
移动测试开发 数据下载重构项目测试总结
背景
最近收到了一个数据下载重构的测试需求,数据指标大概有 400 多个,其中包含一些简单指标(数据库透传)以及复杂指标(需要计算的),测试过程需要我们将指标以 csv 的形式下载下来,逐一验证指标的准确性。本文将对数据下载重构项目测试过程中的测试计划和效率化方案展开介绍。
测试计划
对于重构的项目,脑海中第一个想法就是跟老版本进行对比。鉴于重构之后的项目和历史的数据源不一致,测试环境两个数据源的数据没有打通,将两个版本进行对比意义不大,所以将新老版本对比工作放到了线上验证阶段。
测试过程中最大的工作量是需要逐一验证字段的准确性,纯手工验证暴露如下问题:
①. 文件较大,打开耗时,卡顿,影响验证效率
②. 指标多、数据量大,只能通过抽样验证,无法保证验证的全面性
基于以上两点,在测试环境,我们采用了自动化验证的方案,基于 pytest 框架,具体方案将在其他文章中展开,本文不做详述。
在线上验证过程中,由于新老版本数据源以及数据范围的差异性,会导致新老版本的部分数据无法一一对应,基于这个问题我们将线上回归拆分为两个环节:
①. 字段准确性:新老版本数据对比,保证共有记录字段的准确性
②. 整体 - 对比总值:如果某一列值是数据类型,就纵向加和,与数据库总值进行比较;如果是非数值,统计各个取值出现的频率,跟数据库结果进行比对,保证整体的准确性。
接下来将针对字段准确性环节用到的新老版本对比的自动化脚本进行详细讲解。
对比脚本方案演进
