
在使用 Java 线程池实现各种的需求过程中,很是能体会线程池的好处。但是随着需求增加,发现 Java 线程池自带的集中模式也有点不太够用。所以又想自己根据现有的 API 进行拓展的想法。
Java 线程池执行 task 的流程图如下:
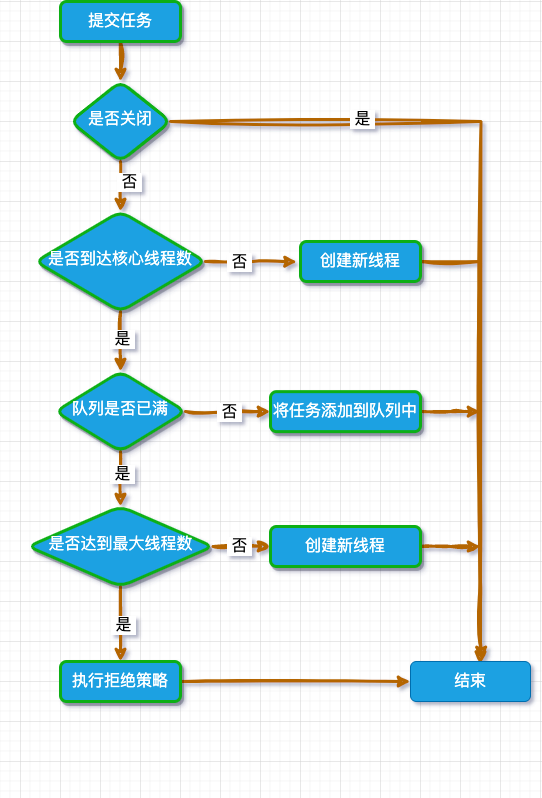
在是否创建新的线程池逻辑中,只有当核心线程数未满和任务队列已经满了两种情况,但是在性能测试过程中,经常会批量初始化很多数据,这个时候如果使用异步进行初始化,就需要一个相当大的等待队列长度,而通常线程池使用核心线程数和最大线程数来控制线程池的活跃线程数量。无法实现动态根据等待队列中的数量多少灵活增加活跃线程数来提升异步任务的处理能力,也无法动态减低,减少线程池活跃线程,降低资源消耗。
这个问题的主要症结在于参数corePoolSize设置之后,就无法通过当前的策略进行自动调整。如果使用 cache 线程池,那么等待队列又无法容纳大量等待任务。
翻看源码得到java.util.concurrent.ThreadPoolExecutor#setCorePoolSize这个 API 可以在线程池启动之后重新设置corePoolSize,通过这个 API 基本就是实现主动调整活跃线程数数量,实现上面提到的需求。
首先确认一个增加和减少的策略,我是这么设计的:如果等待队列超过 100,就增加 1 个活跃线程(corePoolSize),如果等待队列长度为零,就减少 1 个活跃线程(corePoolSize)。当然增加减少都在一个范围内。
其次要解决检测的策略,我一开始设想就是在添加任务的时候进行检测,发现容易发生,任务队列开始超过阈值之后,进来一个任务就创建了一个线程,一下子就到最大值了,缺少缓存。后来决定使用定时机制进行检测。最终决定在daemon线程中实现。由于 daemon 特殊机制使用了 1s 作为间隔,所以单独设置了一个 5s 的线程池检测机制。
/**
* 执行daemon线程,保障main方法结束后关闭线程池
* @return
*/
static boolean daemon() {
def set = DaemonState.getAndSet(true)
if (set) return
def thread = new Thread(new Runnable() {
@Override
void run() {
SourceCode.noError {
while (checkMain()) {
SourceCode.sleep(1.0)
def pool = getFunPool()
if (SourceCode.getMark() - poolMark > 5) {
poolMark = SourceCode.getMark()
def size = pool.getQueue().size()
def corePoolSize = pool.getCorePoolSize()
if (size > MAX_ACCEPT_WAIT_TASK && corePoolSize < POOL_MAX) {
pool.setCorePoolSize(corePoolSize + 1)
log.info("线程池自增" + pool.getCorePoolSize())
}
if (size == 0 && corePoolSize > POOL_SIZE) {
pool.setCorePoolSize(corePoolSize - 1)
log.info("线程池自减" + pool.getCorePoolSize())
}
}
ASYNC_QPS.times {executeCacheSync()}
}
waitAsyncIdle()
}
ThreadPoolUtil.shutPool()
}
})
thread.setDaemon(true)
thread.setName("Daemon")
thread.start()
}
如果是在Springboot项目中的话,daemon线程会很快结束,所以需要写成一个scheduled定时任务,这里代码相同就不多赘述了。
在即将写完本篇文章的时候发现一个另外的 API:java.util.concurrent.ThreadPoolExecutor#addWorker,第二个参数注释如下:if true use corePoolSize as bound, else maximumPoolSize. (A boolean indicator is used here rather than a value to ensure reads of fresh values after checking other pool state).
也就是说第二个参数为 false 的话就使用的最大值的线程,在execute()源码中有注释:
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
第二步,如果添加队列失败或者重新检测没通过,则会创建新线程。其中调用的方法如下:addWorker(command, false),说明这个 API 的功能应该就是直接创建线程执行任务的方法。可惜 private,直接调用的话,不太优雅。暂时放弃了。