向下取整。默认为 25%。示例:当设置为 30% 时,新的 ReplicaSet 可以在滚动更新开始时立即扩展,使新旧 pod 的总数不超过所需 pod 的 130%。一旦旧 pod 被杀死,新的 ReplicaSet 可以进一步扩展,确保在更新期间任何时候运行的 pod 的总数最多为所需 pod 的 130%。
maxSurge 参数定义了滚动更新期间可以同时部署的新版本 pod 数量与当前副本数的最大差异。这意味着可以控制一下滚动更新过程中新版本 pod 的部署速度。maxSurge 的作用在于保证滚动更新过程中不会突然部署过多的新版本 pod,从而避免资源的浪费和集群的压力过大。
这两个参数使得 k8s 在更新过程中会保证:
①.Ready pod 数不低于 desired pods number - maxUnavailable;
②.所有 pod 数不多于 desired pods number + maxSurge
3、实践效果
那这两个参数的具体作用效果是怎样的呢?我们通过实际的例子看下。
Case 1
首先我们创建一个 Deployment,副本数设置为 20。滚动更新的 maxUnavailable 和 maxSurge 都采用 k8s 的默认值 25%, 通过 kubectl get rs -w 来 watch ReplicaSet 的变化,可以观测到滚动更新的过程。
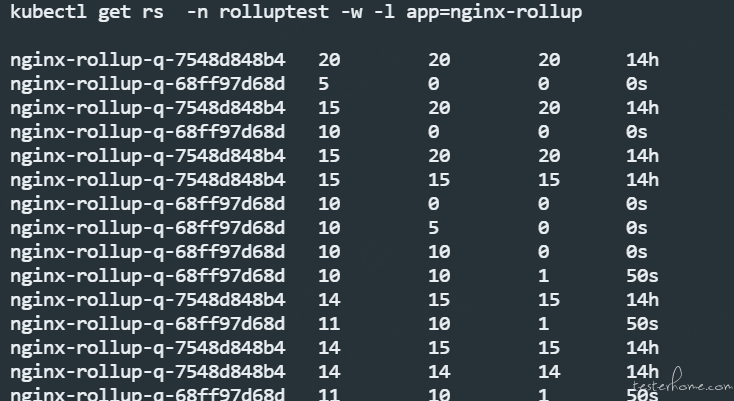
可以看到 Deployment 滚动更新实际是依靠新旧 ReplicaSet 交接棒完成的,更新过程分成两步:Scale up 和 Scale down。
Scale up 负责将新 rs 的 replicas 朝着 deployment.Spec.Replicas 指定的数据递加。
Scale down 负责将旧的 replicas 朝着 0 的目标递减。
一次完整的滚动更新需要经过很多轮 Scale up 和 Scale down 的过程。
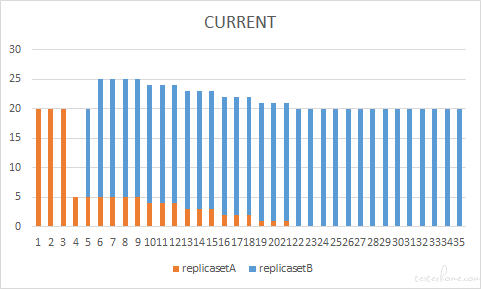
为了更直观的说明整个更新过程,我们将更新过程中新旧两个 ReplicaSet 每一步更新的期望 pod 数(DESIRED)当前 pod 数(CURRENT)和就绪 pod 数(READY)分别进行了绘制,下图给出了滚动更新过程中 pod 数量的变化情况。
