
移动测试开发 浅谈机器学习都要测试什么
机器学习的测试主要是测试现有模型准确性,这就涉及到几个关键词:
◆数据集:供模型训练时使用的,提供训练、测试以及预测用的数据集合
◆算法类别:即算法归类,如:二分类,多分类,文本分类,聚类,回归,图像检测,图像分类,推荐等
◆算法框架:用于模型训练的框架,如 PyTorch,XGBoost,Onnx,Sklearn,Bert,Tensorflow 等
◆算法:机器训练模型的算法,例如深度自然语言学习算法文本分类、机器翻译、相似度计算等;物体检测算法 YOLO、CenterNet 等,基于 sklearn 框架回归类算法随机森林、决策树等。
了解了以上用于机器学习相关的概念后,进入我们的测试环节,整个测试业务流程,总结如图:
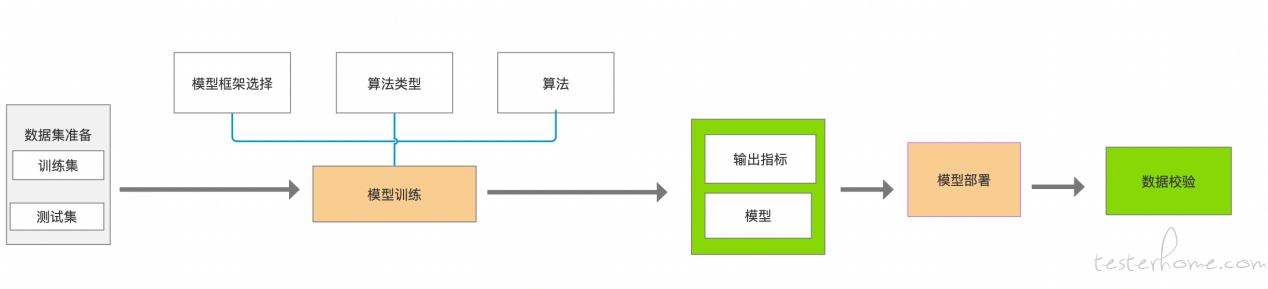
下面通过结合测试实例来进行说明:
前提:确认需要验证模型的框架、算法类型等
示例算法:算法类别 - 二分类、算法框架-XGBoost
第一步:准备适用于模型训练的数据集,例如有些模型是不需要出指标参数的,则不需要准备测试集,有些模型在算法中只需要验证集(图像检测),有些是需要出指标参数后进行输出的则需要准备训练集和测试集 。
