
移动测试开发 使用大模型快速构建测试工具的入门级实践
背景
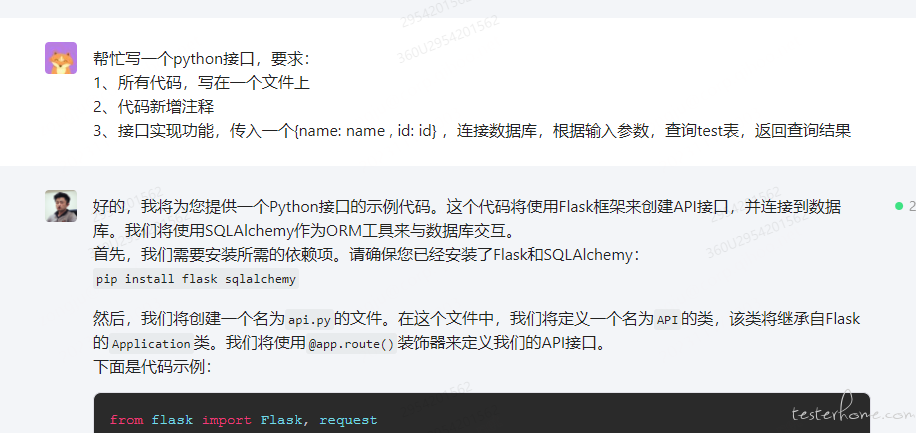
在我们的测试工作中,经常出现我们给其他部门的测试同学提供测试数据的场景,很多测试数据无法从页面直接创建,有的是调接口传参实现,有的是通过数据库导入,其他测试人员经常是客户端测试或者硬件测试,他们对接口工具和数据库的基础操作不熟悉,而且有的接口有签名算法的校验,不能直接把算法暴露给对方,有的数据库需要申请权限,对方无法直接连接。这种情况下就需要我们写一个简单的测试工具提供给对方。
实现这个工具有几点要求:
1.内部使用,不需要做鉴权等操作,功能简单
2.功能简单,往往只是调用接口,或者对数据库进行简单的增删改查操作,需要 web 页面,便于操作
3.需要时间比较紧,需要快速实现
首先这种测试工具都是临时用的,用于暂时的项目对接,具有时效性。需要尽快完成,如果通过新建前后端服务的常规方式实现,需要面对技术选型,新建仓库,前后端开发,部署等一系列步骤,很费事。为了节省更多的时间,我首先想到了使用各种工具,减少代码调试的时间和部署的时间。
一、纯前端的测试工具(调用接口类)
比如最常见的接口类工具,一个简单的需求,提供一个 web 页面,在页面上调用接口(签名算法不能暴露,不能直接提供 postman 文件),展示返回调用的数据。
首先针对前端,html,css, js,很长时间不用,其中很多方法都忘了,再次熟悉很耗时,首先我尝试使用低代码平台来生成页面,现在各种低代码平台比较多,使用过后我发现三个问题:
1.低代码平台大部分通过拖拽组件生成页面,而且生成的页面没有注释,调整生成的代码比较麻烦:
2.低代码平台很多都有使用限制,很多功能需要付费使用:
3.在使用过程中会遇到很多未知的问题,查询&上网搜解决办法比较麻烦。很耗时
总之不能真正起到节省时间的作用:
后来我改用大模型来生成前端页面,发现使用体验很好,只要我们通过合理的方式来描述我们的需求,就可以获得带着注释的前端代码,稍微修改即可使用。不过使用大模型生成代码时,也需要一定的技巧。
市场上的大模型很多,判断一个大模型的好坏重要的指标是精准度和速度,好的大模型生成的代码又快又好。本次我们选择使用 360 智脑来进行功能演示,在之前公众号推送的文章中,我们知道了,使用大模型的关键在于提升我们提出的 prompt(提示词)的技巧。
引用公众号文章《未来竞争力——ChatGPT 之 “会写 Prompt” 亲体验》

1.首先使用角色 + 任务 + 指令,来让大模型扮演角色。
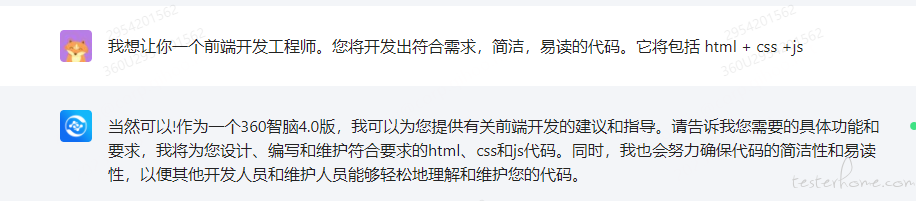
2.描述自己的需求:生成一个 html 页面,注意,要渐进式,引导式的提出自己的需求,并且分条清晰描述。说明生成的页面里面有哪些元素。如果生成的不符合需求,可以让大模型重新生成
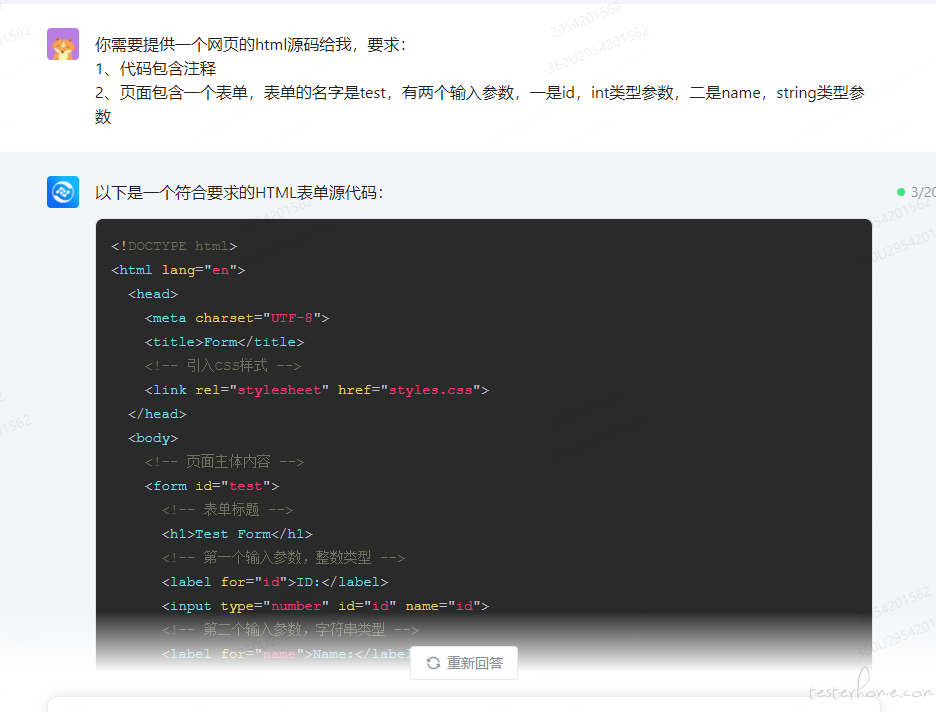
3.引导智脑,给以生成的代码加入样式,需要注意的点,我们使用 Bootstrap 的组件,不要使用 antd-design、element-ui 等组件,因为这些组件太过复杂,而且没有必要,Bootstrap 已经够用了。使用那些之后增加复杂度,而且还需要新增 npm_modules,增加部署的复杂度。