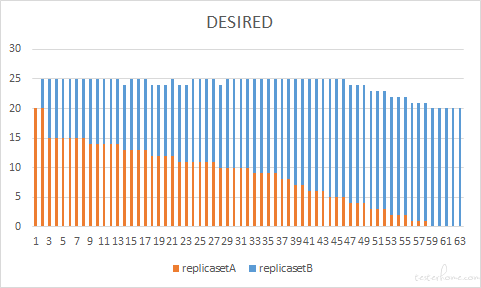
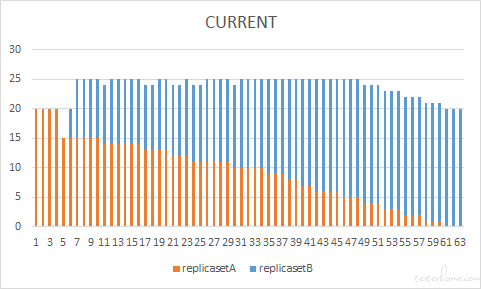
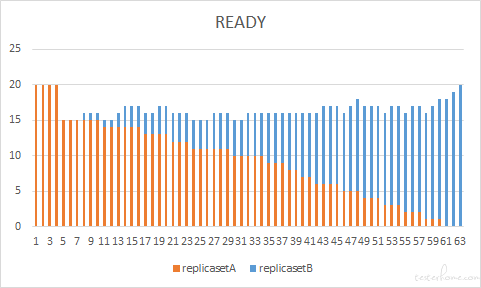
在创建过程中,最大超出副本数是 20*25%=5 个,从 CURRENT 图中,可以看到最大的 pod 数量是 25。最大不可用数量是 20*25%=5,在 READY 中可以看到,更新过程中,ready 的 pod 数最小为 20-5=15。
可以看到 maxUnavailable 参数决定了滚动更新时系统最少的可用 pod 数,这个值会影响到我们系统的稳定性,如果在滚动更新过程中 pod 数量降低,就会增加现有 pod 的负载,如果 maxUnavailable 过大,可以提供服务的 pod 数量过少,一旦性能击穿,就有可能造成服务可用性的降低。
Case 2
既然 maxUnavailable 决定了系统的稳定性,那为了保证系统稳定,这个值是不是越低越好呢?我们调整下 maxUnavailable 的参数,看看 maxUnavailable 变化会产生什么样的情况。这次我们设置 maxUnavailable =75%,maxSurge 保持 25% 不变。
可以看到当 maxUnavailable 提高后,整个滚动更新调整的步数降低了,也就是更新的速度更快了。这是因为旧版本应用 replicasetA 第一时间删除了更多的 pod,给新版本应用 replicasetB 腾出了更多的"坑位",让新版本 pod 更快的创建出来。那同样地,如果我们降低 maxUnavailable,虽然提高了系统滚动过程中可用的 pod 数量,但是会降低我们的更新速度。而在一些新老版本无法兼容的情况下,新老版本并存时会存在一定的失败率,那么更新时间久,就会导致用户体验的降低。
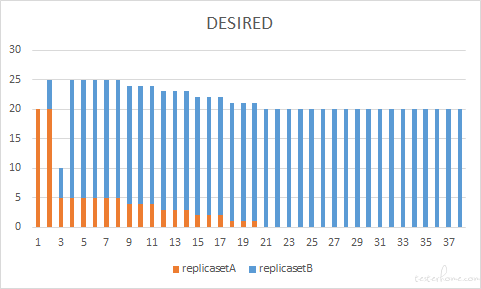
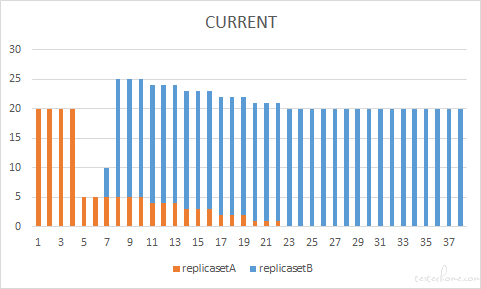
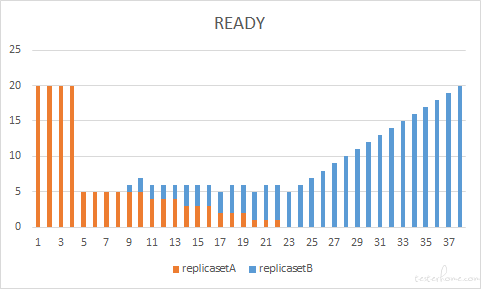
Case 3
