

本文为「Dev for Dev 专栏」系列内容,作者为声网大数据算法工程师黄南薰。
01 自动运维介绍
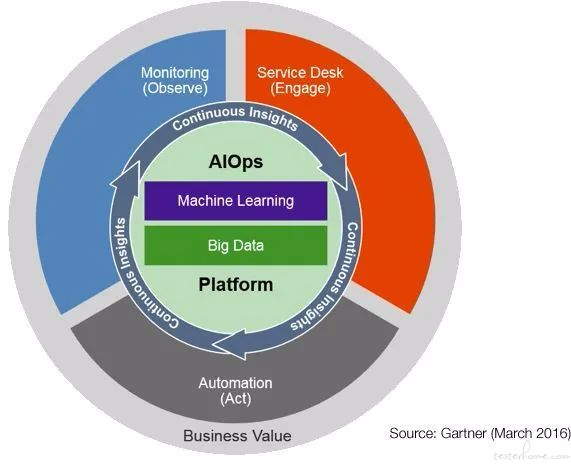
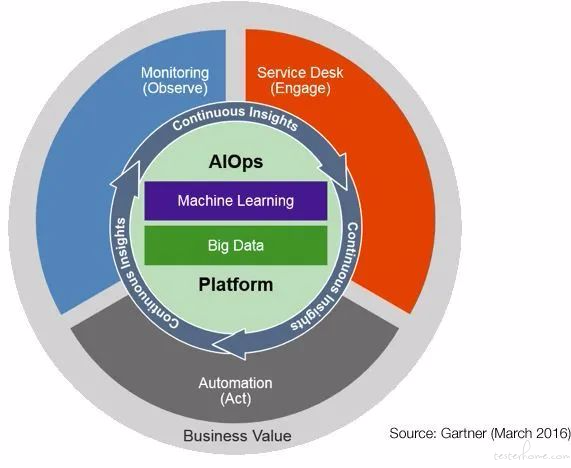
2016 年,Gartner 创新性地提出了 AIOps 的概念 [1],开创了人工智能辅助运维决策的新篇章。
AIOps 的全称为 Artificial Intelligence for IT Operations,即为 IT 运维服务的人工智能。传统的运维方式往往依赖数个具备专业知识的运维人员对某个特定场景下的服务进行监控与决策。随着公司体量的成长,业务场景及数量指数型增长,传统运维将面临着决策时间长、决策难度大、人力成本高等问题,一旦出现重大决策失误,就可能造成巨大的商业损失。然而,海量的数据正好是机器学习的擅长领域。
一套成熟的机器学习算法能够从运维操作中积累判断经验,不眠不休地持续对数据进行监控和分析,为运维决策提供有价值的信息。
02 SD-RTN™ 场景下的自动运维
1、场景介绍
SD-RTN™,全称为 Software Defined Real-time Network,是声网专为双向实时音视频互动而设计的软件定义实时网。
它实现的核心是由遍布全球的机房搭建起的音视频传输网络,每个机房在信息传递的过程中都承担着发送和接受的工作。所有经过这些机房的音视频质量会通过一定的方式进行指标采集和上报,用于实时质量监控。而一旦这些指标反映出经过某个机房的通话出现了不可接受的问题,则需要对机房进行对应的运维操作,以保障用户的优质音视频体验。
传统的运维方法使用绝对水位或逻辑条件的方式进行机房质量监控,这种监控虽然能够识别一些质量异常,但存在着漏警误警严重、维度单一等问题,针对靠近阈值的报警缺少辨别能力,对于非常规质量异常的传输质量指标曲线也缺乏识别能力。