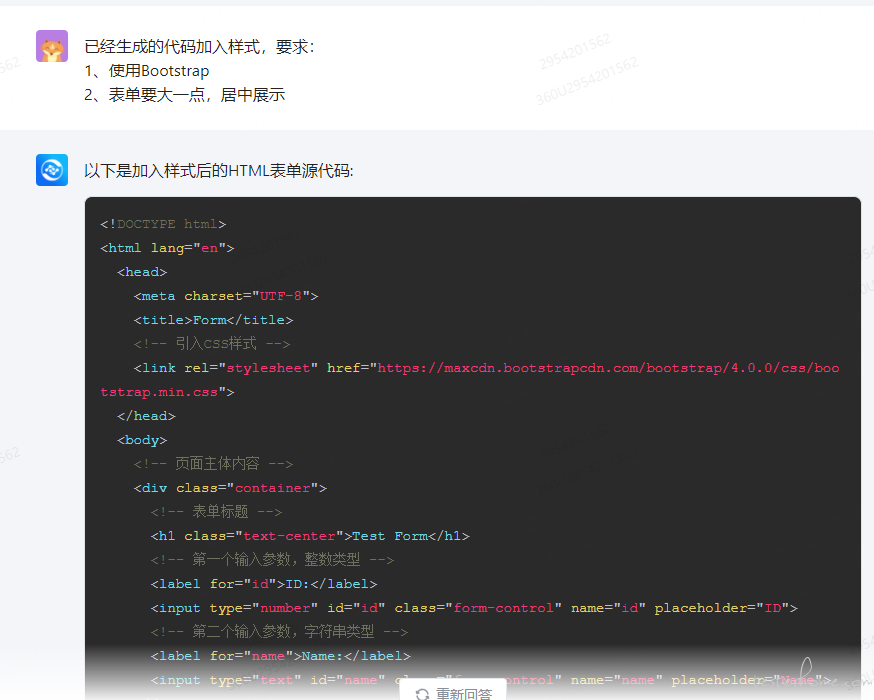
4.加入事件要求,点击表单提交按钮,请求目标接口
注意:
●生成代码的时候,需要增加注释,便于简单调整,代码生成完毕之后,可以简单的 code review 下,发现有生成的不完整,不符合预期时,重新生成
●在提问的时候,一步一步的描述自己的需求,提问期间如果想问其他的问题,可以另开一个。
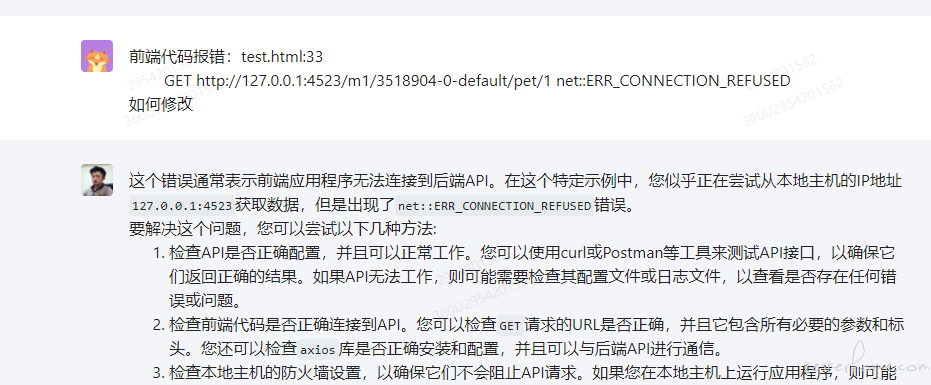
如果生成的代码有报错,可以复制报错信息发送给大模型,让大模型给出修改建议,我们可以按照它给的建议去排查(如:我本地的接口不能正常访问),如下图:
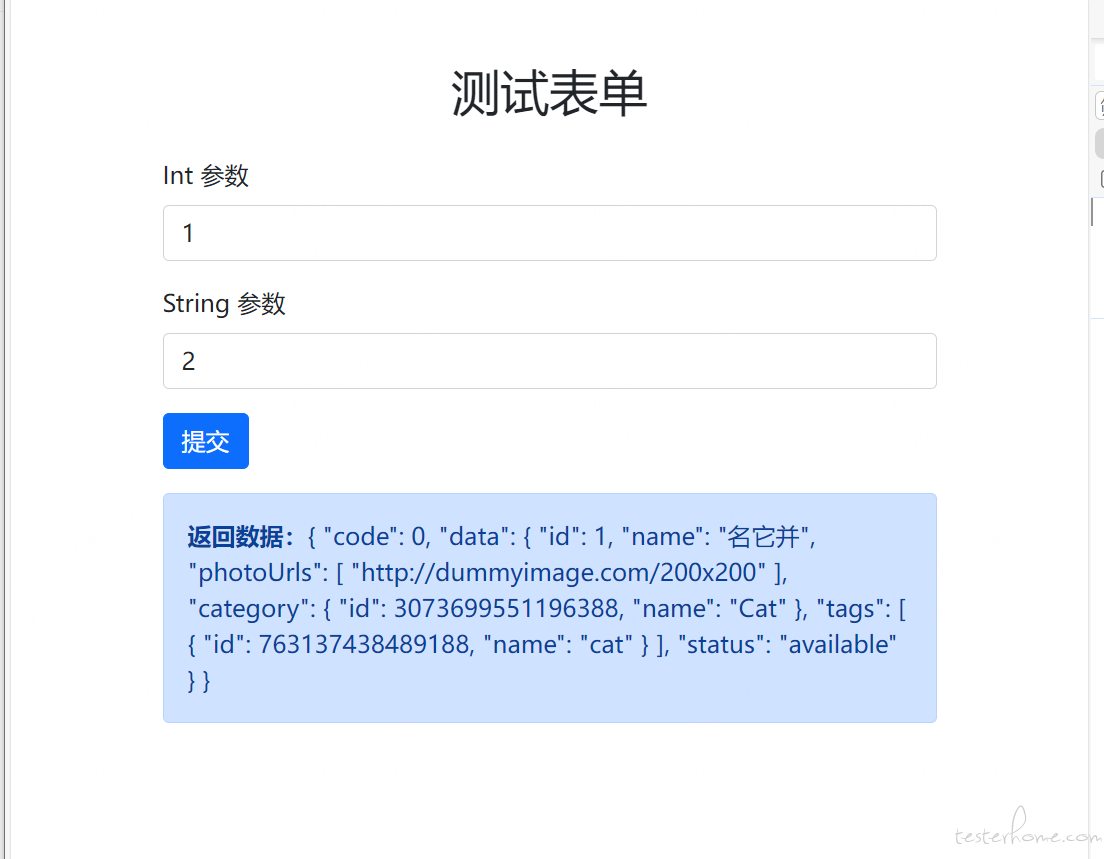
5.展示完成的效果:
经过上面的引导,我们直接可以生成一个页面,可以通过简单的 nginx 代理,让对接的同时使用这个页面,真的是很方便。最后的构建完成的简单页面效果如下图;
二、后端(比如在数据库插数据)
操作数据库无法通过前端页面完成,需要我们实现一个接口,前端页面通过表单的方式调用接口,传递数据,后端接口同样可以使用大模型来生成。可以免去我们查文档,调试代码的时间,让我们把更多的精力集中于业务。
可以选择熟悉的语言和框架,比如 python 的 flask 框架,来生成接口,描述清楚接口的入参,出参,请求方式,接口功能。一步一步的生成。
