背景
群接龙小程序有各种针对社群开发的活动,轻量应用,使用简单。它可以有针对各类社群开发社群主页,帮助用户轻松经营好社群。特别在社区/社群团购领域,群接龙是最有影响力的产品之一。
目前,群接龙小程序用户数量已经达 1.8 亿 +,并且小程序的功能每周都在迭代更新,为保证用户的体验质量,我们需要在每次发版前,对上传的体验版进行回归,依赖手动回归并不现实,因此我们选择使用 Minium + 云测 ,来实现小程序自动化,提高回归效率,保障产品质量。
技术方案
整体的方案实现流程如下图所示,主要使用 Python+Minium+ 云测 编写测试用例,最后将测试报告发送到企微

代码示例已放在了 Git 上,大家可以自行下载。地址:https://git.weixin.qq.com/minitest_best_practices/qunjielong
1、框架介绍
-
base:封装页面公共方法和测试基类的封装
- basedef.py 中封装了一些 minium 框架的方法,如页面跳转,点击元素,文本输入方法等,可以根据自己的需求进行封装
- basepage.py 是测试用例的基类,这里可以封装一些用例执行之前的操作
-
common:存放公共方法,如读取脚本
- read_script.py:读取自动化脚本中的元素和页面路径,打印元素和创建页面
data:存放一些测试数据
page:生成的页面路径,维护各页面的元素和操作方法
script:通过开发者工具录制导出的自动化脚本
testcase:测试用例
-