两个 csv 文件对比,需要将一个作为基础文件(后面统称 “base 文件”),另一个作为对比文件。遍历对比文件,到 base 文件中找到对应的记录,逐一比较对应的列值。因为顺序是随机的,所以将账户 id 作为对比的 key 值,具体步骤如下:
①. 将两个 csv 文件转换成字典:将账户 id 列作为 key 值、其它列值作为 value
②. 从对比文件 dict 取出一行,获取 key
③. 去 base 文件的 dict 判断是否存在 key,如果存在,取出来,计算处理 + 对比各个列值,如果都相等,则 pass,否则,将错误信息打印出来
④. 如果上一步不存在,直接打印错误信息
电脑配置:
● windows10 操作系统
● 8 核 CPU
● 20G 内存
文件量级:20W(base 文件)VS 20W(对比文件)
1. 单进程直接写日志
为了使运行结果看起来更加直观,第一个版本设计的时候引入了 Python 的日志组件 loguru 来打印过程数据。核心代码如下:
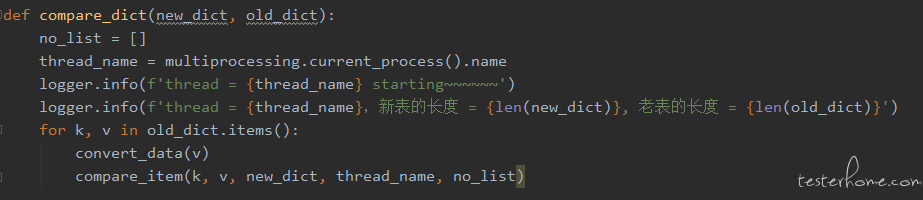
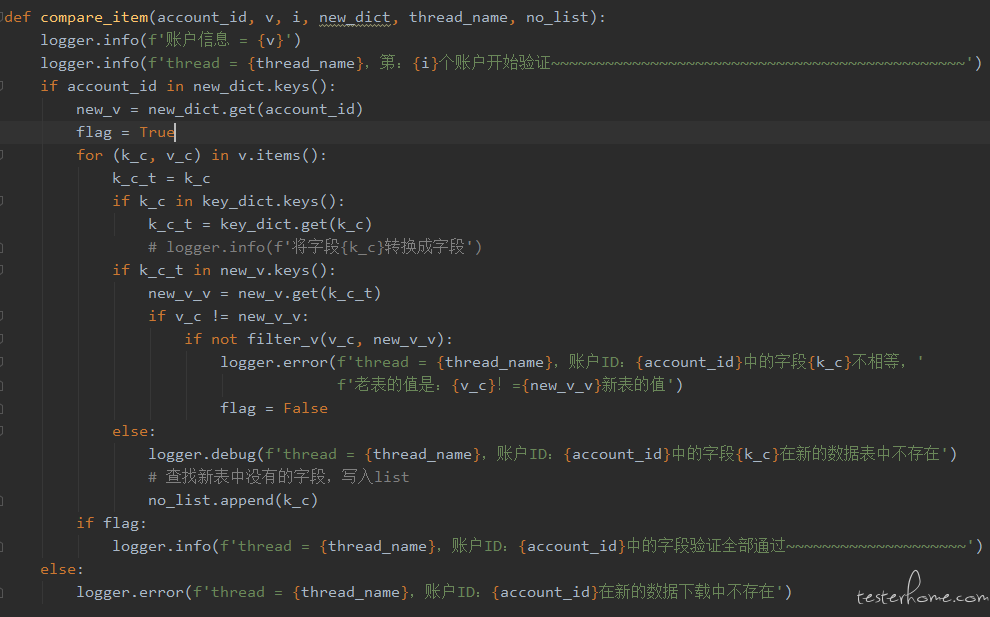
为了清楚了解循环进度以及准确定位,加了较多日志,可以看到,每个循环都会去写日志。运行结束大概需要 40 多分钟,时间略长,排查了一下发现频繁写日志文件非常影响效率,所以接下来的版本采用集中写文件替换掉了日志模块。
2. 单进程汇总写日志
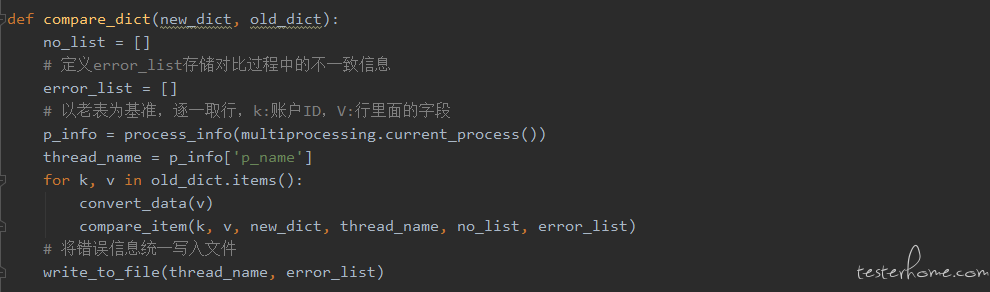
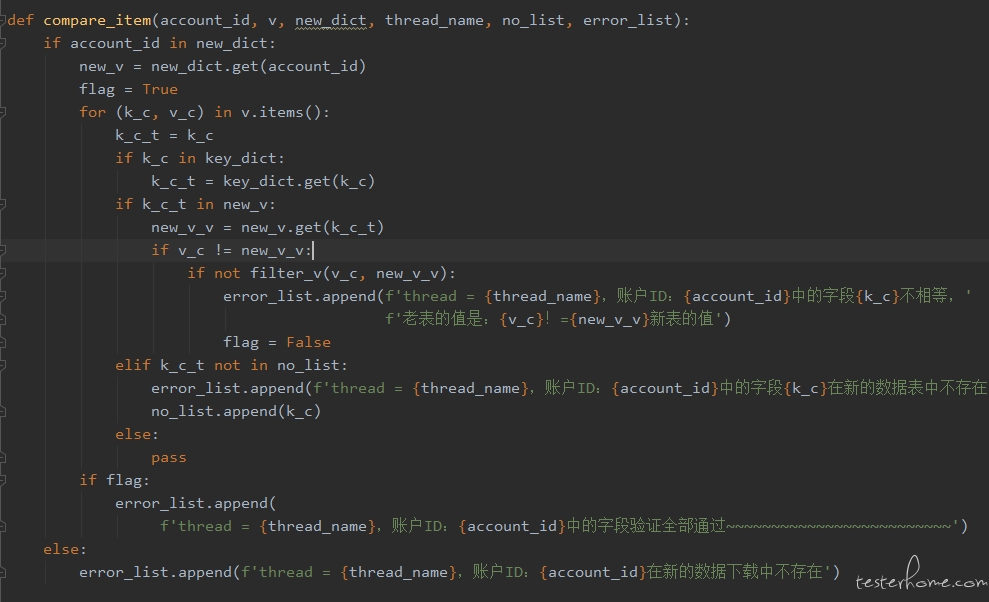