使用大模型生成后端代码,我们还应该按照之前提问前端的方式提问。还是以使用角色 + 任务 + 指令的方式,来让大模型扮演一个后端工程师的角色(也可以让他扮演一个全栈工程师),这里推荐 360 智脑的数字人功能,点击首页的数字人广场,可以选择多种数字人,让 AI 直接扮演不同的角色,效率上会减少了我们创建 prompt 的时间。
择全栈程序员

输入我们的需求,还是一步一步的提问,如下图:
注意:
1.在完成后端代码时,不能把敏感的信息输入大模型,比如 数据库的链接地址,服务的密钥,系统的账号&密码。这又会有泄密的风险
2.因为我们要减少部署和调整代码的时间,所有要选择尽量简单的框架,尽量让大模型使用一个文件完成我们的需求。
3.尽量让大模型使用主流的类库或者依赖包,主流的类库互联网上相关资料比较多,生成的代码比较准
复制代码粘贴到我们本地执行,有不小的概率会出现报错,我们可以粘贴报错日志到大模型中让它修改,大模型会给出修改建议。
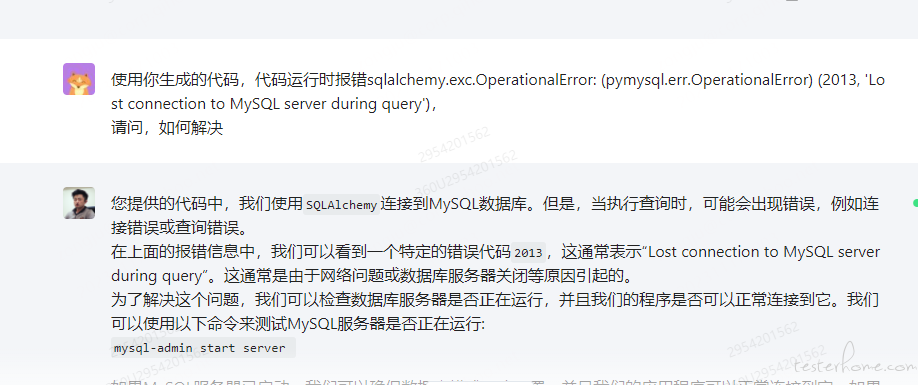
调试完毕后,代码可以正常运行,后端代码和前端代码不一样,前端代码直接生成一个 html 文件,点击即可使用,后端代码需要进行部署,我们可以通过询问大模型来知道部署方式,
注意:
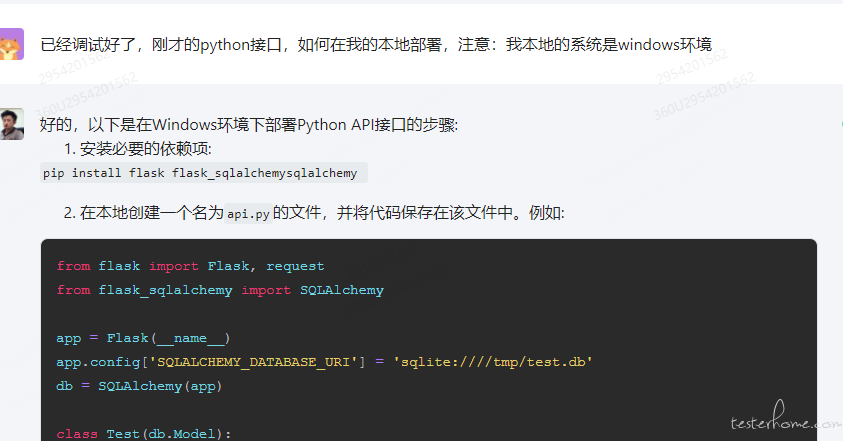
1.因为都是简单的、临时的需求,所以代码可以直接部署在本地
2.需要和大模型说明部署的环境,Windows 和 Linux 可能有些不一样