在业务、算法、数据、运维各团队的协力合作下,声网打造了一套专属的 SD-RTN™ AIOps 框架,以机器学习的方式逐步替代了人工运维,打造了迅捷和可靠的自动化运维流程。
2、全链路展示
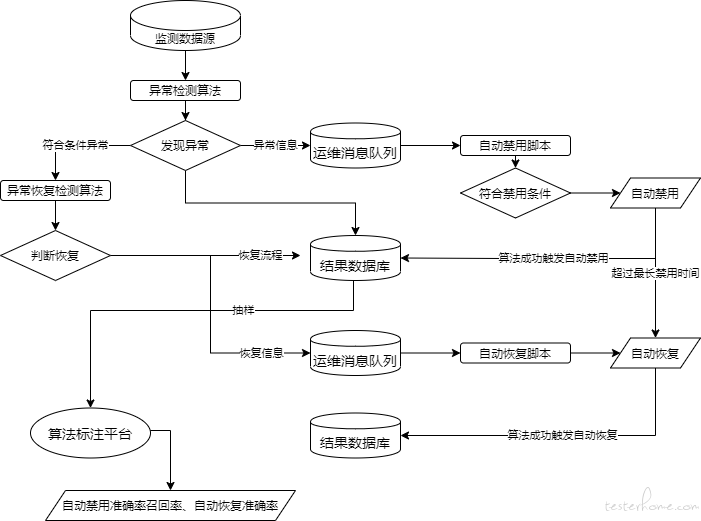
AIOps 现流程如图所示。大规模的机房数据通过数据上报的方式由数据中台处理存储,大数据算法平台流式读取数据,实现机房级、区域级数据实时异常监控,发现异常后将信息流传递到运维侧,同时开启质量恢复检测以监测异常机房质量是否恢复。自动禁用与恢复的数据会存放在算法平台,作为抽样数据以检测算法效果,并为算法后续训练提供持续数据源。
目前算法已经实现秒级粒度和分钟级粒度的优质传输率质量检测,机房间链路检测及机房内存溢出风险检测,从多个维度实现对海量机房的全面监控。
一旦机房质量发生较大程度的异常,算法能够保证全链路在数十秒内及时响应,对机房进行自动运维操作,并能根据质量恢复情况及时对机房进行自动恢复操作。目前算法平均每天执行 50 至 100 次的自动运维操作,基本完全代替了人工操作,有感知的机房异常准确召回均超过 97%,在故障恢复后十分钟内完全实现流量重新接入,达到了精细化运维的水准。
全链路的优化也在本年度持续进行中,算法团队致力于实现算法的自动部署和自动运维,加快算法模型的更新迭代,提高算法故障自恢复能力,便于运维团队操作维护;数据平台将打造高可用的数据中心,实现数据源全年高可用保障;运维平台将打造可编程运维平台,实现运维操作收口;算法判断结果将以信息流的方式传递,从而实现每一条报警的全链路可追踪,打造高性能、高鲁棒性的自动化运维产品。
3、算法介绍
算法团队和业务方协力,通过算法团队开发的算法标注平台对大量机房异常数据进行标注、挖掘,对表现出异常的质量曲线按照特征进行分类,并针对每个类型开发了一套特定的识别方案。