滚动更新速度还跟 maxSurge 参数有关,在保持 maxUnavailable =25% 的情况下,我们调整 maxSurge 增到到 75%,也就是就是更新过程中最多有同时有 35 个 pod 在运行。可以看到当我们提高 maxSurge 之后,第一时间并行申请创建的新版本服务(replicasetB)的 pod 数量增加了,也就能更快地获得更多 ready 的 pod,进而促进旧版本 pod 的释放,加快了整体上 pod 替换的速度。但是,这种方式也有它的 “副作用”,我们看到更新过程中同时运行的 pod 数量增加到了 35 个,那也就是说我们在集群当中需要更多的资源来创建 pod。当集群资源有限的情况下,虽然我们在第一时间申请创建了更多的新版本的 pod,但是并不意味这这些 pod 能快速进入 ready 状态,此时即便调大 maxSurge,也不会增加更新的速度。
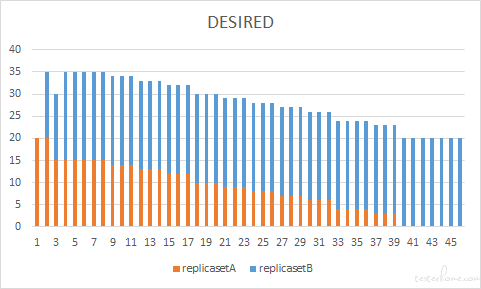
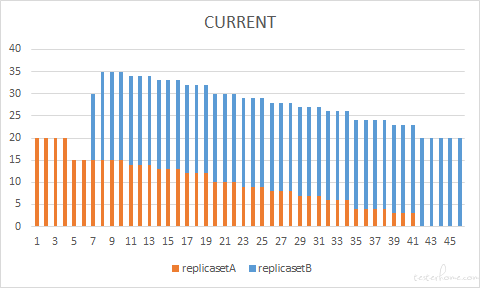
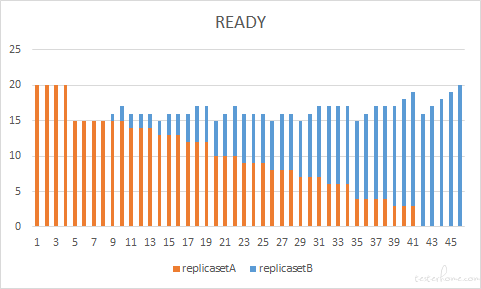
Case 4
我们再看一种情况,这次我们将 maxUnavailable 和 maxSurge 都调大到 75%,maxUnavailable 增大旧版 pod 释放的速度,maxSurge 增大新版 pod 创建的速度,那两者同时增大会不会带来 pod 快速、稳定更新的这种双赢的结果呢?怎么样?结果出乎在意料之外又在情理之中。从图中我们看到,同时调大两个参数,并没有实现新 pod 快速替换旧 pod 的预期。因为 replicasetB 在动态调整的过程中,desired 的值最大也就是咱们设置的新版本的副本数了。我们设置了 maxSurge=75% 能容纳 35 个 pod,而 maxUnavailable 快速释放出 15 个 pod 旧,那么给新 pod 的坑位就有 30 个之多,但是新 pod 最多也就能创建 20 个,所以 maxSurge 起到加快新 pod 创建速度的作用就会被限制。我们可以简单的分析出,当 maxUnavailable + maxSurge > 期望的副本数 时,maxSurge 加快发布速度的作用就被限制了,实际发布效果上来看,此时的效果和 maxSurge = 副本数- maxUnavailable 的实际效果会比较类似。
