
性能测试的关注点除了请求的数量,一个更关键的概念是 session 的数量。一个用户登录的时候在服务器上可能只创建了一个 session,这样和 100 个用户登录创建的 session 数量所占有的服务器资源是不一样的,所以这就涉及到多个用户登录和设置集合点的问题。
正常情况下,如果排除性能测试中需要包含多用户登录的场景,那么我们需要让所有用户(这里的所有指的是需要测试的用户数)都登录,然后再并发请求。这里面涉及到两个问题,一个是用户的信息管理,一个是设置集合点。下面以 Jmeter 和 Locust 为例子说明这两种用法:
Jmeter
用户信息管理
这里我们管理用户信息,使用 csv 来管理(如果想要使用数据库读取也是可以的,这里只是举例)。我们把用户的信息比方 account 和 password 分列存入 csv 中,然后在 login 请求中添加一个"csv Data set config" ,如下图所示:
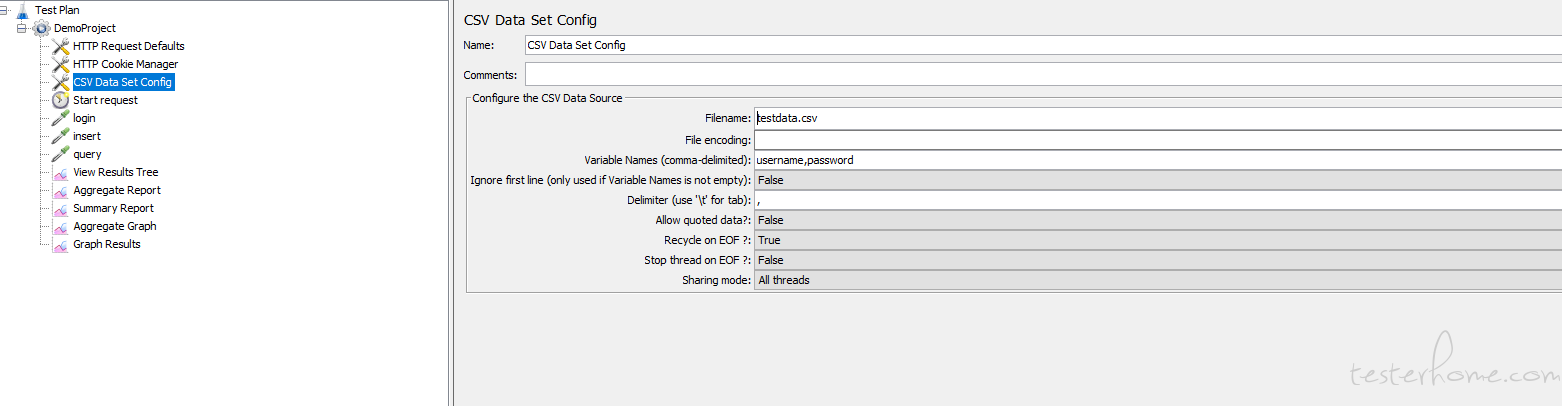
这里关键的信息在于文件名和变量名,文件名用来读取数据,变量名用来使用数据。然后在你的 login request 中使用信息即可
集合点
关于集合点,需要添加一个"Synchronizing Timer",然后设置用户数和超时时间即可。记住,这个集合点需要在 request 之上。
这样,你就会发现,如果你设置多个用户登录以及其他的请求在同一个 Thread Group 中,每一组数据用的是同一个 session id。这个信息可以去 Result Tree 的 Request Body 中查询
Locust
用户信息管理
我们管理用户信息,可以通过数据库来管理,这里以 mysql 为例。如下图代码
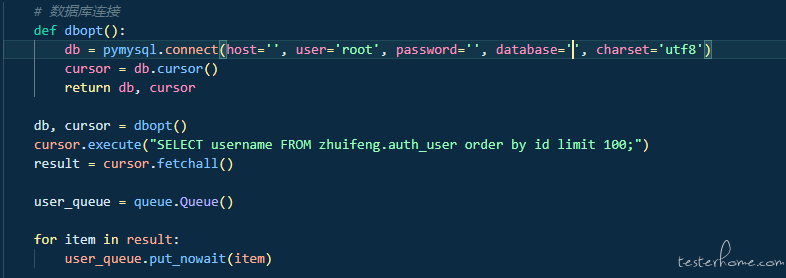
从数据库中筛选出你要的用户信息,然后将信息插入到一个队列中。然后在登录的方法中每次都去从队列中取出一个用户,直到队列为空。当然这里建议队列数和用户数相等,毕竟能够不人为制造 bug 就不制造,哈哈。
集合点
Locust 设置集合点,通过 Semaphore 这个包来实现,具体代码如下
from gevent._semaphore import Semaphore
all_locust_spawned = Semaphore()
all_locust_spawned.acquire()
然后将下列代码放入登录的请求中(一般我会把登录放到 on_start 中)即可
all_locust_spawned.wait(100) # 时间自己定义
再执行测试就会发现,client 的 session 是按顺序发送的请求。
以上,就是 Jmeter 和 Locust 管理用户信息和集合点的方法。