基于上一个版本的问题,做了两点改进:
①. 去掉了无用的日志输出
②. 将错误信息存储到 error_list,运行结束之后统一将 error_list 写入文件,便于查看结果
代码如下:
运行结果:

运行时间大概 20 分钟左右,运行效率翻了一倍,但是作为线上验证环节,我们还希望更快一些,接下来我们尝试一下并发策略。
3. 并发 - 汇总写日志
提到并发,就会想到线程和进程,线程与进程是操作系统里面的术语,简单来讲,每一个应用程序都有一个自己的进程。操作系统会为这些进程分配一些执行资源,例如内存空间等。在进程中,又可以创建一些线程,他们共享这些内存空间,并由操作系统调用,以便并行计算。进程是资源分配的最小单位,线程是程序执行的最小单位。相比进程,线程更加轻量,资源利用率高,且创建销毁更快。
综上所述,优先选择 Python 的多线程方案。将对比文件通过 numpy 进行分块,分发给各个线程。核心代码如下:
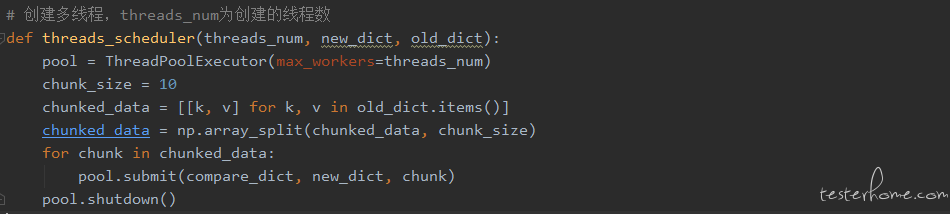
运行结果如下:
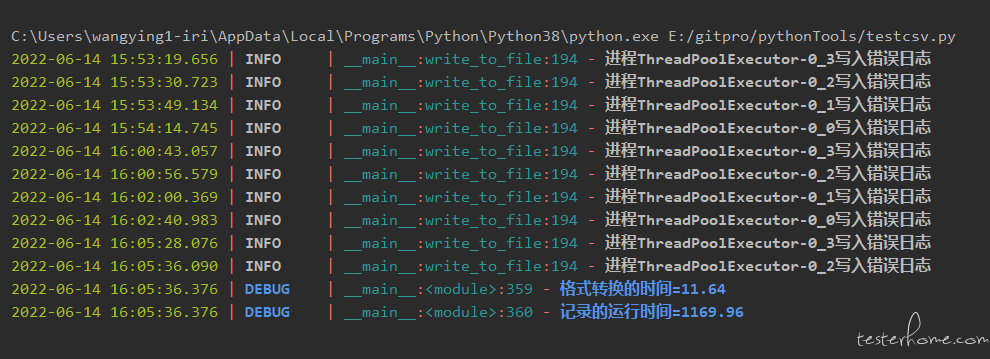
从运行结果上看,并没有明显的加速效果,原因是因为 Python 的 GIL(解释器全局锁)机制。不同线程同时访问资源时,需要使用保护机制,Python 中使用 GIL(解释器全局锁)。直观上,这是一个加在解释器上的全局(从解释器的角度看)锁。这意味着对于任何 Python 程序,不管有多少的处理器,任何时候都总是只有一个线程在执行。所以,在我们脚本几乎没有 IO 操作的情况下,python 中的多线程并没有明显的优势。