tools:存放工具方法
- cloud_test_output.py,用于创建云测测试任务,并将测试报告发送到企微,主要参考了云测第三方接口文档,注意需要将一下代码中的 token、group_en_id、test_plan_id、企微机器人路径替换成自己的
2、通过一个例子学会如何编写自动化用例
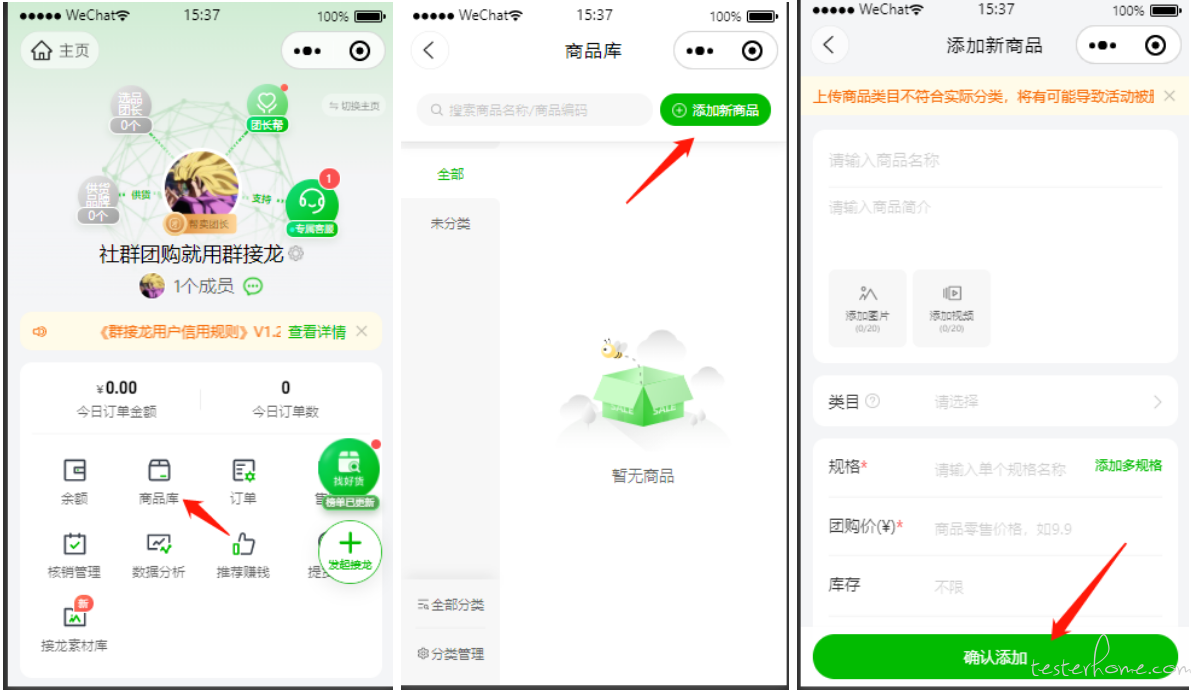
我们通过群接龙小程序中,从主页进入商品库中添加商品的用例,来介绍整个用例编写流程。
操作路径:*点击商品库 → 添加商品 → 确认添加 *
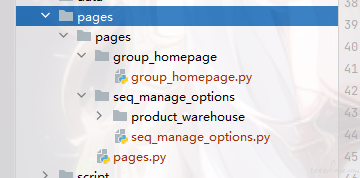
首先编写 页面类 ,每个页面只做当前页面的操作(点击对应 py 文件链接即可访问代码):
主页: group_homepage.py
商品库页:seg_manage_options.py
商品创建页:product_setting.py
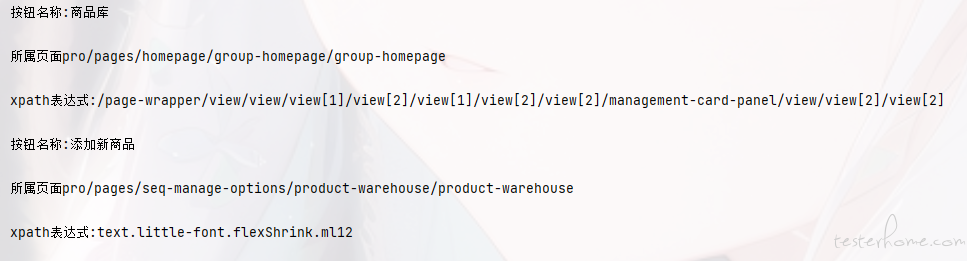
这里有个关键点,就是如何定位操作的元素,比如商品库按钮,这里可以参考本文后面章节《利用录制回放辅助定位元素》。
然后开始编写测试用例,注意测试用例需要 test_xx 开头,不然读取不到用例。这里代码可参考 creat_goods.py
到此,我们就完成了一个自动化用例的编写,是不是很简单!
3、云测执行,生成报告
小程序云测使用可以见 官方文档 自定义测试 | 微信开放文档。
