
移动测试开发 物联网测试数据构造实践
我们在测试过程中,经常遇到需要构造大量测试数据的业务需求,比如:统计和计费,我们需要统计近一个月甚至更长时间的测试数据来测试数据统计的变化趋势,统计值的准确性,这些数据有些需要通过数据库 SQL 生成,有些需要通过调用业务接口生成,有些需要通过 kafka 消费数据,有些需要借助平台、语言脚本、工具能力根据数据规则生成等等。
除了自己手动在数据库写入数据外,如果系统有暴露数据接口(通过接口可以构造产生大量的数据),我们优先通过调用数据接口去产生数据,这样不会产生大量的脏数量,也能保证数据的真实准确性。调用接口的好处是可以借助接口测试数据。可以根据数据构造的需求灵活使用接口调用工具,通过构造测试场景、定时器、数据构造脚本等方法,不需要手工输入大量的测试数据,就可以模拟用户使用来产生数据;
业务系统中,需要手工进行业务数据构造,可以将重复的操作步骤,制作成自动化脚本,根据我最近的两次数据构造进行整理,分享一下思路:
场景一:数据统计构造
业务场景:物联网实时统计设备的在线,激活,用户绑定;数据来源包括数据库统计表,redis 实时统计数据,定时批处理进行数据统计,最终从数据库以及 redis 中获取历史、总览以及实时数据;
这些数据来源是实际操作平台时产生的数据,可以通过接口调用产生真实数据,然后再进行数据统计的操作。而我想做的是,每天都有数据产生,并有一定的变化趋势,又不想每天修改参数去执行一次又一次的测试脚本,因此我使用了 metersphere 中的定时器,这样就可以在一天中不同时段自动执行脚本产生真实的数据,也就有了变化趋势;
1.实时数据构造
通过 metersphere 调用业务接口、添加定时器,定时执行接口场景产生真实的数据;
统计每天每小时的活跃设备数,需要准备至少两个接口调用,一个是模拟设备上下线调用接口,另一个是批处理统计每小时活跃数;
模拟设备上下线,通过引入 CSV 文件,通过条件控制器、定时器功能调用接口,构造每小时活跃设备数量。