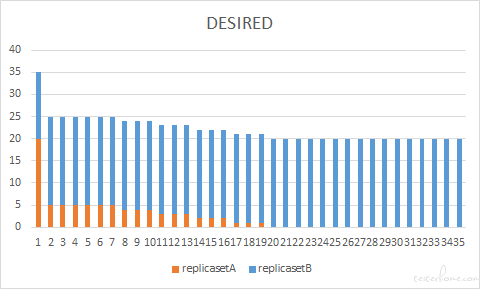

还有需要注意的,maxSurgeS 和 maxUnavailable 不能同时为 0,其实很好理解,这种情况下相当于既不给新 pod 申请额外的坑位,又不给新 pod 腾挪坑位,导致滚动更新无法实现。
通过上面 4 个实例,我们总结出:
maxUnavailable 控制更新过程 ready 的 pod 数大于 预期副本数 - maxUnavailable,决定第一时间旧 pod 释放多少,调大 maxUnavailable,可以给新 pod“腾出” 更多的坑位,来加快新旧版本更新,是一种先下后上的方案。需要关注的是,要实现评估当达到最小 pod 数时系统是否能扛得住系统的压力,防止性能击穿带来的服务不可用。
maxSurge 控制更新过程中 pod 的整体数量的最大值,包括创建中和创建成功各种状态的 pod。调大 maxSurge,可以给新 pod“申请” 更多的坑位,来加快新旧版本的更新,是一种先上后下的方案。这种方案看似快速稳定,但是会给集群带来额外的压力,同时效果也受集群资源限制,如果在集群整体资源多项目共用或者集群资源情况不可见的情况下,还是建议降低 maxS,考虑通过调整 maxUnavailable 来实现快速更新。
我们实验了新旧版本副本数相同时的更新情况,如果新版本和旧版本的副本数不同,也就是在更新过程中还包含了扩缩容,这种情况下有哪些值得注意的情况呢?
Case 5
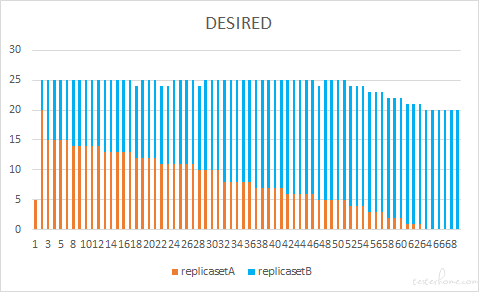
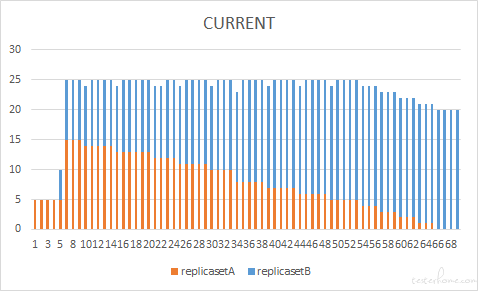
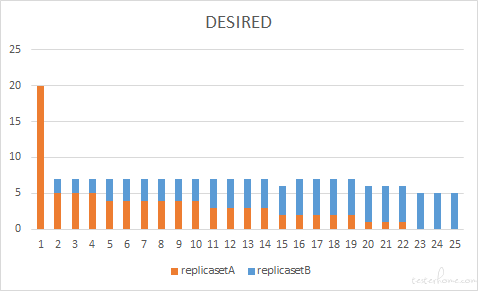
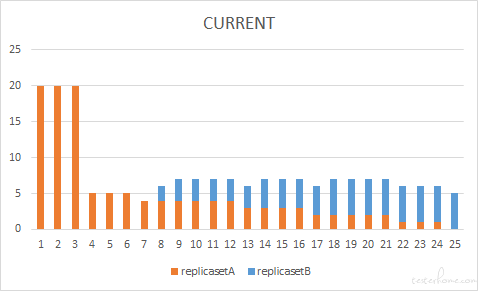
先创建一个 5 副本的应用,然后我们把它滚动更新到 20 副本的新版本中,maxUnavailable 和 maxSurge 都采用默认值 25%。此时的最大不可用 pod 数需要用新版本应用的副本数来计算,结果为 20*25%=5 个,那在更新开始时,是不是就会对 replicasetA 进行缩容,从 5 个旧 pod 中删除全部 5 个旧 pod,导致服务不可用呢?