一旦识别出异常,算法还将进一步地基于曲线形态等特征计算各厂商分量对总体质量曲线影响的概率,避免由于单个占有量过大的厂商对整体曲线影响较大而造成误判。
同时,算法还会将视野下钻至区域级别,一旦出现某个区域的用户连接特定机房质量大面积异常,会触发特殊的告警机制进行后续处理。
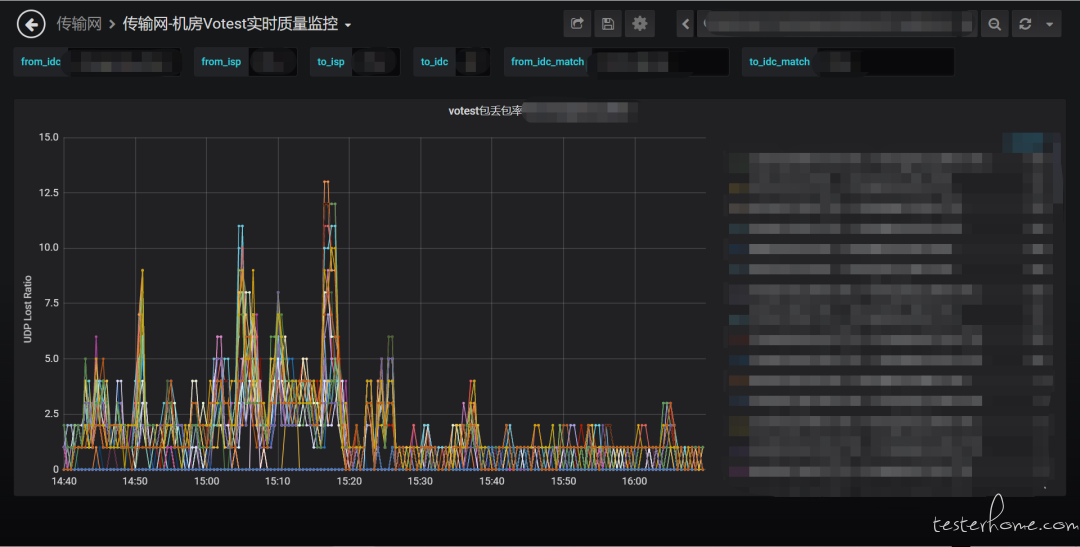
机房间链路检测以包的形式探测、以从一个机房出发及到达该机房的所有包的健康状况来表示该机房的健康程度。
算法团队开发了异常状态基线来判断机房质量。如果传入、传出机房的包出现大规模整体异常或小规模大幅度异常,将会叠加异常值;如果完全平稳则会降低异常值;当异常值突破系统基线则会触发报警进而引发自动运维操作。
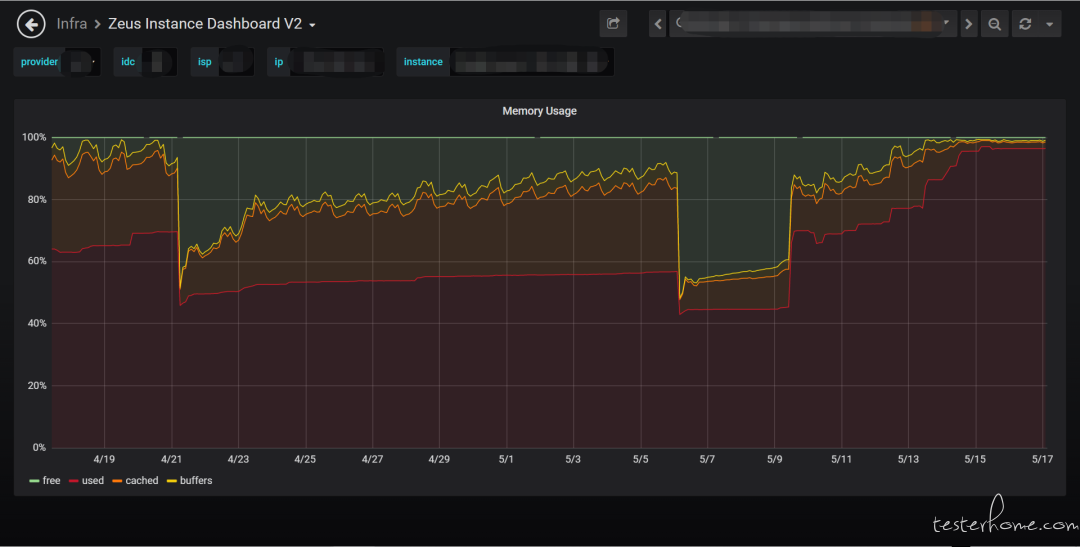
机房内存检测运用了多种滤波、平滑手段,结合业务逻辑寻找内存变化曲线的断点,从断点处进行未来内存容量的预测,识别将要内存溢出的机器并进行报警通知。
03 RTSC 场景下的自动运维
1、场景介绍
实时媒体流处理 Real Time Streaming Center(RTSC)是针对实时媒体流进行云端处理并发布到不同平台的服务。可以基于 RTC 媒体流进行处理,构建云端录制、旁路直播、云端合流、云端截图、输入在线媒体流等多种技术场景。
同时可支持外部媒体源输入和处理。RTSC 的推流和云录制等服务主要依赖机器间信息传输的质量与机器本身的质量,如果机器发生故障就会对整个链路上的媒体流服务造成影响。
2、算法介绍
推流服务机器质量异常检测的思路与大网传输质量检测基本一致。业务上推流服务位于大网传输的末端,在数据处理上,筛选出 RTSC 相关的业务场景,将关注对象从发送端转移到接收端,我们就获得了海量的 RTSC 机房传输质量数据从而支持算法进行异常检测。
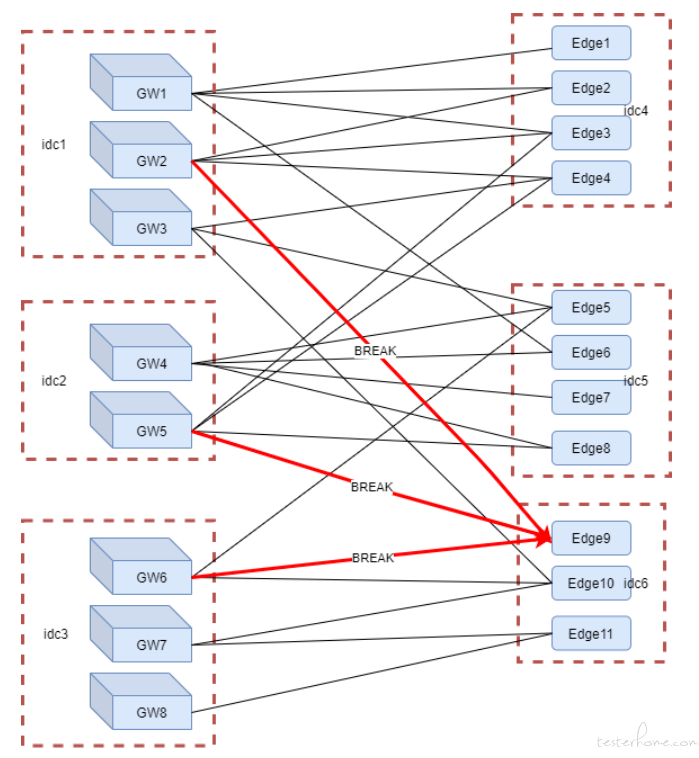