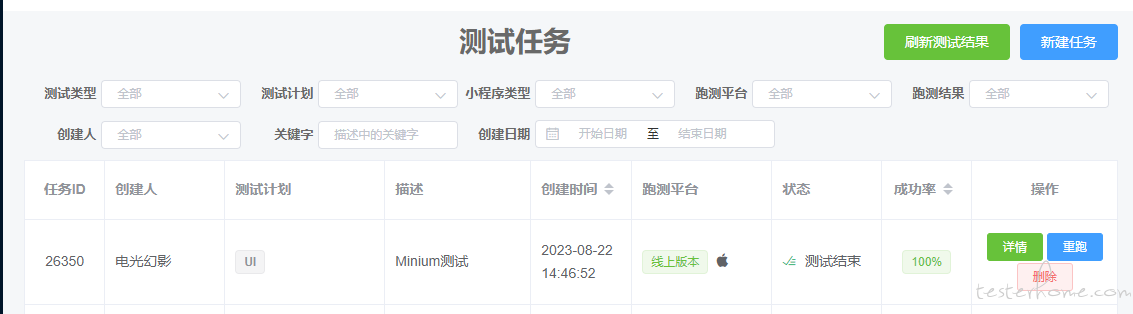
这里按照指引,先上传用例到云测,然后配置测试计划,然后可以通过手动在云测上执行测试任务,或者创建云测定时任务来执行 minium 用例。
群接龙小程序是在打包完成后,利用云测提供的 第三方 API 接口,创建测试任务并发生测试报告,这样可以方便放入 Jenkins 中进行持续集成。这步可根据自己的场景来使用。最终效果展示:

利用录制回放辅助定位元素
在搭建 UI 自动化的过程中,元素的定位与维护是难点之一,一个页面元素可能需要多次调试之后才能获取到正确的值,这个过程是非常耗时的,并且一旦页面发生变动,我们又需要重新大量的花费时间去维护元素。
微信开发者工具本身,为我们提供了一个可视化的脚本录制功能,可以将我们的操作记录下来,并将脚本导出对应的元素信息
下面以前面提到的 商品库按钮 为例,详细介绍如何获取对应元素信息。
1、录制对应用例
首先打开微信开发者工具,进入录制回放,具体操作可以参考 录制回放 | 微信开放文档
打开录制回放页面后,根据测试用例录制脚本,这里我们直接点击商品库按钮,然后添加商品。
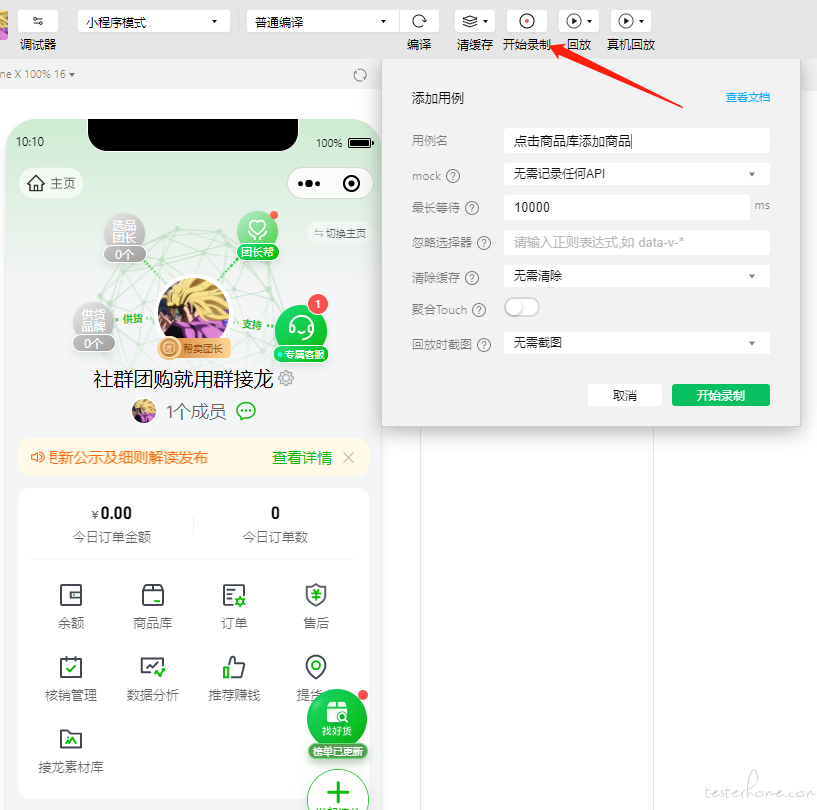
录制完成后,我们可以看到用例详情里,记录了商品库这个按钮的路径和 xpath,将用例导出,获得一个 zip 压缩包
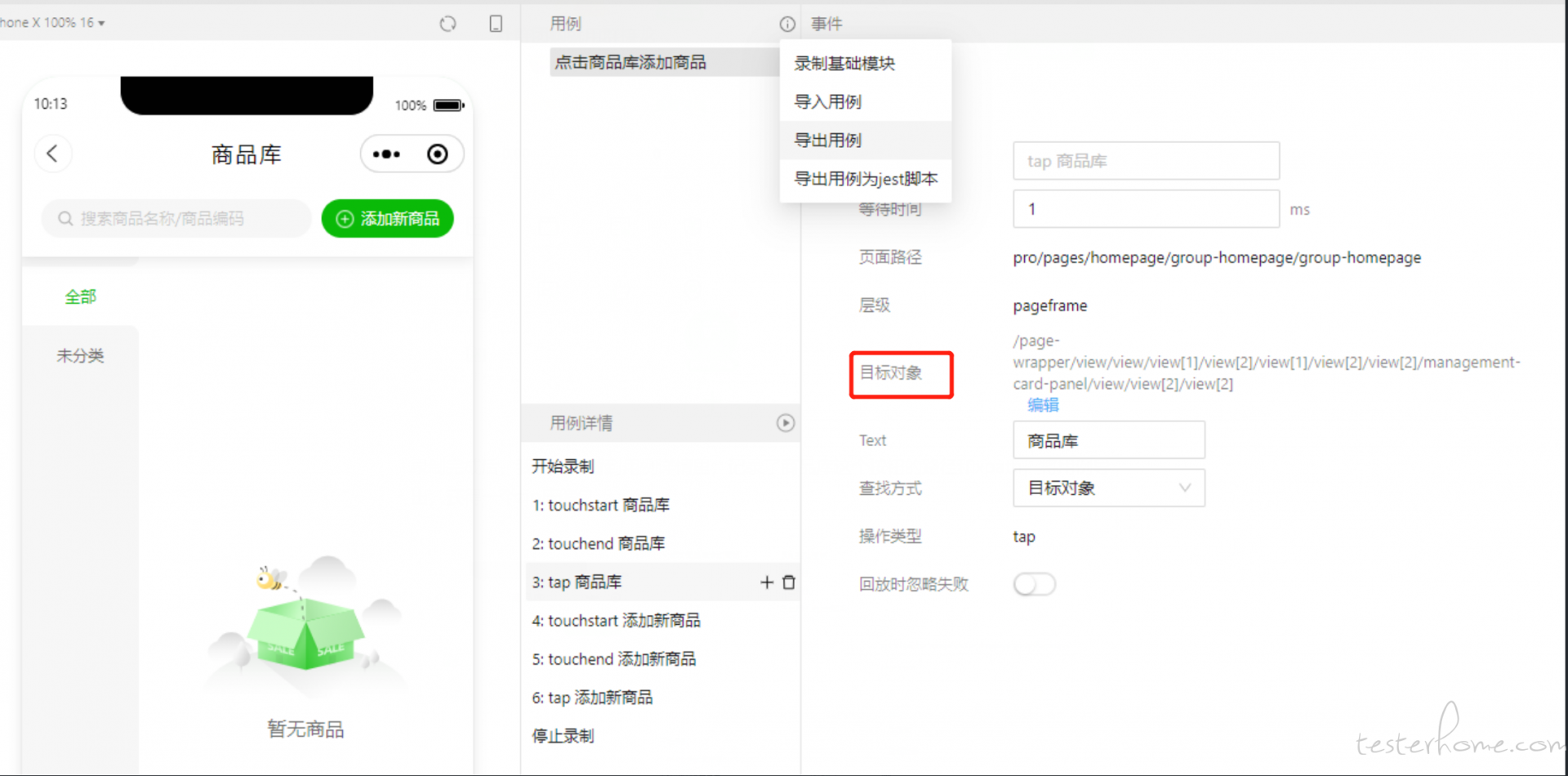
从上图可以看出,商品库的目标对象已经在页面中显示了。有了这个目标对象的表达式,就可以用 Minium 相关接口(如 get_element )去定位元素。