接下来我们看一下多进程的方案:
● 使用 Python 第三方库 numpy 将对比文件的 dict 进行分块
● 将分块的 dict 以及 base 文件的 dict 分发给各个进程行后续计算
代码如下:
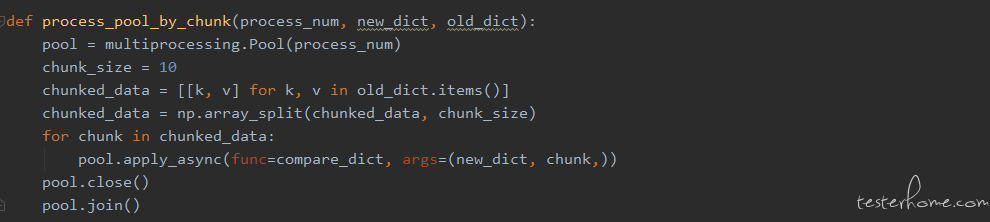
运行结果:
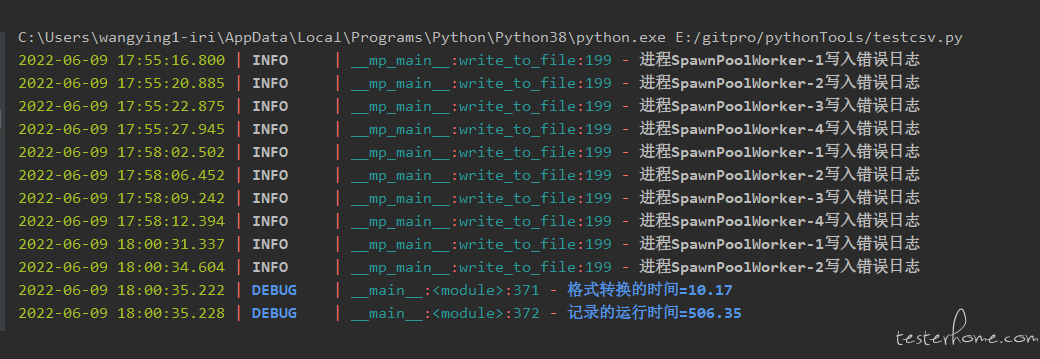
在文件大小不是特别大的情况下,加速效果明显:运行时间较之前缩短了一倍,大概 10 分钟以内就可以完成。
但并不是所有量级的文件对比都有这种加速效果。
受电脑资源的限制,当文件大小超过一定的体量以后(比如 csv100 多万条记录),每个进程都要创建自己独立的资源,进程所需内存的大小也变得很大,所以进程启动变得缓慢,甚至一个进程运行结束,另外一个进程还没有启动,效率不如预期。
4. 共享内存 - 并发 - 汇总写日志
我们看一个大文件的例子:
文件量级:100W VS 100W
单个进程运行的结果:

多进程运行的结果:
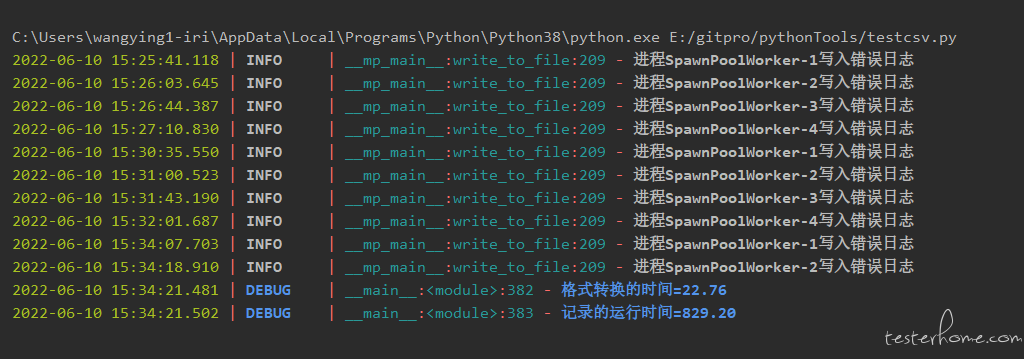
从日志结果可以看出,四个进程并没有实现并发的效果,因为 base 文件过大,每一个进程都需要为 base 文件创建所需的内存空间,进程占用内存大,导致进程启动缓慢。
