
移动测试开发 k8s 零宕机滚动更新
K8S 已经逐渐成为企业技术平台标准,能够支持快速部署和扩展应用,其中控制器的滚动更新能力能够使得应用发布更加简便和平滑。但是,在实际应用的更新发布过程中,出现服务断流的情况仍然时有发生,为了解决这一问题,我们还需要通过配置一些额外规则,才能让 k8s 更准确地去处理服务滚动更新过程中的客户端请求。
问题描述
在实际应用中我们发现 k8s 貌似并不能完全保证服务的 “零宕机” 滚动更新,在确定滚动更新过程中至少有一个 pod 处于可用状态后,在发布过程中仍然会出现服务断流的情况。具体原因是什么呢?要如何才能实现更平滑的 “零宕机” 服务滚动更新呢?
问题原因
为了实现更平滑的服务更新发布,我们通过分析 pod 的生命周期,以及 k8s 服务更新时 kubelet 和 Endpoint Controller 的处理机制,一起来看看出现上述问题的可能原因有哪些呢?
1.pod 启动时的问题
当 pod 启动后,pod 需要向 Kubernetes 发出就绪信号,表明它已准备好接收请求了,之后该 pod 才能作为 endpoint 加入 service 中,随即接收来自客户端的请求。如果我们未在 pod 的生命周期中指定就绪探测,则该 pod 一启动就会视为就绪,这意味着它将几乎立即开始接收请求,如果我们的应用到那时还没有准备好接受连接,客户端就会收到 “连接被拒绝” 类型的错误
2.pod 删除时的问题
相比于 pod 的启动过程,pod 的删除过程需要注意的问题更多些。比如在滚动更新过程中,旧版本的 pod 收到终止信号后,是否还会继续接收到请求?已经接收但尚未完成的请求怎么处理?为了说明这些问题,需要搞明白 pod 删除时 k8s 的实现机制是怎样的。
首先,Pod 删除的请求到达集群入口 API Server 后,API Server 修改 ETCD 中的状态。之后,Kubelet 和 Endpoint Controller 两个组件监听到 pod 删除事件后,并行地去处理 pod 删除的一系列动作。
①.Kubelet 在 pod 删除过程中主要负责终止容器进程。当容器收到 SIGTERM 信号后,我们的应用程序可以捕获该信号并开始关闭,如果容器在一段事件内未自行终止,会发送 SIGKILL 信号将容器干掉。
②.Endpoint Controller 在 pod 删除过程中负责将 pod 从 iptable 中摘除,即阻止新的请求流入被删除 pod。这个过程包括:Endpoint Controller 会重新向 Apiserver 发送一个修改 Endpoints 对象的请求,worker 节点上的 kube-proxy 监听到删除 endpoint 消息后,更新各自节点上的 iptables。(这里的一个重要细节是删除 iptables 规则对现有连接没有影响)
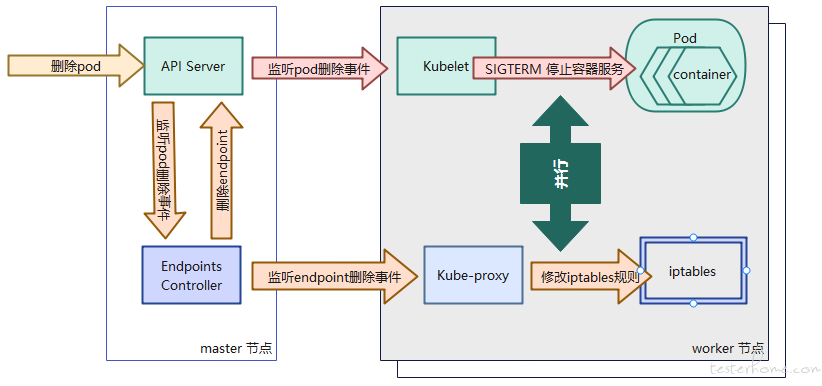
这里需要重点关注的是,Kubelet 和 Endpoint Controller 这两个组件是并行地去处理容器应用关闭和流量分发规则更新这两项任务的。实际执行过程中,因为更新 iptables 的事件链路要长很多,可能会导致 pod 中应用程序已经关闭,而 iptables 规则更新尚未完成的情况出现。其结果是客户端请求仍有可能会被分发给一个已经关闭的 pod,从而出现客户端收到 "连接拒绝 "类型的错误。
解决办法
1.在 pod 启动时防止连接拒绝
需要做的就是确保应用程序准备好正确处理传入请求时,让就绪探针返回成功。比如,添加一个 HTTP GET 就绪探针并将其指向应用程序的基本 url。在很多情况下非常有效,并且不必在应用程序中实现一个特殊的就绪点。探针的请求路径应该尽可能逻辑简单,防止因外部依赖导致检测全部失败,造成雪崩。
2.在 pod 删除时防止连接中断
在 pod 删除时的主要问题是 SIGTERM 终止信号可能会在流量分发规则更新完成前到达,导致流量分发到已终止的容器服务中。而防止这个问题出现的解决思路是,即使收到终止信号,也需要稍等片刻,然后再执行退出。此间 Pod 也需要继续接受连接,直到所有 Kube-proxy 完成 iptables 规则的更新。
正确关闭应用程序包括以下步骤:
①.等待几秒钟,然后停止接受新流量
②.等待所有活动请求完成
③.最后关闭进程。
但是稍等片刻具体要等多久才够长?在大多数情况下,几秒钟就足够了(这里有一点要注意,k8s 发现容器没有正常关闭后,会默认在 30 秒强行终止进程,除非我们更改 Pod 定义中的 terminationGracePeriodSeconds),但不能保证每次都足够,因为当 API Server 或 Endpoints Controller 负载较高时,通知可能需要更长的时间才能到达 Kube-Proxy。
在调用 SIGTERM 之前,Kubernetes 会在 Pod 中公开一个 preStop hook,如果无法更改代码来获得等待时间,我们可以添加一个等待几秒钟的 preStop hook。
可以像这样:
lifecycle:
preStop:
exec:
command:
- sh
- -c
- "sleep 5"
虽然不能完美地解决问题,但即使是 5 到 10 秒的等待也会大大改善服务部署过程中的稳定性。
总结
K8S 在考虑服务自动部署更新方面已经做得很好了,但是为了在生产环境中运行我们的企业级应用,我们就必须了解 Kubernetes 是如何在后台运行的,以及我们的应用程序在启动和关闭期间的行为,才能用好工具,实现更高的服务部署稳定性。