说明:本实例中需要输出相应指标准确率、精确率、召回率,准备训练集 bird_train,测试集 bird_test,同时数据集需要满足指定 target 目标列,用于分类,需要注意准备的数据要满足实际训练模型算法的要求,比如此实例中若是 target 列中出现二个以上的分类,则会直接训练失败,同时训练的数据集应最大的满足真实的业务场景,才会训练出更加准确的模型,供后期预测使用。在机器学习这一块业内一般会有一些数据工程师根据实际情况做了准确的统计,并且分享出来,我们可以从官方文档中找到一些测试用的准确数据集。
针对数据集我们需要注意的测试点:
1.数据集存储:在进行训练时我们需要获取数据集地址,那就涉及到数据集的存储形式,目前主流的存储支持本地文件存储、hdfs 存储以及 S3 存储等。
2.文件存储的类型:进行训练时算法工程师对数据的解析,一般文件存储的类型需要支持 csv,libsvm,tfrecord,json 以及其他类型
3.字段特征:即数据集中字段在建模和预测时的作用,描述数据集的元信息。如唯一标识一条样本数据的 ID,特征值 Feature、用于标识数据集中的数据列/标签列的 Target 等
4.数据类型:即数据集的字段类型。针对不同的算法对数据集的也有相应的字段类型要求,所以在我们准备数据集时一定要满足算法的要求创建,否则直接导致训练模型失败
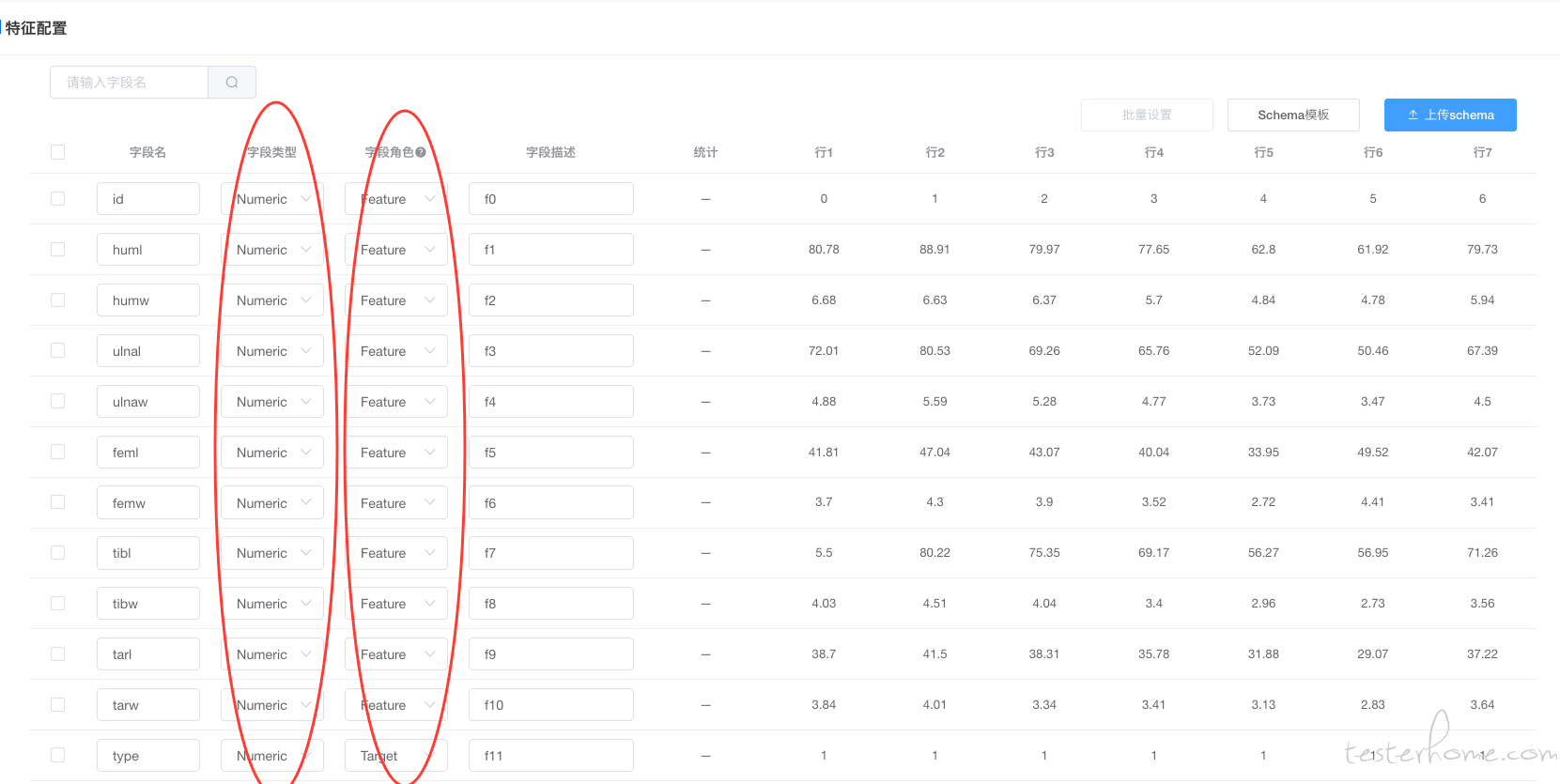
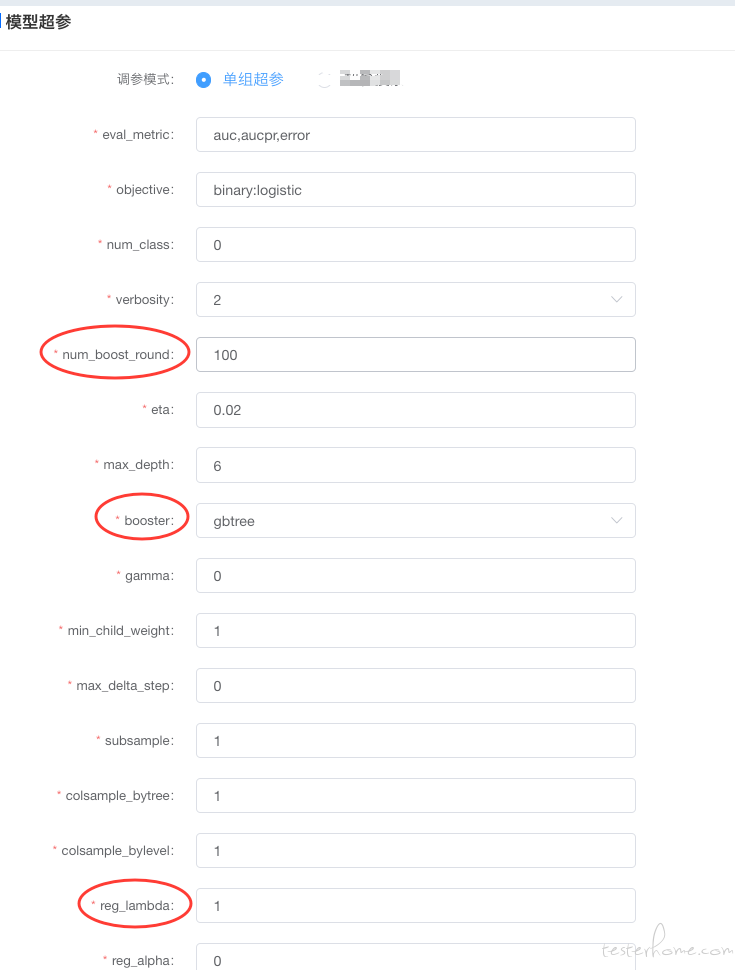
第二步:创建模型。选择相应的框架模型后输入相应的模型训练参数。是在进行模型训练时根据实际情况进行了一些调优等,针对不同的算法框架,想训练出准确的模型,需要大要了解相关的算法知识,也是专业的算法工程师来进行指导和确认。
说明:以 XGBoost 为例,如我们不考虑模型的最终效果只验证模型可用性,在数据量非常大的情况下,需要调低参数 num_boost_round ,为了防止出现过拟合出现,需要添加正则项 lambada 或者调整 Max_depth 值,运行数据选择参数 booster 等,若是对模型的要求不高一般情况下我们工程师会给出一些默认参数运行。
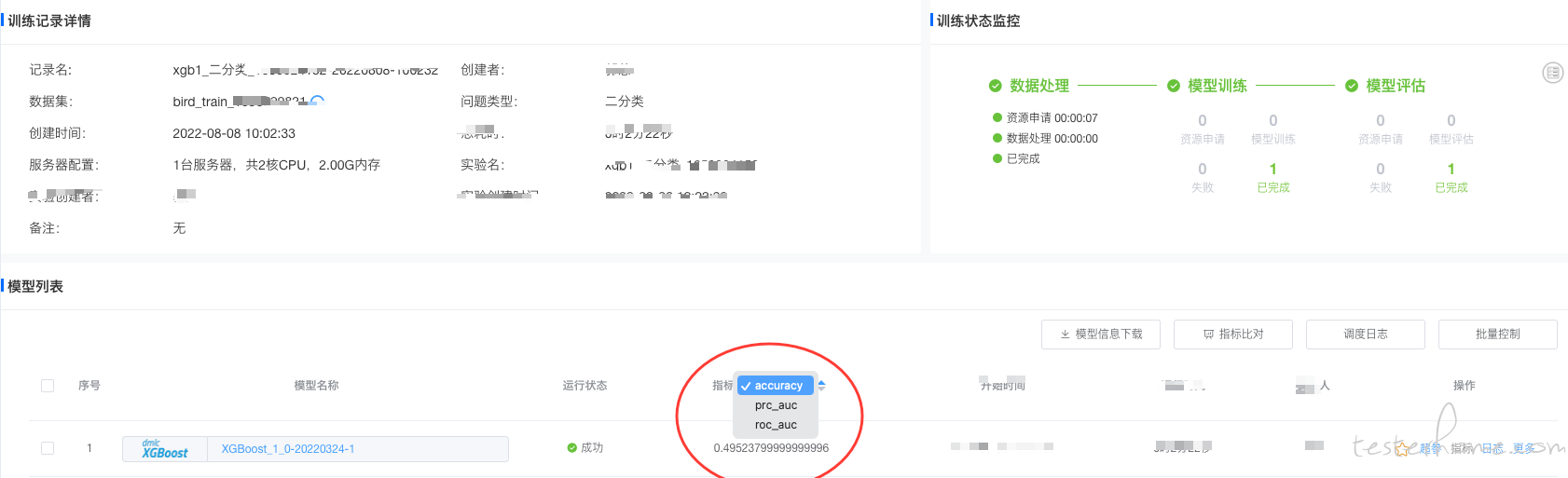
1.选择相应的训练集和测试集,如图:

2.进行参数选择:
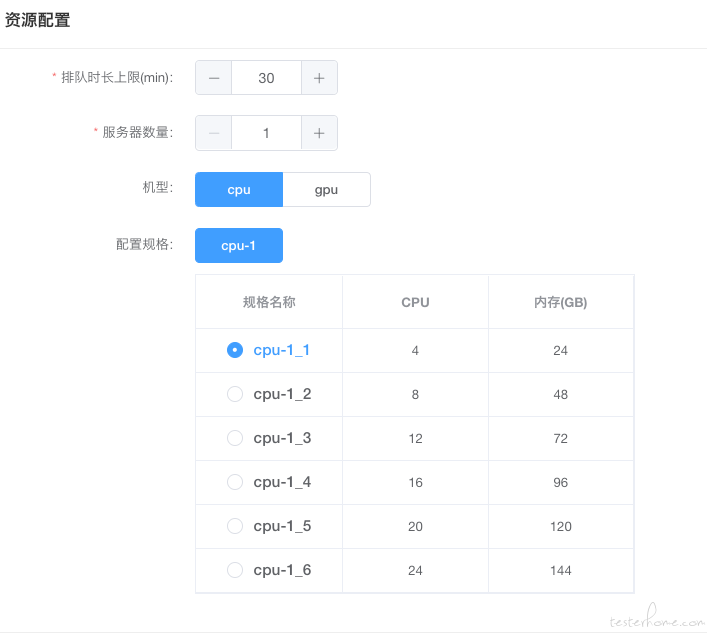