①. 通过 CSV 文件引入设备信息
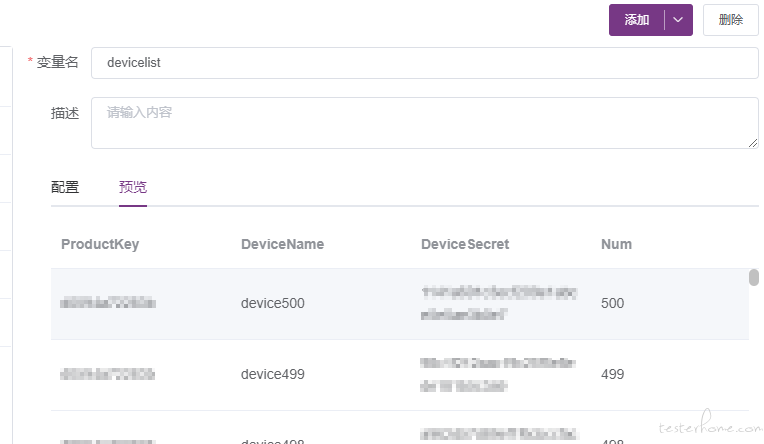
②. 通过条件控制器选择操作设备列表,为了操作方便,我这里导入 500 个设备,由于 metersphere 并发有限,我从中选择 20 个设备每次执行,如果想每次操作的设备不同,可以通过写一个前置脚本,选择 CSV 中的设备列表,我这里就不再详细说明,可以根据自己的使用习惯以及场景需求灵活定义脚本。
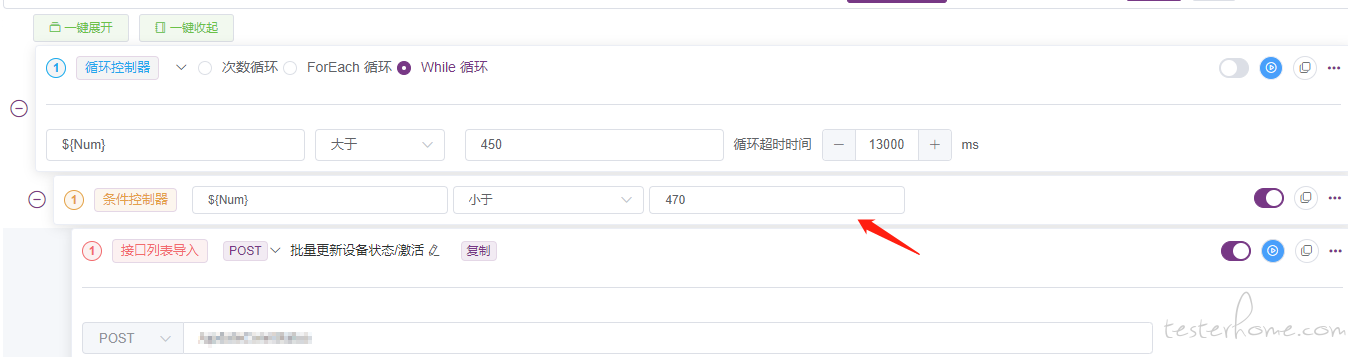
③. 在接口调用中可以通过参数调用,使用 CSV 中的变量参数

④. 生成定时器,定时器可以自定义,可以精确到秒,我这里是每天每小时执行一次
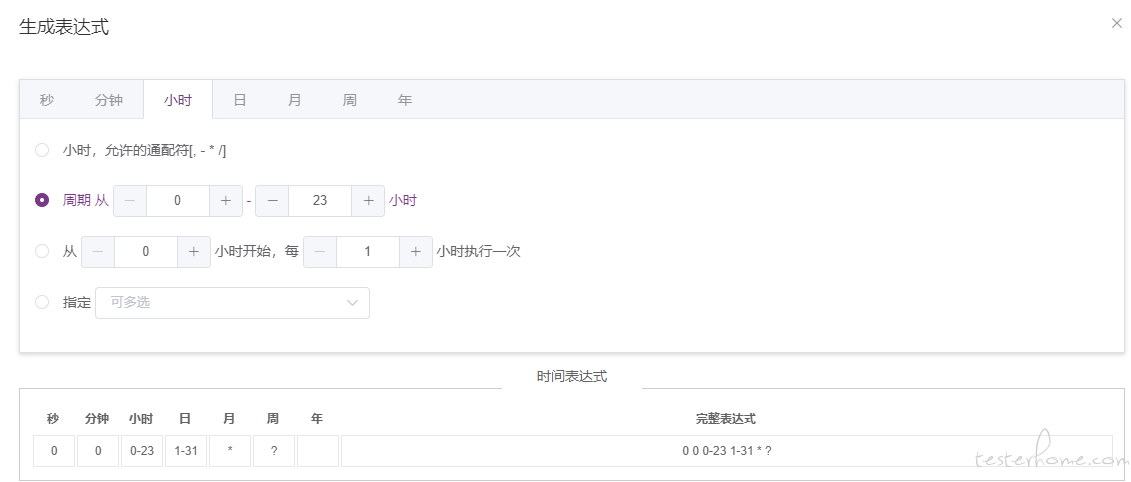
⑤. 到这里就可以添加批处理统计的接口调用了,同样添加一个定时器,每小时执行一次,从添加定时器开始就可以每天每小时都有数据产生了。
我这里的数据构造,只需要保证每天都有数据产生,没有设计不同时间段的变化趋势,由于统计数据直接写进统计数据库表,与真实业务数据隔离,想要构造趋势变化,一种是通过写脚本,随机读取 CSV 中的数据执行。
另一种就是直接修改数据库,数据统计趋势不影响真实业务数据,因此趋势变化就通过数据库脚本进行修改了。
2.历史数据构造
除真实统计数据外,历史发生的数据,如果只考虑数据构造和统计趋势效果,而不需要校验统计的准确性,这时就可以通过脚本构造了,而构造数据脚本需要手动输入数据,很是繁琐,此时就可以借助工具进行数据构造了,UE 就是很好用的工具。
可以将数据分为两种,一种是基础数据,另一种是测试数据,基础数据就是不需要改动,属性一致的数据,可以直接复制粘贴,在构造 sql 脚本时,这些属性可以放到前面;
对于自增的主键、默认值,插入时可以不填写,数据库会自动匹配。