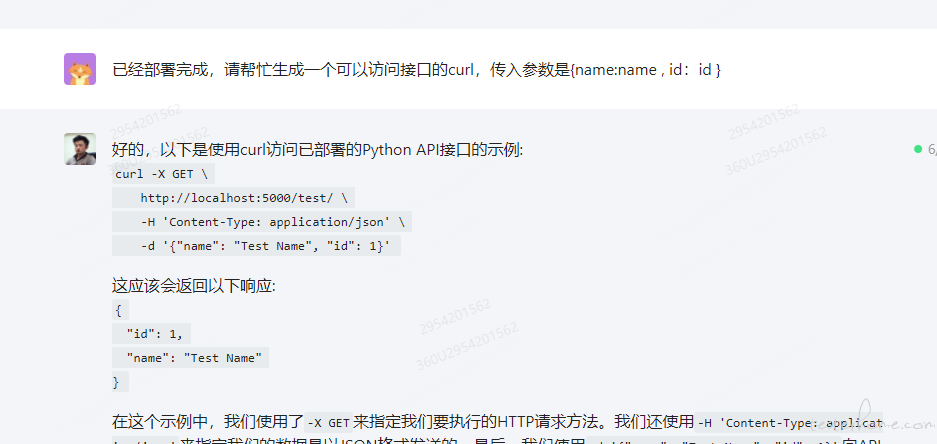
按照大模型给出的提示,部署完成后,还需要我们简单的进行下测试,看看代码是否部署成功。可以让大模型帮我们生成一个访问接口的 curl ,我们在本地的终端调用下,看看接口是否已经正常工作。
再啰嗦一下,做个总结:
本次实践主要是通过大模型来完成一些测试工作中基础的测试工具开发工作,包括开发简单的 web 页面,简单的接口。如何快速高效的完成这些测试工具的开发? 关键在于挑选好用的大模型产品 (比如 360 智脑),并且按照一定技巧的方式提出 prompt,需要提前准备好清晰、具体、聚焦、简洁的 prompt,并按照顺序逐步提出。大模型就会把我们想要的代码提供给我们。
此次实践帮我解决了效率不高的问题,之前实现这些需要我去手动完成,而且部分语法函数很久不用要经过查询进行回顾,需再次的学习掌握才可正确的加以使用,整个过程费时费力,使用大模型可以帮助我减少开发时间,更加专注于业务逻辑的测试。
实践后,我的感受是:大模型的技术非常厉害,可以在工作中帮助我们提升工作效率,比如:像本次实践一样,使用大模型生成代码,还可以使用大模型帮助我们进行技术选型,bug 查找,生成代码的注释,生成测试用例,提炼测试要点……,而且对于大模型的应用还在不断探索,前几天的 openAI 开发者大会,openAI 推出了 gpt 商店,在未来我们可以在工作生活中 0 代码实现各种功能,极大的提升我们的效率。我们应该在日常的工作中积累使用大模型的经验,不断提升自己的能力,应对未来技术的变革。