云录制服务中涉及从网关(Gateway)到边缘节点(Edge)的连接,而这些链接一旦发生大面积错误,往往意味着某些网关或边缘节点的机房或机器不可用,如果不及时禁用机房或机器,会影响云录制服务的质量。
云录制服务的质量主要体现在网关到边缘节点的错误连接数,在业务上有着相对明确的阈值,可以按照传统的阈值方法来控制报警。但传统方法由于异常时间和规模的偶然性,可能会出现无法及时响应或无法准确定位错误源的问题。
算法团队和业务方协力,打造了 RTSC-AIOps 流程。该流程以图算法为核心,结合业务逻辑,能够实现快速定位异常机房机器,目前已经完全接管了云录制边缘节点的禁/启用流程,实现了一分钟内快速发现和处理完异常,准确率达到 95% 以上,节省了一半以上的人力,有效提升 RTSC 业务运维效率,保障了业务稳定运行。
04 结语
本文介绍了声网大数据算法团队通过与各个团队紧密合作,打造的由 AI 驱动、大数据支撑、业务需求为指导的快速精准化自动运维服务。
在智能化时代,信息的爆炸式增长导致传统的运维、决策、分析、服务已经无法与环境契合,而算法正是为了解决这些问题而存在的。算法的训练依赖高水平的信息提供者,是一种经验的总结与延伸,是 “站在上帝视角” 纵观全局。
随着算法落地场景的不断增加,声网也会有更多的精力投入到向未知领域的探索,利用 AI 与人力的相辅相成,为开发者和用户提供更稳定、更高质量的产品和服务。
[1]"Gartner says Algorithmic IT Operations Drives Digital Business" https://www.gartner.com/en/newsroom/press-releases/2017-04-11-gartner-says-algorithmic-it-operations-drives-digital-business
(正文完)