剩下的数据就是需要修改的测试数据了,使用 UE 工具,选择列模式,可以对历史数据进行插入修改,如下:批量创建某一天的历史数据,通过脚本 UNIX_TIMESTAMP (DATE_SUB(CURDATE(),INTERVAL 1 DAY)) 可以随意创建当天以前的所有历史数据,通过 UE 列模式修改天数即可,对于长度一致,可以批量修改的数据可以放在前列,属性不一致的可以放到最后。
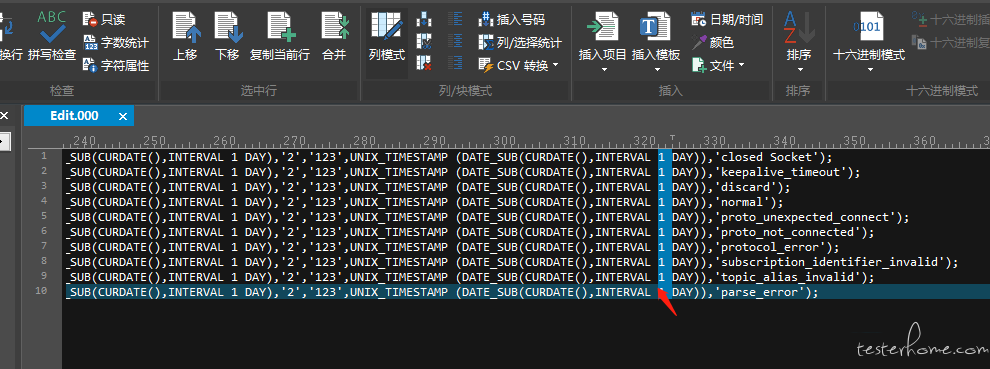
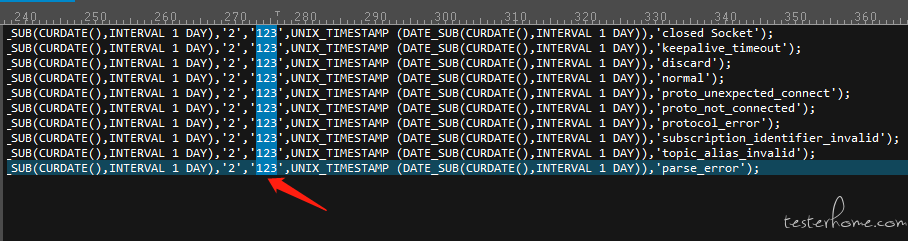
这样就可以批量构造 sql 脚本了。
场景二:计费数据消费 kafka 生成订单
业务场景:订单数据在 kafka 中实时同步,需要构造一个时间段内的订单数据(比如近一个月产生的订单数据,订单费用)。
业务中用到了 kafka 产生数据,可以实时消费数据,用于两个隔离业务之间进行数据交互。Kafka 的数据结构,就是一个 json 数组。我们又不能完全依赖研发提供脚本去构造测试数据。而每次手动编写 json 格式的数据,既浪费时间,又可能会产生格式错误影响数据插入。为了一劳永逸,我编写了一个写入 kafka 的 jar 包,提供 http 接口,简单的几行代码,便可以为构造数据提供高效便利的途径,只需要在接口调用时,编写脚本产生 json 数据即可实现批量构造数据;
构造 kafka 数据公共类提供写入 kafka 接口,传递 payload、topic、key 参数:
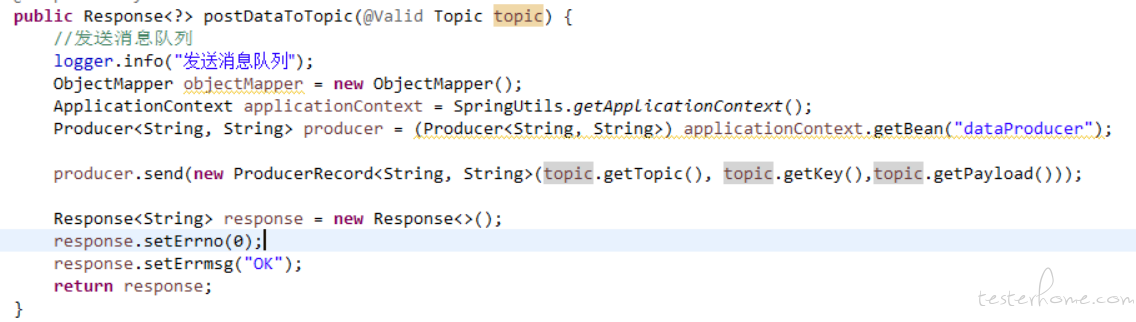
公共接口写好了,而我要构造一个月产生的订单数据,这时候就可以用 metersphere 中的循环控制器了,我在变量中添加开始时间、结束时间。然后写一个脚本,随机在时间范围内生成一个时间戳,通过循环控制器就可以在这个时间范围内构造任意数据的订单了。对于订单号的生成我也可以在脚本中实现。