为了缓解进程空间过大的问题,尝试了 Python 中共享内存的方案,因为需要共享的字典较大,所以选择了 mutiprocess 中的 Manager 类,Manager 是一种较为高级的多进程通信方式,它能支持 Python 支持的任何数据结构。
它的原理是:先启动一个 ManagerServer 进程,这个进程是阻塞的,它监听一个 socket,然后其他进程 (ManagerClient) 通过 socket 来连接到 ManagerServer,实现通信。使用了 manager 共享内存的代码如下:
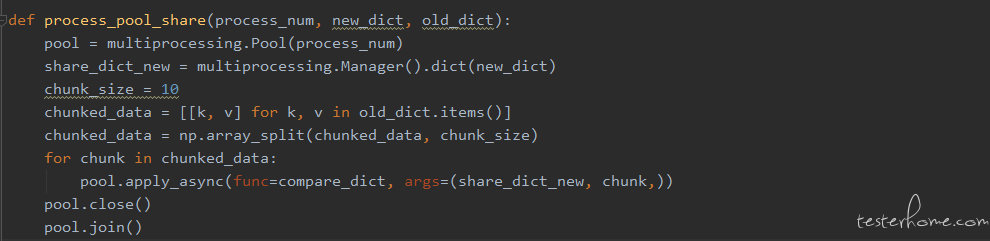
将较大的 base 文件的 dict 放入共享空间,进程无需再单独分配相关的空间,解决了资源较大的进程启动慢的问题,运行结果如下:
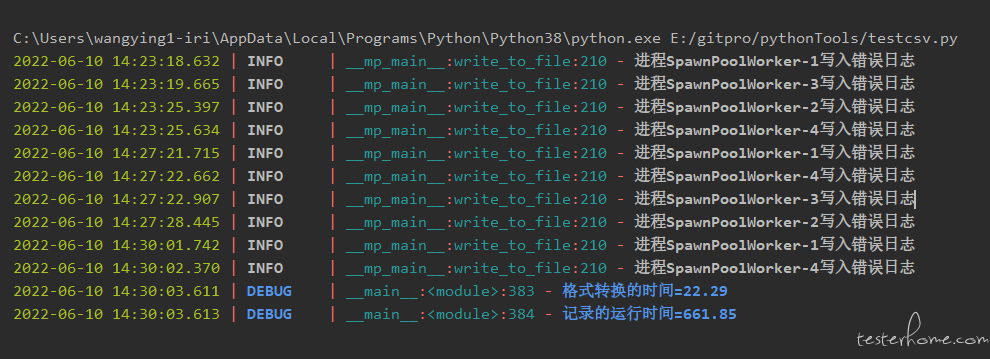
从运行结果可以看出,进程是并行启动运行的,运行效率较单进程和非共享内存的多进程都有了显著的提升。另外,这里也可以将 base 文件和对比文件同时放入共享空间,感兴趣的同学可以实践一下。
总结
● 在任务是计算密集型、小内存消耗的情况下,可以选用多进程提升运行效率
● 在任务是计算密集型、高内存消耗的情况下,可以将大块数据进行分割,如果无法分割,可以尝试共享内存的方案解决多进程启动慢的情况。
● 多进程的情况下,频繁写日志会降低程序的运行效率,采用集中写日志可以有效缓解问题。另外,日志要尽可能的精简,去除冗余。
本文主要介绍了数据下载重构项目测试计划以及效率化方面的内容,希望能给大家在日常测试中提供一些测试的思路,有不合理或者可以优化的地方欢迎交流指正。