第三步:模型训练,那么任务提交出去需要资源来进行支持。需要确认资源是否满足;训练任务是否可正常获取数据集;模型是否可正常启动;模型训练时传参数是否成功;训练好的模型是否可正常上传等。
说明:模型训练需要服务资源的支持,分类、回归、推荐类的算法可能仅需要 CPU 的资源即可,但是像图像类,深度语言类的算法,需要 GPU 的机器来支持。这一步就需要验证根据实际业务的场景查看客户分配到的资源是否可用。训练过程中我们会有一些参数可能是单独存储,这时就需要验证这些参数是否成功的被算法调用到。最后模型训练成功后,我们需要验证模型是否被存储下来,这样才可以供后续的部署等使用
测试功能点:
1.任务是否成功提交
2.任务提交到的资源节点是否准确
3.多任务提交时调试到的节点是否按资源调试策略进行
4.任务启动容器是否正常
5.数据集获取
6.模型训练是否正常
7.模型训练时的传参是否准确
8.模型训练指标输出
9.模型保存
10.其他功能交互逻辑
第四步:模型部署。模型训练成功的最终目的就是部署应用到业务中。
说明:在第三步中训练成功的模型会被保存下来,然后我们可以通过获取模型的地址,来对模型进行部署应用。
此过程中我们需要验证:
1.模型部署策略
根据实际业务需要,选择我们的需要部署的模型框架、环境变量、是否支持负载均衡、实例占用资源情况、是否支持挂载等。