从实际结果上来看,并不是这个样子,而是先将旧版本应用 replicasetA 进行扩容,扩容的预期 = 最终的副本数 = 20 ,那么新版本 replicasetB 的副本数是 20 * 125% - 20 = 5 个。
从 Deployment Controller 核心逻辑 syncDeployment 函数中也可以看到,deployment 会先判断是否需要 scale 再去进行 RollingUpdate,也就是扩缩容的优先级要高于更新操作。
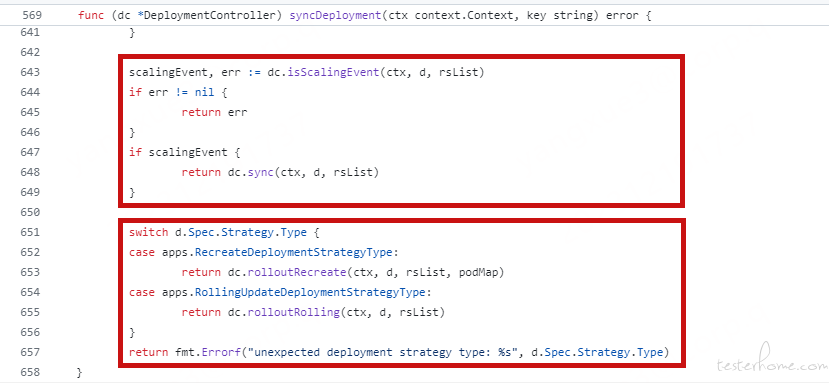
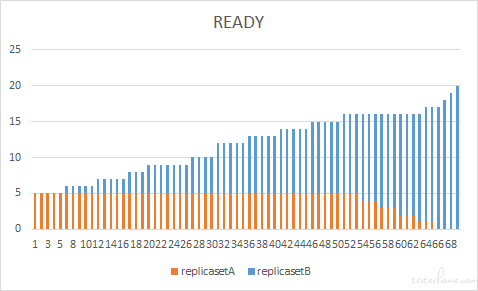
当我们理解 maxUnavailable 参数时,不妨直接把它转化为最小可用副本数进行设置,集群最小可用副本数 = 最终副本数 - 最大不可用 pod 数,以此来判断集群是否会因为 pod 过少而出现服务中断。在实际的代码实现中,也是先计算 minAvailable 在决定缩容多少 pod 的。

Case 6
反过来有另外一个例子,我们希望调大单 pod 的资源配额降低 pod 数量,来达到降低限流比的目的。那是否可以在一次滚动更新中实现呢?我们先建一个 20 个副本的应用,然后把它滚动更新到 5 副本的新版本中,maxSurge 和 maxUnavailable 都采用默认值 25%,此时集群最小可用副本数 = 5 - (5*25%) = 4。在滚动更新时就会直接从 replicasetA 中删除 16 个 pod,此时大量释放旧 pod 可能会给服务稳定性带来较大的影响。所以此时在一次滚动更新中同时进行资源配额增加和副本数降低两种操作时,一定要注意更新过程中最大不可用 pod 数的影响。也可以先通过滚动更新修改资源配额,然后再通过缩容来降低副本数。

4、总结:
正确的设置 maxunavailable 和 maxSurge 参数可以实现平滑的滚动更新,确保应用程序的可用性和可靠性。下面是一些最佳实践:
a. 在滚动更新之前,建议先进行适当的测试和评估,以更好地理解应用程序的性能和需求,从而合理设置 maxunavailable 和 maxSurge 参数。
b. 在应用程序的高峰期,可以适当降低 maxUnavailable 的值,以减少滚动更新过程中的不可用性。
c. 为了避免资源的浪费,建议将 maxSurge 设置为较小的值,以确保滚动更新过程中不会产生过多的新版本 Pod,从而减少对集群资源的压力。
d. 定期监控滚动更新过程中的性能和结果,及时调整 maxUnavailable 和 maxSurge 参数,以达到最佳的滚动更新策略。
滚动更新是 k8s 中的一个重要功能,而 maxUnavailable 和 maxSurge 是影响滚动更新过程的关键参数。通过本文的介绍和实践,希望读者能充分理解和正确设置这两个参数,通过合理设置这两个参数,实现平滑的滚动更新过程,避免不必要的不可用性和资源浪费。在实践中,需要根据具体的应用程序需求和资源环境来优化这些参数,持续的监控和调整,将有助于优化应用程序的性能和资源利用率,提高整体的系统可靠性和稳定性。