2、处理用例脚本(可选)
我们也可以用一个脚本,将上面操作中,所有的操作对象全部导出,这样方便 Minium 中使用。具体操作步骤如下:
(1)将上述导出的用例 zip 包解压之后,获得一个 json 文件。将 json 文件覆盖我们 示例代码项目 的 script/script.json。

从 json 文件中,我们可以看到里面的 commands 字段里,记录了商品库的关键信息:
- target:目标元素的 xpath 表达式;
- path:元素所在的页面路径。
(2)利用示例代码中的 read_script.py 帮我们读取打印出这两个字段,便可以快速实现自动化。
read_script.py 脚本的解析主要流程如下:
首先,根据传入的 json 文件,我们先处理 path 字段,通过执行脚本,可以将获取到的页面路径通过"/"拆分开,并根据拆分的路径遍历路径,创建页面文件夹和页面文件,如果当前遍历的页面已经存在,则跳过创建。
执行脚本中的 get_path() 方法 执行完成后,我们就自动生成了页面文件夹和页面,接下来,只需要再获取元素,将元素维护到对应的页面即可。
执行脚本中的 get_targe() 方法 获取 Json 文件中,类型为 tap 的 target(元素 xpath)、text(点击元素的文本)、path(元素所在的路径),并将其打印出来。
实现效果:命令行运行 python3 common/read_script.py