Metersphere 调用接口,添加循环控制器,可以选择构造订单数量

添加环境变量,设置构造订单产生时间,
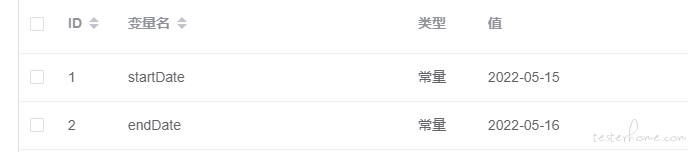
通过前置脚本在日期范围内随机生成订单产生日期:
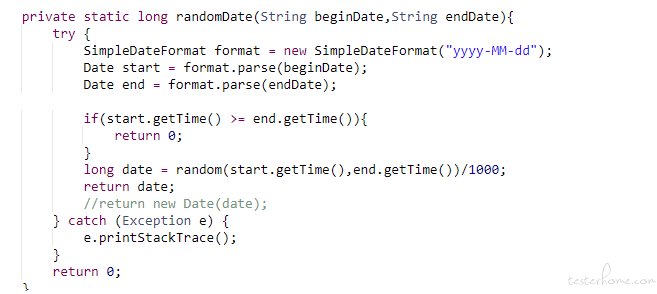
通过前置脚本随机生成订单号防止订单重复:
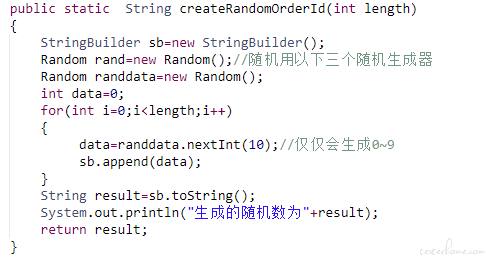
通过前置脚本,生成订单 json 数据

调用接口,写入订单数据到 kafka
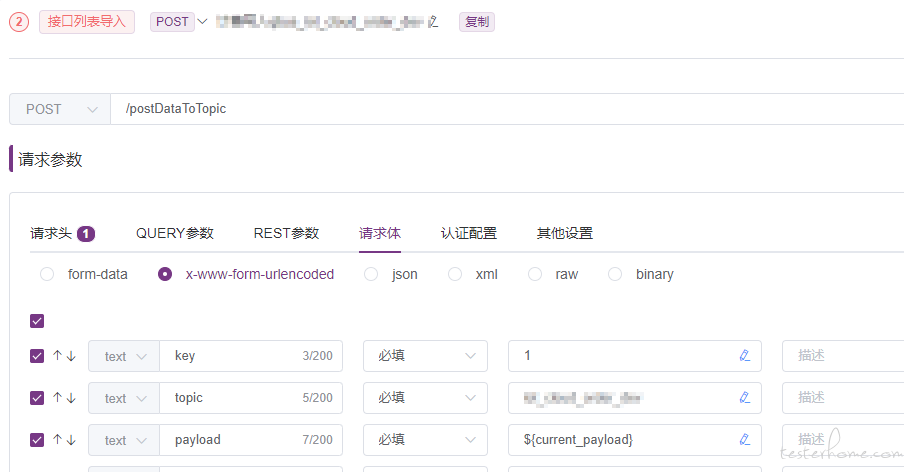
至此,大批量构造订单数据就完成了。
总结
测试数据构造的方法有很多种,真实有效、不会造成冗余数据的就是接口调用了。我们要明白数据产生的背景,以真实使用的场景去构造数据。借助自动化的工具,去实现数据构造。这次的经验只是分享一些实际应用中的想法和实现过程,总结起来构造测试数据的方法主要有以下几种:
①. 直接在业务平台页面操作构造大量的测试数据,这种方法构造数据最真实,但是操作繁琐,不建议使用。
②. 线上数据导入,有些数据可以直接从线上导入,可以看到真实数据结构,对线上数据分析,也能发现一些边缘 case;
③. 通过接口调用工具,这种方式效率比较高,不依赖 web 页面,但是要熟悉接口产生数据的业务逻辑。
④. 通过数据库脚本,这就需要在测试过程中积累,总结,但是这涉及到多表关联,需要完全熟悉数据库之间的关联,才能保证数据的准确性。
⑤. 接口和数据库脚本结合,我使用的就是这种方法,可以把业务中关联较多的数据通过脚本产生;相对独立的数据,通过简单的数据库脚本编写修改数据。
这些方法,可以结合自己的业务场景,灵活选用,目的就是少量的人工操作达到构造大量数据的效果。如果遇到需要构造复杂、数据量级较大的数据,这些方法,也只是参考,还需要不停的实践,总给经验。