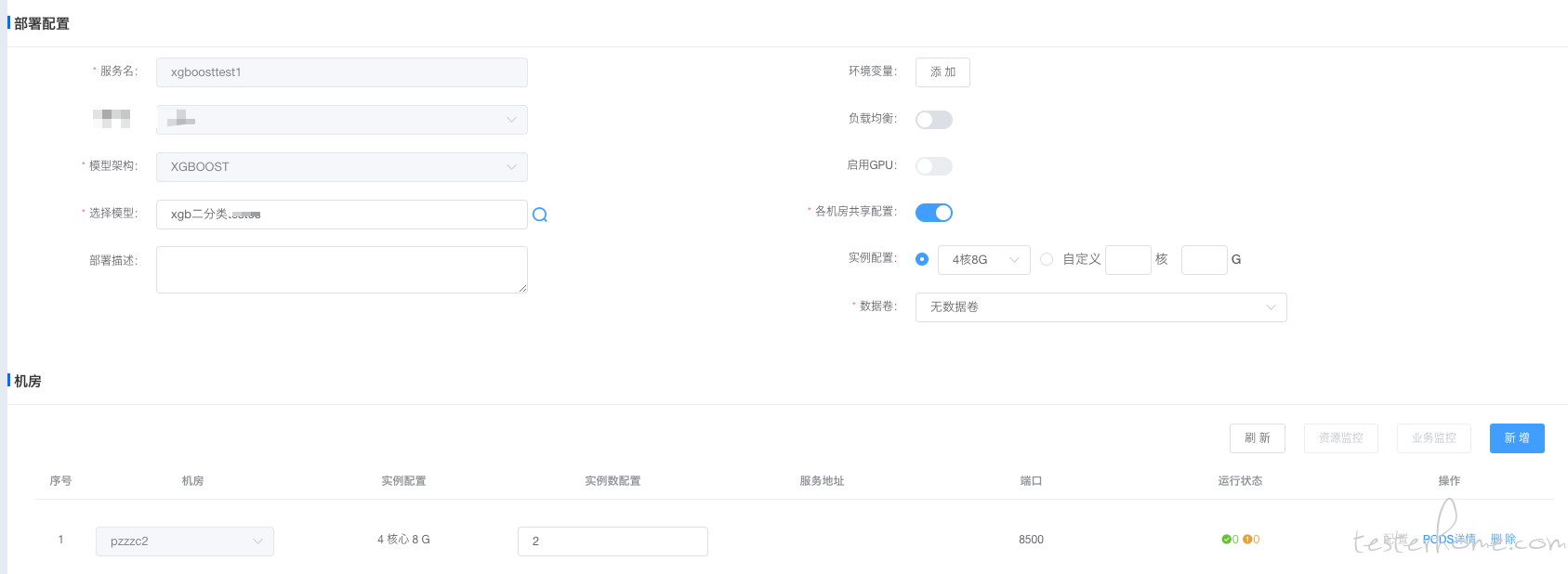
2.模型是否被正确部署
主要是指实例启动是否正常,容器是否可正常工作
第五步:验证被部署的模型的准确性
说明:训练模型被成功部署后,正常是可以通过一条条的测试数据进行验证,并输出结果。
例:
curl --request POST 'http://IP:8500/PredictionService/Predict' \
-d '{"type":1,"request":{"xgb_request":{"max_feature_len":3,"records":[{"float_value":[1,2,3]}]}}}'
结果:
{"sid":"-1","result":[{"value":[0.49976247549057009]}],"outputs":{}}
测试步骤:
1.准备满足模型要求的测试数据
2.根据业务支持,请求相应的 pod 地址
3.验证输出指标是否正确
机器学习平台远不只是以上的几个部份,例如训练模块参数调优、模型训练的任务资源调试及性能优化、服务部署策略等每一个模块其实都会涉及很多的功能逻辑校验,相对测试时除功能性的测试外,还需要稳定性、性能、压力的测试等。